在 Pandas 数据框中对分类变量进行分组
首先,我们必须了解 pandas 中的分类变量是什么。分类是Python的 pandas 库中可用的数据类型。分类变量只接受固定类别(通常是固定数量)的值。分类变量的一些例子是性别、血型、语言等。与这些变量的一个主要对比是这些变量不能进行数学运算。
可以使用Dataframe构造函数并指定 dtype = “category”在 pandas 中创建由分类值组成的数据框。
Python3
# importing pandas as pd
import pandas as pd
# Create the dataframe
# with categorical variable
df = pd.DataFrame({'A': ['a', 'b', 'c',
'c', 'a', 'b'],
'B': [0, 1, 1, 0, 1, 0]},
dtype = "category")
# show the data types
df.dtypesPython3
# initial state
print(df)
# counting number of each category
print(df.groupby(['A']).count().reset_index())Python3
# importing pandas as pd
import pandas as pd
# Create the dataframe
df = pd.DataFrame({'A': ['a', 'b', 'c',
'c', 'a', 'b'],
'B': [0, 1, 1,
0, 1, 0],
'C':[7, 8, 9,
5, 3, 6]})
# change tha datatype of
# column 'A' into category
# data type
df['A'] = df['A'].astype('category')
# initial state
print(df)
# calculating mean with
# all combinations of A and B
print(df.groupby(['A','B']).mean().reset_index())输出:

这里有一个重要的事情是每列中生成的类别不同,转换是逐列完成的,我们可以在这里看到:
输出:


现在,在某些工作中,我们需要对分类数据进行分组。这是使用 pandas 中给出的groupby()方法完成的。它返回 groupby 列的所有组合。与 groupyby 一起,我们必须传递一个聚合函数,以确保我们将在什么基础上对变量进行分组。一些聚合函数是mean()、sum()、count()等。
现在应用我们的 groupby() 和 count()函数。
Python3
# initial state
print(df)
# counting number of each category
print(df.groupby(['A']).count().reset_index())
输出:
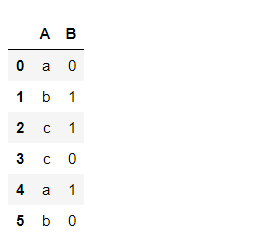
数据框

按列“A”分组
现在,再举一个 mean()函数的例子。这里A列被转换为分类,所有其他都是数字,平均值是根据A列和B列的类别计算的。
Python3
# importing pandas as pd
import pandas as pd
# Create the dataframe
df = pd.DataFrame({'A': ['a', 'b', 'c',
'c', 'a', 'b'],
'B': [0, 1, 1,
0, 1, 0],
'C':[7, 8, 9,
5, 3, 6]})
# change tha datatype of
# column 'A' into category
# data type
df['A'] = df['A'].astype('category')
# initial state
print(df)
# calculating mean with
# all combinations of A and B
print(df.groupby(['A','B']).mean().reset_index())
输出:

数据框

按列“A”和“B”分组
其他聚合函数也使用groupby()以相同的方式实现。