先修课程:强化学习
简短地讲,强化学习是一种学习过程的范例,其中学习代理通过在环境中不断交互来学习加班,以在特定环境中表现最佳。主体在学习过程中会经历所处环境中的各种不同情况。这些情况称为状态。处于该状态的代理可以从一组允许的操作中进行选择,这些操作可以获取不同的奖励(或惩罚)。学习代理人加班学习使这些奖励最大化,以便在其处于任何给定状态时表现最佳。
Q学习是强化学习的一种基本形式,它使用Q值(也称为动作值)来迭代地改善学习代理的行为。
- Q值或动作值: Q值是为状态和动作定义的。
 估计采取该行动有多好
估计采取该行动有多好 在该州
在该州 。这个估计
。这个估计 将使用TD-Update规则进行迭代计算,我们将在接下来的部分中看到该规则。
将使用TD-Update规则进行迭代计算,我们将在接下来的部分中看到该规则。 - 奖励和情节:代理在其整个生命周期中都从开始状态开始,并根据其选择的操作以及代理所交互的环境从当前状态到下一个状态进行多次转换。在过渡过程中,一个州的主体采取行动,从环境中观察到回报,然后过渡到另一个州。如果代理在任何时间点以一种终止状态结束,则意味着没有进一步的过渡可能。据说这是一个情节的完成。
- 时差或TD更新:
时间差异或TD更新规则可以表示如下:
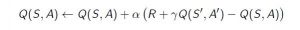
代理与环境交互的每个时间步骤都会应用此更新规则(用于估计Q值)。所用术语解释如下。 :
 :代理的当前状态。
:代理的当前状态。  :当前操作已根据某些政策选择。
:当前操作已根据某些政策选择。  :下一个州代表代理的结局。
:下一个州代表代理的结局。  :使用当前Q值估计来选择下一个最佳动作,即,在下一个状态中选择具有最大Q值的动作。
:使用当前Q值估计来选择下一个最佳动作,即,在下一个状态中选择具有最大Q值的动作。  :从环境中观察到的“当前奖励”是“当前操作的响应”。
:从环境中观察到的“当前奖励”是“当前操作的响应”。  (> 0和<= 1):未来奖励的折现因子。未来的重制不如当前的奖励有价值,因此必须予以打折。由于Q值是对某个州的预期回报的估计,因此折现规则也适用于此。
(> 0和<= 1):未来奖励的折现因子。未来的重制不如当前的奖励有价值,因此必须予以打折。由于Q值是对某个州的预期回报的估计,因此折现规则也适用于此。  :更新Q(S,A)估算值所采用的步长。
:更新Q(S,A)估算值所采用的步长。
- 选择要使用的操作
 -贪婪政策:
-贪婪政策:
 -greedy policy of是使用当前Q值估计来选择动作的非常简单的策略。它如下:
-greedy policy of是使用当前Q值估计来选择动作的非常简单的策略。它如下:- 很有可能
 选择具有最高Q值的操作。
选择具有最高Q值的操作。 - 很有可能
 随机选择任何动作。
随机选择任何动作。
现在,掌握所有必需的理论,让我们举一个例子。我们将使用OpenAI的体育馆环境来训练我们的Q学习模型。
安装
gym命令–pip install gym在开始示例之前,您将需要一些帮助程序代码以可视化算法的工作。在工作目录中将需要下载两个帮助文件。可以在这里找到文件。
