实现分布式共享内存的算法
分布式共享内存(DSM)系统是分布式操作系统的资源管理组件,它在没有物理共享内存的分布式系统中实现共享内存模型。共享内存模型提供了一个虚拟地址空间,由分布式系统中的所有节点共享。
实施 DSM 的核心问题是:
- 如何跟踪远程数据的位置。
- 如何克服在访问远程数据的系统中执行通信协议所涉及的通信开销和延迟。
- 如何在多个节点同时访问共享数据以提高性能。
实现 DSM 的算法
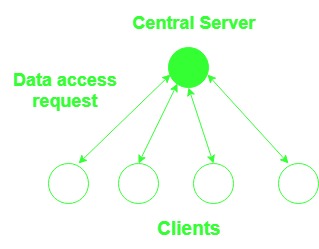
1. 中央服务器算法:
- 在这种情况下,中央服务器维护所有共享数据。它通过向其他节点返回数据项来服务来自其他节点的读取请求,并通过更新数据和返回确认消息来为写入请求提供服务。
- 超时可用于确认失败的情况,而序列号可用于避免重复写入请求。
- 实施起来更简单,但中央服务器可能会成为瓶颈,为了克服这种共享数据,可以在多个服务器之间分布。这种分布可以通过地址或通过使用映射函数来定位适当的服务器。
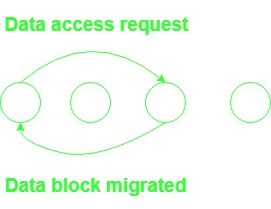
2. 迁移算法:
- 与中央服务器算法相反,在中央服务器算法中,每个数据访问请求都被转发到数据的位置,而在此数据中,数据被运送到数据访问请求的位置,从而允许在本地执行后续访问。
- 它一次只允许一个节点访问共享数据,并且包含数据项的整个块迁移而不是请求的单个项。
- 在页面频繁地在节点之间迁移而只为少数请求提供服务的情况下,它很容易受到抖动的影响。
- 该算法提供了将 DSM 与操作系统在各个节点提供的虚拟内存集成的机会。
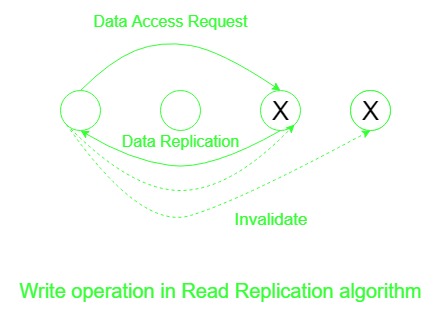
3.阅读复制算法:
- 这通过复制数据块并允许多个节点具有读访问权限或一个节点具有读写访问权限来扩展迁移算法。
- 它通过允许多个节点同时访问数据来提高系统性能。
- 这里的写操作是昂贵的,因为各个节点上共享块的所有副本都必须使当前值无效或更新,以保持共享数据块的一致性。
- DSM 必须在此跟踪所有数据块副本的位置。
4.全复制算法:
- 它是读复制算法的扩展,允许多个节点对共享数据块进行读写访问。
- 由于许多节点可以同时写入共享数据,因此必须控制对共享数据的访问以保持其一致性。
- 为了保持一致性,它可以使用无间隙序列,其中所有希望修改共享数据的节点将修改发送到排序器,然后排序器将分配一个序列号并将带有序列号的修改多播给所有拥有共享数据副本的节点物品。
