在机器学习中,我们无法将模型拟合到训练数据上,也不能说模型可以对实际数据准确地工作。为此,我们必须确保我们的模型从数据中获得了正确的模式,并且不会产生过多的噪声。为此,我们使用交叉验证技术。
交叉验证
交叉验证是一种技术,其中我们使用数据集的子集训练模型,然后使用数据集的互补子集进行评估。
交叉验证涉及的三个步骤如下:
- 保留部分样本数据集。
- 使用其余的数据集训练模型。
- 使用数据集的备用部分测试模型。
交叉验证方法
验证
在这种方法中,我们对给定数据集的50%进行训练,剩下的50%用于测试目的。这种方法的主要缺点是我们对50%的数据集进行训练,而剩下的50%的数据可能包含一些我们在训练模型时留下的重要信息,即较高的偏差。
LOOCV(留出一个交叉验证)
在这种方法中,我们对整个数据集进行训练,但是只留下可用数据集的一个数据点,然后针对每个数据点进行迭代。它既有优点也有缺点。
使用此方法的优点是我们利用了所有数据点,因此它具有低偏差。
这种方法的主要缺点是,当我们针对一个数据点进行测试时,它会导致测试模型的变化更大。如果数据点是异常值,则可能导致更大的变化。另一个缺点是,由于要遍历“数据点数”次,因此需要大量执行时间。
K折交叉验证
在这种方法中,我们将数据集划分为k个子集(称为折叠),然后对所有子集执行训练,但保留一个(k-1)个子集用于评估训练后的模型。在这种方法中,我们每次使用保留用于测试目的的不同子集进行k次迭代。
Note:
It is always suggested that the value of k should be 10 as the lower value
of k is takes towards validation and higher value of k leads to LOOCV method.
例子
下图显示了以k倍交叉验证生成的训练子集和评估子集的示例。在这里,我们总共有25个实例。在第一个迭代中,我们将前20%的数据用于评估,将其余80%的数据用于培训([1-5]测试和[5-25]训练),而在第二个迭代中,我们将第二个子集(20%)用于评估评估,剩下的三个数据子集用于训练([5-10]测试以及[1-5和10-25]训练),依此类推。
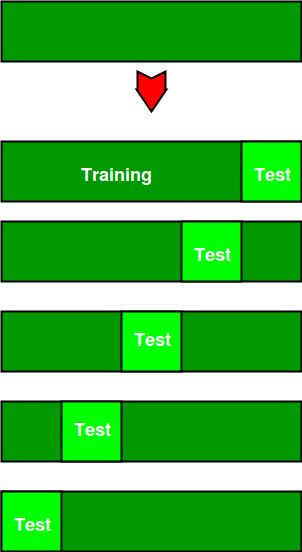
Total instances: 25
Value of k : 5
No. Iteration Training set observations Testing set observations
1 [ 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4]
2 [ 0 1 2 3 4 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [5 6 7 8 9]
3 [ 0 1 2 3 4 5 6 7 8 9 15 16 17 18 19 20 21 22 23 24] [10 11 12 13 14]
4 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 20 21 22 23 24] [15 16 17 18 19]
5 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24]
训练/测试拆分与交叉验证的比较
火车/测试拆分的优势:
- 这比“单打独斗”交叉验证快K倍,因为K折交叉验证重复训练/测试拆分K次。
- 更简单地检查测试过程的详细结果。
交叉验证的优点:
- 样本外准确性的更准确估计。
- 由于每个观察都用于训练和测试,因此可以更“有效”地使用数据。
用于k折交叉验证的Python代码。
# This code may not be run on GFG IDE
# as required packages are not found.
# importing cross-validation from sklearn package.
from sklearn import cross_validation
# value of K is 10.
data = cross_validation.KFold(len(train_set), n_folds=10, indices=False)
参考: https : //www.analyticsvidhya.com/blog/2015/11/improve-model-performance-cross-validation-in-python-r/