机器学习中的 Bagging 与 Boosting
众所周知,集成学习通过组合多个模型来帮助提高机器学习结果。与单个模型相比,这种方法允许产生更好的预测性能。基本思想是学习一组分类器(专家)并让他们投票。 Bagging和Boosting是集成学习的两种类型。这两个减少了单个估计的方差,因为它们结合了来自不同模型的多个估计。所以结果可能是一个稳定性更高的模型。让我们一目了然地理解这两个术语。
- Bagging :它是一种同构弱学习器模型,它们相互独立并行学习,并将它们组合起来以确定模型平均值。
- Boosting :它也是一个同构的弱学习器模型,但与 Bagging 的工作方式不同。在这个模型中,学习者顺序地、自适应地学习,以改进学习算法的模型预测。
让我们详细看一下它们,并了解 Bagging 和 Boosting 之间的区别。
装袋
乙ootstrap甲ggregating,还知道作为装袋,是机器学习合奏元算法旨在改善在统计分类和回归使用机器学习算法的稳定性和精度。它减少了方差并有助于避免过度拟合。它通常应用于决策树方法。 Bagging 是模型平均方法的一个特例。
技术说明
假设有 d 个元组的集合 D,在每次迭代 i 时,d 个元组的训练集 D i被采样,并从 D 中替换(即引导)。然后为每个训练集 D < i 学习分类器模型 Mi。每个分类器 M i返回其类别预测。袋装分类器 M* 对投票进行计数,并将投票最多的类分配给 X(未知样本)。
Bagging的实现步骤
- 步骤 1:从具有相等元组的原始数据集中创建多个子集,选择有替换的观测值。
- 第 2 步:在每个子集上创建一个基本模型。
- 第 3 步:从每个训练集中并行学习每个模型,并且彼此独立。
- 第 4 步:通过组合所有模型的预测来确定最终预测。
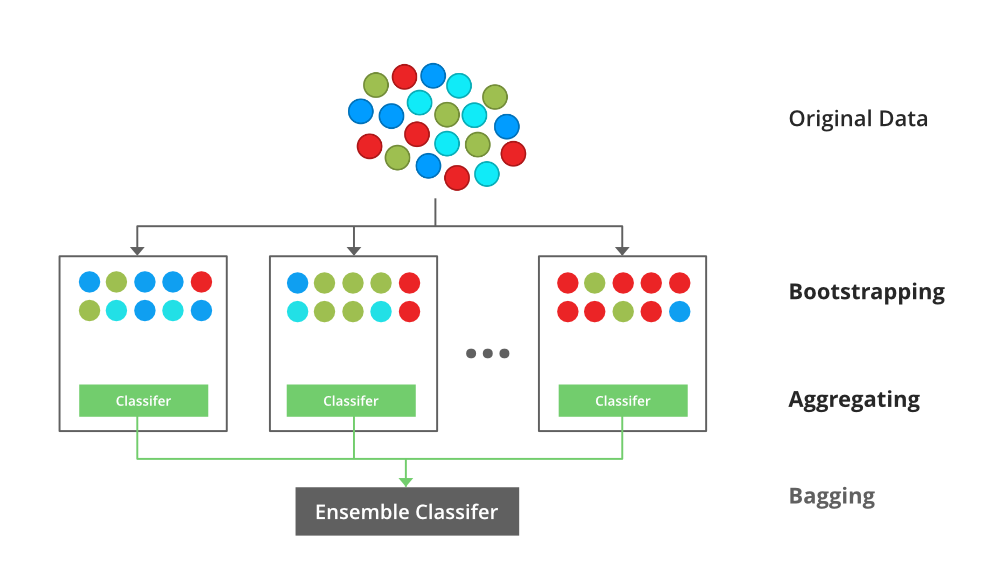
自举聚合(Bagging)概念的说明
装袋示例
随机森林模型使用 Bagging,其中存在具有更高方差的决策树模型。它进行随机特征选择来种植树木。几个随机树组成了一个随机森林。
要阅读更多内容,请参阅这篇文章: Bagging 分类器
提升
Boosting 是一种集成建模技术,它试图从弱分类器的数量中构建一个强分类器。它是通过使用串联的弱模型构建模型来完成的。首先,根据训练数据建立模型。然后构建第二个模型,试图纠正第一个模型中存在的错误。继续此过程并添加模型,直到正确预测了完整的训练数据集或添加了最大数量的模型。
提升算法
有几种增强算法。最初由Robert Schapire和Yoav Freund提出的方法不是自适应的,不能充分利用弱学习器。 Schapire 和 Freund 随后开发了 AdaBoost,这是一种自适应提升算法,赢得了著名的哥德尔奖。 AdaBoost 是第一个真正成功的提升算法,用于二进制分类。 AdaBoost 是 Adaptive Boosting 的缩写,是一种非常流行的提升技术,它将多个“弱分类器”组合成一个“强分类器”。
Algorithm:
- Initialise the dataset and assign equal weight to each of the data point.
- Provide this as input to the model and identify the wrongly classified data points.
- Increase the weight of the wrongly classified data points.
- if (got required results)
Goto step 5
else
Goto step 2 - End

展示提升算法背后直觉的插图,由并行学习器和加权数据集组成。
要阅读更多内容,请参阅本文:机器学习中的Boosting 和 AdaBoost
Bagging 和 Boosting 的相似之处
Bagging 和 Boosting 都是常用的方法,具有被归类为集成方法的普遍相似性。在这里,我们将解释它们之间的相似之处。
- 两者都是从 1 个学习器中获取 N 个学习器的集成方法。
- 两者都通过随机抽样生成多个训练数据集。
- 两者都通过平均 N 个学习者(或采取其中的大多数,即多数投票)来做出最终决定。
- 两者都擅长减少方差并提供更高的稳定性。
Bagging 和 Boosting 的区别
S.NO | Bagging | Boosting |
|---|---|---|
| 1. | The simplest way of combining predictions that belong to the same type. | A way of combining predictions that belong to the different types. |
| 2. | Aim to decrease variance, not bias. | Aim to decrease bias, not variance. |
| 3. | Each model receives equal weight. | Models are weighted according to their performance. |
| 4. | Each model is built independently. | New models are influenced by the performance of previously built models. |
| 5. | Different training data subsets are randomly drawn with replacement from the entire training dataset. | Every new subset contains the elements that were misclassified by previous models. |
| 6. | Bagging tries to solve the over-fitting problem. | Boosting tries to reduce bias. |
| 7. | If the classifier is unstable (high variance), then apply bagging. | If the classifier is stable and simple (high bias) the apply boosting. |
| 8. | Example: The Random forest model uses Bagging. | Example: The AdaBoost uses Boosting techniques |