📌 相关文章
- 机器学习中的 seq2seq 模型(1)
- 机器学习中的 seq2seq 模型
- Python保存机器学习模型
- Python保存机器学习模型(1)
- 保存机器学习模型python(1)
- 具有可教机器的机器学习模型(1)
- 具有可教机器的机器学习模型
- 保存机器学习模型python代码示例
- 保存机器学习模型 - Python 代码示例
- 机器学习 python (1)
- 保存机器学习模型
- 保存机器学习模型(1)
- 机器学习 python 代码示例
- 机器学习中的 P 值(1)
- C++中的机器学习(1)
- 机器学习中的 P 值
- C++中的机器学习
- 机器学习 (1)
- 用Python创建一个简单的机器学习模型
- 用Python创建一个简单的机器学习模型(1)
- 拆分机器学习模型的数据(1)
- 拆分机器学习模型的数据
- 学习 python 机器学习 - 任何代码示例
- 使用Python机器学习-方法
- 使用Python机器学习-方法(1)
- 创建一个简单的机器学习模型
- 如何将机器学习模型连接到 Web 应用程序 - Python (1)
- 机器学习 - 任何代码示例
- 如何将机器学习模型连接到 Web 应用程序 - Python 代码示例
📜 Python机器学习中的seq2seq模型
📅 最后修改于: 2020-04-28 01:00:42 🧑 作者: Mango
Seq2seq由Google首次引入机器翻译。在此之前,翻译工作非常幼稚。您以前键入的每个单词都被转换为其目标语言,而不考虑其语法和句子结构。Seq2seq通过深度学习彻底改变了翻译过程。它不仅在翻译时考虑了当前单词/输入,还考虑了其邻域。
如今,它可用于各种不同的应用程序,例如图像字幕,会话模型,文本摘要等。
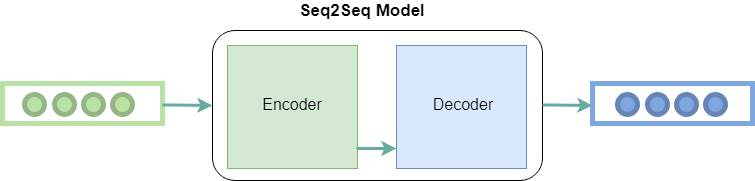
Seq2seq工作:
顾名思义,seq2seq将一个单词序列(句子或词组)作为输入,并生成一个单词输出序列。它通过使用递归神经网络(RNN)来实现。尽管很少使用RNN的原始版本,但使用了更高级的版本,即LSTM或GRU。这是因为RNN存在梯度消失的问题。Google提出的版本使用GRU。它通过在每个时间点进行两次输入来发展单词的上下文。一个来自用户,另一个来自其先前的输出,因此名称为recurrent(输出作为输入)。
它主要有两个部分,即编码器和解码器,因此有时被称为Encoder-Decoder Network。
编码器: 它使用深层神经网络层并将输入的单词转换为相应的隐藏向量。每个向量代表当前单词和该单词的上下文。
解码器: 类似于编码器。它以编码器生成的隐藏向量、其自身的隐藏状态和当前单词为输入,以生成下一个隐藏向量,并最终预测下一个单词。

除了这两个之外,许多优化还导致了seq2seq的其他组件:
- 注意:解码器的输入是单个向量,必须存储有关上下文的所有信息。这对于大序列来说是一个问题。因此,应用注意力机制,其允许解码器选择性地查看输入序列。
- 波束搜索:解码器选择最高概率词作为输出。但是,由于贪婪算法的基本问题,这并不总是能产生最佳结果。因此,应用波束搜索,建议在每个步骤可能进行平移。完成此操作后,将得到一棵具有最高k结果的树。
- 存储桶: seq2seq模型中的可变长度序列是可能的,因为对输入和输出都进行了0填充。但是,如果我们设置的最大长度为100,而句子只有3个字长,则会造成巨大的空间浪费。因此,我们使用存储桶的概念。我们制作不同大小的存储桶,例如(4,8)(8,15),依此类推,其中4是我们定义的最大输入长度,而8是定义的最大输出长度。