在全文搜索方面, Elasticsearch在该镇一直是一个很酷的孩子。像Uber,Slack,Udemy等许多公司都使用它进行搜索。 Elasticsearch不仅具有全文搜索之类的功能,还具有许多其他优点,例如强大的工具,可轻松分析数据以进行缩放。我们生活在一个数据像任何事物一样流动的时代,系统中的数据经常随需求而变化。我们可能会遇到需要更新或修改数据的情况。
在本文中,我们将按以下方式更新Elasticsearch中的文档:
- 在所有记录中添加一个新字段。
- 根据条件更新字段。
- 根据条件添加字段。
- 删除一个字段。
- 除去条件上的字段。
为了更新数据,我们将使用专门为无痛Elasticsearch设计的脚本语言。
为了执行上述操作,我们将使用Kibana。
1.创建索引
要插入和更新数据,首先,我们必须创建一个索引,我们将在该索引上进行所有操作。为此,请遵循以下语句:
Syntax : PUT /employee上面的查询将创建一个空索引(称为employee)。成功创建索引后,我们将在员工索引中插入一些记录。

2.插入数据。
在插入数据之前,让我们看一下文档的结构。以下是文档的字段和字段类型。
# sample fields and field types
{
"id":"number",
"firstName":"string",
"lastName":"string",
"address":[
{
"Street":"string",
"City":"string",
"State":"string"
},
{
"Street":"string",
"City":"string",
"State":"string"
}
],
"email":"string"
}我们还可以使用以下查询插入一条记录:
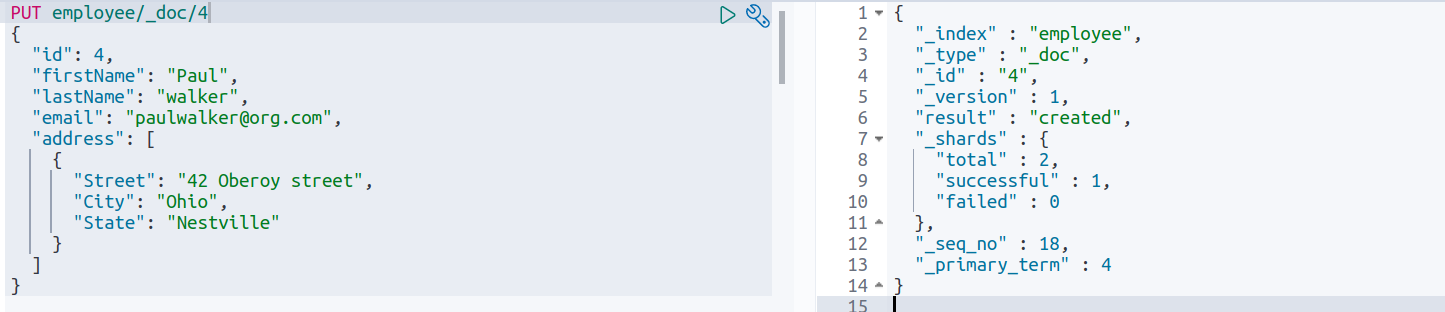
PUT employee/_doc/4
{
"id": 4,
"firstName": "Paul",
"lastName": "walker",
"email": "paulwalker@org.com",
"address": [
{
"Street": "42 Oberoy street",
"City": "Ohio",
"State": "Nestville"
}
]
}输出:
3.批量插入数据:
下面的查询对索引执行批量插入操作。成功插入数据后,将插入下面的三个记录,让我们检查一下到目前为止。
Bulk Insert (use autoindent option to indent query)
POST _bulk
{"create":{"_index":"employee","_id":"1"}}
{"id":1,"firstName":"Alice","lastName":"White","email":"alicewhite@org.com",
"address":[{"Street":"2446 McDowell Street","City":"Palmyra","State":"Tennessee"},{"Street":"4809 Blackwell Street","City":"Dry Creek","State":"Alaska"}]}
{"create":{"_index":"employee","_id":"2"}}
{"id":2,"firstName":"Andrew","lastName":"Dunn","email":"andrewdunn@org.com",
"address":[{"Street":"101 Ramsgate Rd","City":"Wildboarclough","State":"Alaska"}]}
{"create":{"_index":"employee","_id":"3"}}
{"id":3,"firstName":"Louis","lastName":"Hale","email":"louishale@org.com",
"address":[{"Street":"84 Main St","City":"Archamore","State":"Las Vegas"}]}输出:

4.提取记录
以下查询用于从指定的index( employee )获取数据。我们将获得插入的记录(3条记录):
GET employee/_search输出:

5.在所有记录中添加一个新字段。
我们忘记在员工记录中添加角色字段。怎么办?我们是否必须删除所有记录并添加带有角色字段的记录?我们不必这样做。我们将在所有记录中仅添加一个字段。
让我们添加一个新的字段角色,其值为emp 。以下查询将在我们所有的文档中添加一个新字段:
POST /employee/_update_by_query/
{
"script": "ctx._source.role = 'emp'"
}输出:

添加一个新字段后,很显然,我们文档的结构将被更改。这是添加新字段后的修订结构。
{
"id":"number",
"firstName":"string",
"lastName":"string",
"address":[
{
"Street":"string",
"City":"string",
"State":"string"
},
{
"Street":"string",
"City":"string",
"State":"string"
}
],
"email":"string",
"role":"string"
}6.根据条件更新字段值。
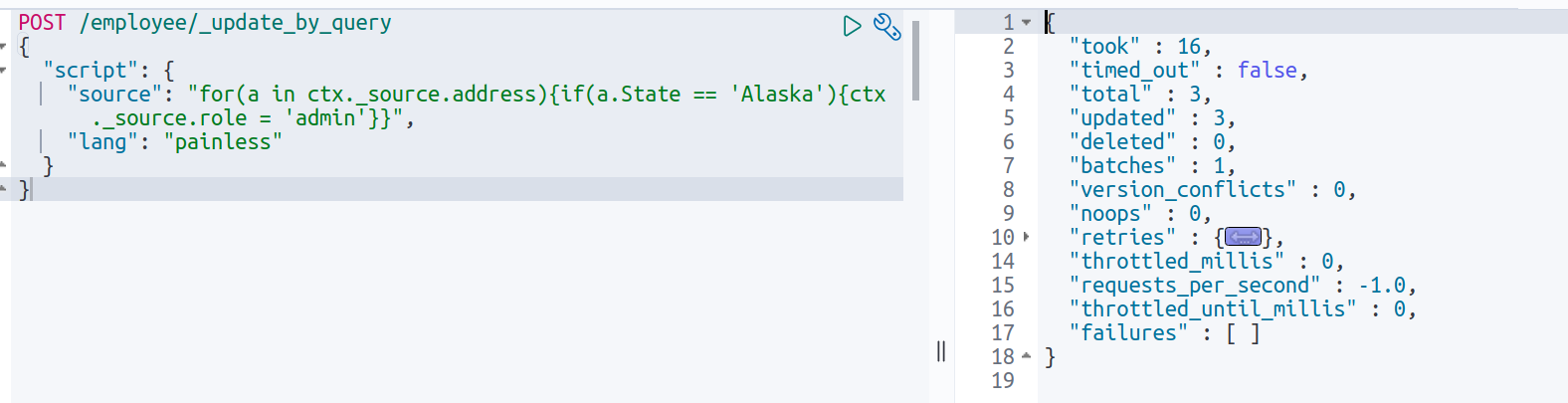
现在,不必所有员工都扮演相同的角色。他们中的一些人是管理员或经理等。比方说,我们遇到一种情况,我们希望根据某种条件来更改某些员工的角色。以下查询将更改至少一个地址中处于阿拉斯加州的雇员的角色。我们遍历了employee对象的所有地址数组,并检查状态是否为阿拉斯加,如果状态为真,则将角色设置为管理员。
POST /employee/_update_by_query
{
"script": {
"source": "for(a in ctx._source.address){if(a.State == 'Alaska'){ctx._source.role = 'admin'}}",
"lang": "painless"
}
}输出:
7.根据条件添加一个字段。
查询编号4,我们在所有记录中添加了角色字段。但是,我们不想在所有文档中都将字段值设置为相同。现在,要在某些记录中添加不同的值,将需要一些条件来决定要设置什么?让我们根据角色的值再添加一个字段isAdmin 。如果角色为admin,则将isAdmin设置为true,否则设置为false。
POST /employee/_update_by_query
{
"script": {
"source": "if(ctx._source.role == 'admin'){ctx._source.isAdmin = true} else{ctx._source.isAdmin = false}",
"lang": "painless"
}
}在这里,我们正在检查简单的if / else条件。如果角色为admin,则上面的查询会将isAdmin设置为true,否则为false。
输出:

再次添加新字段后,架构也会更改,
{
"id":"number",
"firstName":"string",
"lastName":"string",
"address":[
{
"Street":"string",
"City":"string",
"State":"string"
},
{
"Street":"string",
"City":"string",
"State":"string"
}
],
"email":"string",
"role":"string",
"isAdmin":"boolean"
}8.重命名一个字段
我们人类经常会犯一些错误,而错别字通常会导致生产下降。但更重要的是使系统恢复正常。假设我们在代码中的地址数组中引用状态,但是我们的记录具有State ,这会产生错误。现在,我们要从State-> state更改字段名称。
让我们重命名地址数组中的字段。状态到地址状态。有时会发生,我们在字段名称中插入带有错字的数据,将使用以下查询来修复错字,并重命名键:
POST /employee/_update_by_query
{
"script": {
"source": "for(a in ctx._source.address){a.state = a.State; a.remove('State')}",
"lang": "painless"
}
}在上面的查询中,我们将State的值分配给state ,然后从所有记录的数组的所有元素中删除State字段。
输出:

9.从所有记录中删除一个字段。
数据每天都在变大,因此存储成本很高。作为开发人员,我们只应存储必需的内容,因此删除经常会导致差异或不合规定的不必要字段变得至关重要。让我们从所有记录中删除角色字段:
POST /employee/_update_by_query
{
"script": {
"source": "ctx._source.remove('role')",
"lang": "painless"
}
}删除函数接受要删除的字段名称。上面的查询从所有记录中删除了角色字段。
输出:

删除该字段后,我们留下以下架构,
{
"id":"number",
"firstName":"string",
"lastName":"string",
"address":[
{
"Street":"string",
"City":"string",
"State":"string"
},
{
"Street":"string",
"City":"string",
"State":"string"
}
],
"email":"string",
"isAdmin":"boolean"
}添加,更新,删除,获取操作是任何系统的关键。这些操作用于开发人员的日常工作。