协同过滤——机器学习
在协同过滤中,我们倾向于寻找相似的用户并推荐相似的用户喜欢的东西。在这种类型的推荐系统中,我们不使用物品的特征来推荐它,而是将用户分类到相似类型的集群中,并根据每个用户对集群的偏好进行推荐。
测量相似度:
电影推荐系统的一个简单示例将帮助我们解释:
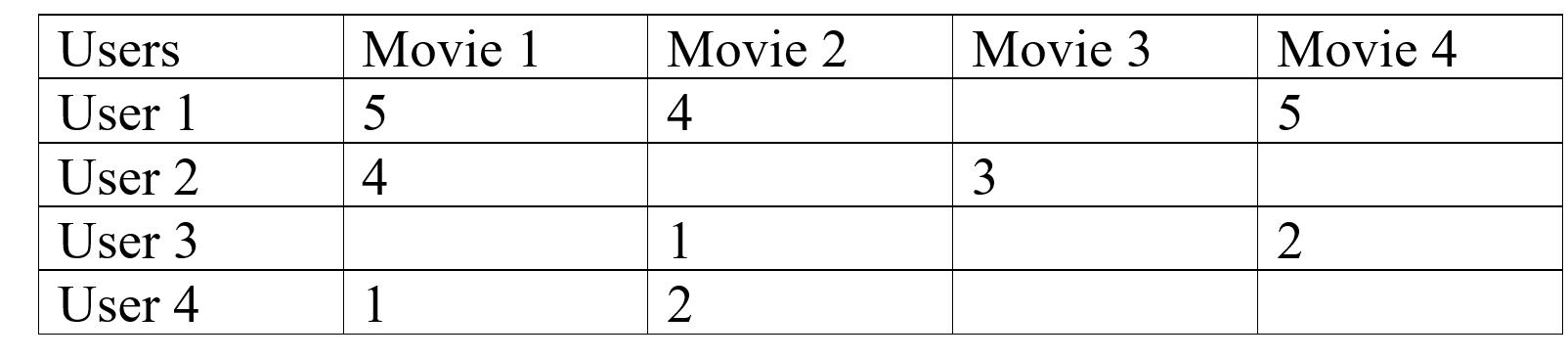
在这种类型的场景中,我们可以看到用户 1 和用户 2 对电影给出了几乎相似的评分,因此我们可以得出结论,用户 1 也将平均喜欢电影 3,但电影 4 将是一个很好的推荐给用户2,这样我们也可以看到有用户有不同的选择,比如用户1和用户3是对立的。
可以看到用户 3 和用户 4 对电影有共同的兴趣,在此基础上我们可以说电影 4 也会被用户 4 不喜欢。这就是协同过滤,我们向用户推荐喜欢的项目由具有相似兴趣域的用户组成。
余弦距离:
我们也可以利用用户之间的余弦距离来找出兴趣相似的用户,余弦越大意味着两个用户之间的夹角越小,因此他们有相似的兴趣。
我们可以在效用矩阵中应用两个用户之间的余弦距离,也可以将所有未填充的列都赋予零值以方便计算,如果我们得到较小的余弦,则用户之间的距离会更大,如果余弦越大,我们与用户之间的夹角就越小,我们可以向他们推荐类似的东西。
四舍五入数据:
在协同过滤中,我们对数据进行四舍五入以更轻松地进行比较,就像我们可以将低于 3 的评分指定为 0,将高于它的评分指定为 1,这将有助于我们更轻松地比较数据,例如:
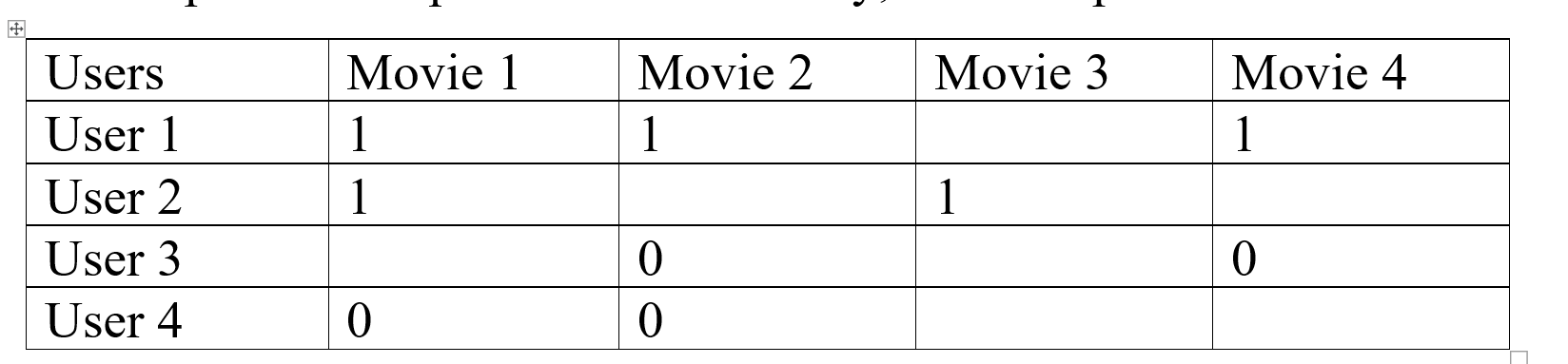
我们再次以前面的例子为例,我们应用了四舍五入的过程,你可以看到执行这个过程后数据变得可读了多少,我们可以看到用户 1 和用户 2 更相似,用户 3 和用户 4 更相似一样。
标准化评级:
在归一化过程中,我们取用户的平均评分并从中减去所有给定的评分,因此我们将得到正值或负值作为评分,这可以简单地进一步分类为相似的组。通过对数据进行标准化,我们可以创建对相似项目给出相似评分的用户集群,然后我们可以使用这些集群向用户推荐项目。