步骤1:导入所需的库。
import gym import itertools import matplotlib import matplotlib.style import numpy as np import pandas as pd import sys from collections import defaultdict from windy_gridworld import WindyGridworldEnv import plotting matplotlib.style.use('ggplot')步骤2:创建健身环境。
env = WindyGridworldEnv()步骤#3:
 -贪婪的政策。
-贪婪的政策。 def createEpsilonGreedyPolicy(Q, epsilon, num_actions): """ Creates an epsilon-greedy policy based on a given Q-function and epsilon. Returns a function that takes the state as an input and returns the probabilities for each action in the form of a numpy array of length of the action space(set of possible actions). """ def policyFunction(state): Action_probabilities = np.ones(num_actions, dtype = float) * epsilon / num_actions best_action = np.argmax(Q[state]) Action_probabilities[best_action] += (1.0 - epsilon) return Action_probabilities return policyFunction步骤#4:建立Q学习模型。
def qLearning(env, num_episodes, discount_factor = 1.0, alpha = 0.6, epsilon = 0.1): """ Q-Learning algorithm: Off-policy TD control. Finds the optimal greedy policy while improving following an epsilon-greedy policy""" # Action value function # A nested dictionary that maps # state -> (action -> action-value). Q = defaultdict(lambda: np.zeros(env.action_space.n)) # Keeps track of useful statistics stats = plotting.EpisodeStats( episode_lengths = np.zeros(num_episodes), episode_rewards = np.zeros(num_episodes)) # Create an epsilon greedy policy function # appropriately for environment action space policy = createEpsilonGreedyPolicy(Q, epsilon, env.action_space.n) # For every episode for ith_episode in range(num_episodes): # Reset the environment and pick the first action state = env.reset() for t in itertools.count(): # get probabilities of all actions from current state action_probabilities = policy(state) # choose action according to # the probability distribution action = np.random.choice(np.arange( len(action_probabilities)), p = action_probabilities) # take action and get reward, transit to next state next_state, reward, done, _ = env.step(action) # Update statistics stats.episode_rewards[ith_episode] += reward stats.episode_lengths[ith_episode] = t # TD Update best_next_action = np.argmax(Q[next_state]) td_target = reward + discount_factor * Q[next_state][best_next_action] td_delta = td_target - Q[state][action] Q[state][action] += alpha * td_delta # done is True if episode terminated if done: break state = next_state return Q, stats步骤#5:训练模型。
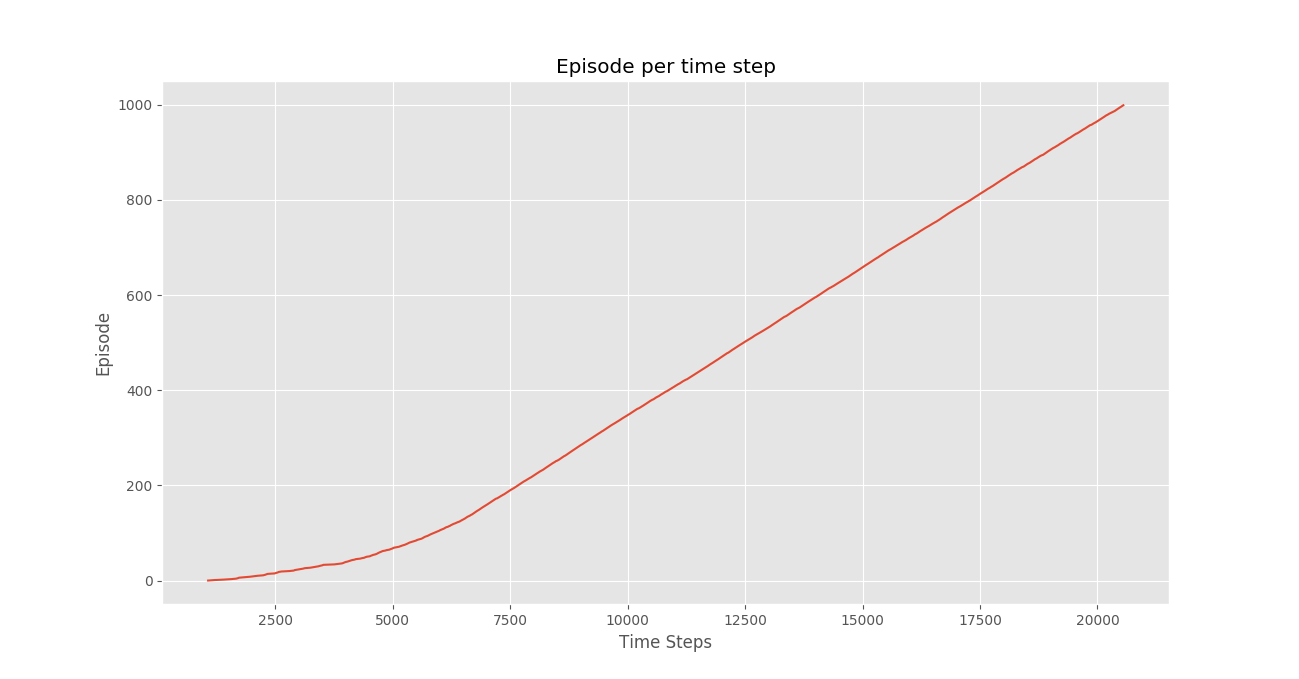
Q, stats = qLearning(env, 1000)步骤#6:绘制重要统计数据。
plotting.plot_episode_stats(stats)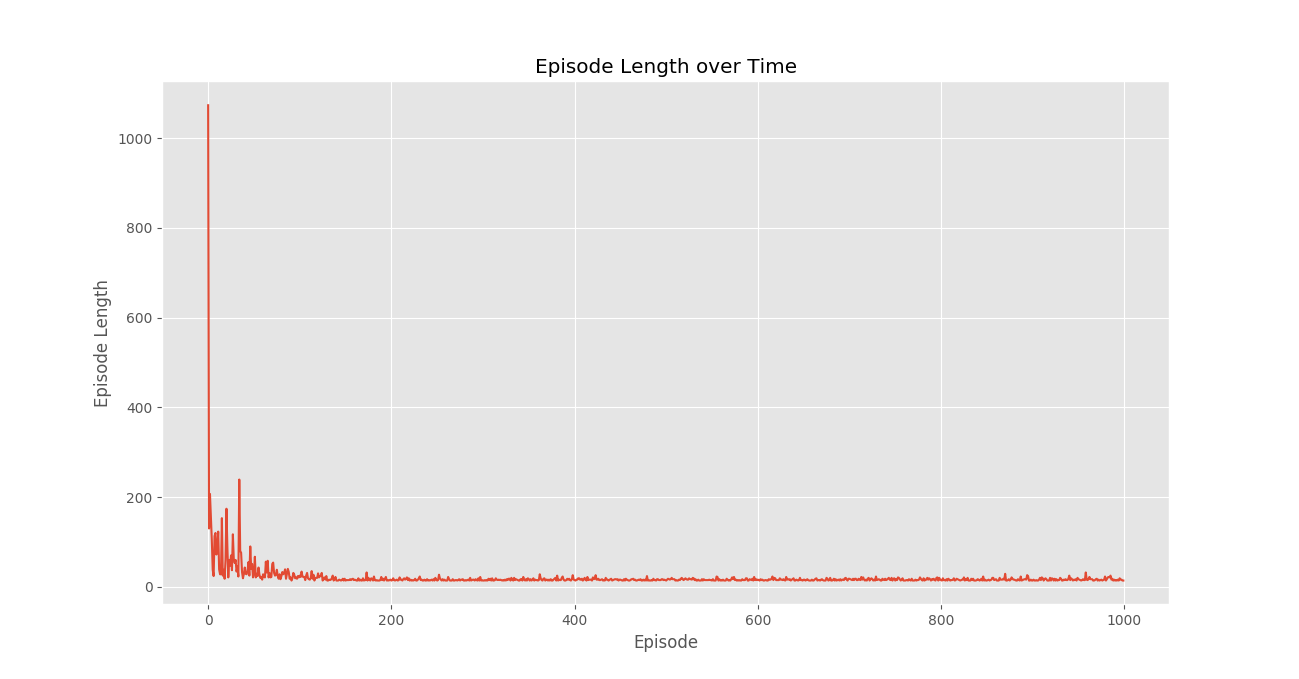

结论:
我们看到,在情节奖励随时间变化的情节中,情节奖励随着时间的推移逐渐增加,并最终以每个情节的高奖励逐渐变平,这表明代理已学会通过在每个情节中表现最佳来最大化其在总情节中获得的总奖励。状态。 - 很有可能