奥卡姆剃刀
历史上许多哲学家都提倡简约的思想。最伟大的希腊哲学家之一,亚里士多德甚至说:“自然以最短的方式运行”。因此,在给定一组具有相同描述能力的所有可能解释的情况下,人类也可能倾向于选择更简单的解释。这篇文章简要概述了奥卡姆剃刀原理、原理的相关性,并以该剃刀作为机器学习(尤其是决策树学习)中的归纳偏差的用法结束。
什么是奥卡姆剃刀?
奥卡姆剃刀是一条简约法则,俗话说(用威廉的话)“在没有必要的情况下,绝不能假设多元性”。或者,作为一种启发式方法,它可以被视为,当有多个假设来解决一个问题时,更简单的一个是首选。尚不清楚这一原则最终归于谁,但奥卡姆的威廉 (c. 1287 – 1347) 对简单性的偏爱已有详细记录。因此,这一原则被称为“奥卡姆剃刀”。这通常意味着切断或消除其他可能性或解释,因此在原则名称后附加了“剃刀”。应该指出的是,这些解释或假设应该会导致相同的结果。
奥卡姆剃刀的相关性。
有许多事件倾向于采用更简单的方法,无论是作为归纳偏差还是作为开始的约束。他们之中有一些是 :
- 像这样的研究,结果表明学龄前儿童在学习和发展的最初几年对更简单的解释很敏感。
- 科学的各个方面都倾向于采用更简单的方法和解释来实现相同的目标。例如,简约原则应用于理解进化。
- 在神学、本体论、认识论等中,这种简约的观点被用来推导出各种结论。
- 奥卡姆剃刀的变体用于知识发现。
奥卡姆剃刀作为机器学习中的归纳偏差。
- 归纳偏差(或算法的固有偏差)是由学习算法做出的假设,以形成超出训练实例集的假设或泛化,以便对未观察到的数据进行分类。
- 奥卡姆剃刀是归纳偏置最简单的例子之一。它涉及对最适合数据的更简单假设的偏好。虽然剃刀可以用来消除其他假设,但可能需要相关的理由来这样做。下面分析该原理如何应用于决策树学习。
- 决策树学习算法遵循搜索策略,在假设空间中搜索最适合训练数据的假设。例如,ID3 算法使用简单到复杂的策略,从一棵空树开始,并在信息增益启发式的指导下添加节点,以构建与训练实例一致的决策树。
计算每个属性(尚未包含在树中)的信息增益以推断哪个属性将被视为下一个节点。信息增益是ID3算法的本质。它给出了一个属性可以提供的关于目标变量的信息的定量度量,即假设只有该属性的信息可用,我们可以多有效地推断出目标。它可以定义为: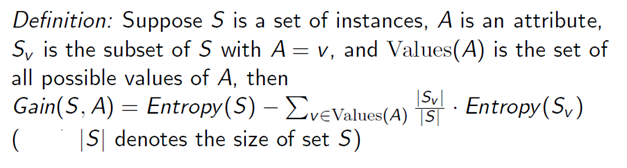
- 好吧,可以有许多决策树与给定的训练示例集一致,但 ID3 算法的归纳偏差导致偏爱更简单(或更短的树)树。 ID3 的这种偏好偏差源于搜索策略中假设的排序这一事实。这会导致额外的偏差,即属性高且更接近根的信息增益是首选。因此,算法遵循一个确定的顺序,直到它在达到与训练数据一致的假设时终止。
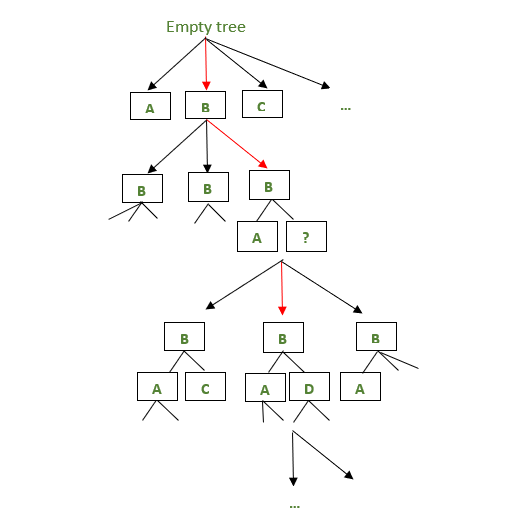
上图描述了 ID3 算法如何在每次迭代中选择节点。红色箭头描绘了在特定迭代中选择的节点,而黑色箭头表示在给定迭代中可能存在的其他决策树。
- 因此,从一个空节点开始,算法逐渐向更复杂的决策树发展,并在树足以对训练示例进行分类时停止。
- 这个例子弹出一个问题。消除复杂的假设对未观察到的实例的分类有任何影响吗?简单地说,偏好更简单的假设是否有优势?如果两棵决策树的训练错误略有不同,但验证错误相同,那么很明显会选择两者中更简单的树。由于更高的验证错误会导致数据过度拟合。复杂树的训练误差通常几乎为零,但验证误差可能很高。这种情况为偏向更简单的树提供了合理的理由。除此之外,一个更简单的假设可能在资源有限的环境中证明是有效的。
- 什么是过拟合?考虑两个假设 a 和 b。让“a”完美地拟合训练示例,而假设“b”的训练误差很小。如果在整个数据集上(即,包括未见过的实例),如果假设 'b' 表现更好,那么就说 'a' 过拟合了训练数据。为了最好地说明过度拟合的问题,请考虑下图。

图 A 和 B 描绘了两个决策边界。假设绿色和红色点代表训练样例,B 中的决策边界完美地拟合数据,从而完美地对实例进行分类,而 A 中的决策边界则不然,虽然比 B 简单。在这个例子中,B 中的决策边界过拟合数据。原因是训练数据的每个实例都会影响决策边界。增加的相关性是训练数据包含噪声时。例如,假设在图 B 中靠近边界的红点之一是噪声点。那么靠近噪声点的看不见的实例可能会被错误地分类。这使得复杂的假设容易受到数据噪声的影响。
- 虽然通过采用更简单的假设可以显着避免模型过度拟合行为的问题,但极其简单的假设可能过于抽象,无法推断出导致欠拟合的任务所需的任何信息。在我们将机器学习模型归零之前,过拟合和欠拟合是需要解决的主要挑战之一。有时可能需要一个复杂的模型,这是一个取决于可用数据、预期结果和应用程序域的选择。
注意:强烈建议阅读关于决策树介绍的文章,以通过示例深入了解决策树构建。
注意:有关决策树学习的更多信息,请参阅 Tom M. Mitchell 的“机器学习”一书。