不使用不同关键字获取不同记录的 SQL 查询
在这里,我们将看到如何在不使用 DISTINCT 子句的情况下从 Microsoft SQL Server 的数据库表中检索唯一(不同)记录。
我们将在名为“geeks”的数据库中创建一个员工表。
创建数据库:
CREATE DATABASE geeks;使用数据库:
USE geeks;我们已经在我们的数据库爱好者以下dup_table表:
CREATE TABLE dup_table(
dup_id int,
dup_name varchar(20));要查看表架构,请使用以下命令:
EXEC SP_COLUMNS dup_table;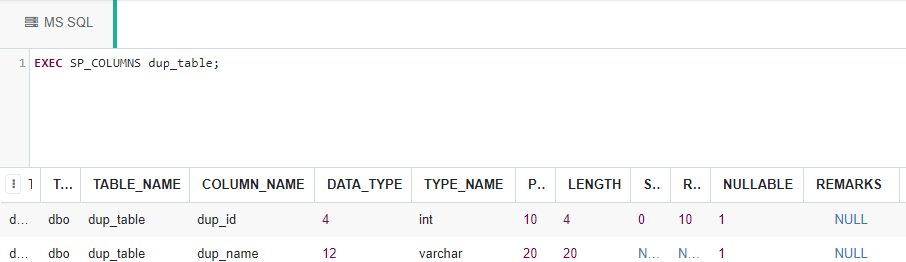
将值添加到dup_table表中:
使用以下查询向表中添加记录:
INSERT INTO dup_table
VALUES
(1, 'yogesh'),
(2, 'ashish'),
(3, 'ajit'),
(4, 'vishal'),
(3, 'ajit'),
(2, 'ashish'),
(1, 'yogesh');现在我们将从dup_table表中检索所有数据:
SELECT * FROM dup_table;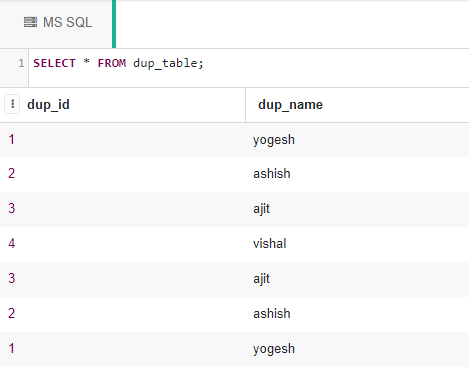
现在让我们在不使用 DISTINCT 子句的情况下检索不同的行。
通过使用 GROUP BY 子句:
GROUP BY 子句可用于查询表中的不同行:
SELECT dup_id, dup_name FROM dup_table
GROUP BY dup_id, dup_name;
通过使用set UNION运算符:
set UNION运算符还可用于查询表中的不同行:
SELECT dup_id, dup_name FROM dup_table
UNION
SELECT dup_id, dup_name FROM dup_table;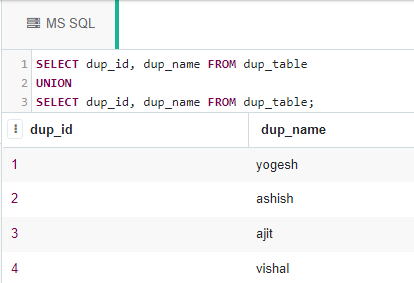
通过使用 set INTERSECT运算符:
INTERSECT运算符可用于查询表中的不同行:
SELECT dup_id, dup_name FROM dup_table
INTERSECT
SELECT dup_id, dup_name FROM dup_table;
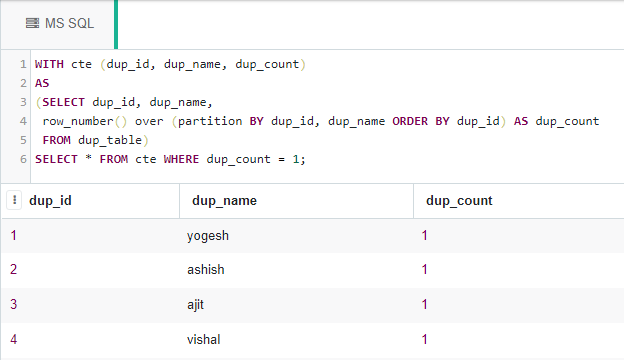
通过使用 CTE 和 row_number()函数:
CTE 代表通用表表达式。它还可以使用 row_number()函数查询表中的不同行,如下所示:
WITH cte (dup_id, dup_name, dup_count)
AS
(SELECT dup_id, dup_name,
row_number() over (partition BY dup_id,
dup_name ORDER BY dup_id) AS dup_count
FROM dup_table)
SELECT * FROM cte WHERE dup_count = 1;