在机器学习中,我们通常处理的数据集在一列或多列中包含多个标签。这些标签可以是单词或数字的形式。为了使数据易于理解或以人类可读的形式,训练数据通常以文字标记。
标签编码是指将标签转换为数字形式,以便将其转换为机器可读形式。然后,机器学习算法可以更好地决定必须如何操作这些标签。对于监督学习而言,这是结构化数据集的重要预处理步骤。
例子 :
假设我们在某些数据集中有一个“高度”列。 
应用标签编码后,“高度”列将转换为: 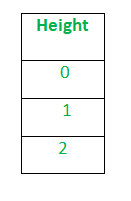
其中0是高大的标签,1是中高的标签,2是短高的标签。
我们在“物种”目标列上的iris dataset上应用“标签编码”。它包含三个物种:鸢尾,鸢尾,杂色,鸢尾。
# Import libraries
import numpy as np
import pandas as pd
# Import dataset
df = pd.read_csv('../../data/Iris.csv')
df['species'].unique()
输出:
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)应用标签编码后–
# Import label encoder
from sklearn import preprocessing
# label_encoder object knows how to understand word labels.
label_encoder = preprocessing.LabelEncoder()
# Encode labels in column 'species'.
df['species']= label_encoder.fit_transform(df['species'])
df['species'].unique()
输出:
array([0, 1, 2], dtype=int64)
标签编码的局限性
标签编码以机器可读的形式转换数据,但是它为每个数据类别分配一个唯一的数字(从0开始)。这可能会导致在训练数据集时出现优先级问题。具有高值的标签可以被认为具有比具有低值的标签更高的优先级。
例子
具有输出类墨西哥,巴黎,迪拜的属性。在“标签编码此列”上,将mexico替换为0 ,将paris替换为1 ,将dubai替换为2。
以此可以解释,在训练模型时,迪拜比墨西哥和巴黎具有更高的优先权,但是实际上这些城市之间没有这种优先权关系。