在Python Pandas 中的多个列中填充
在本文中,我们将编写Python脚本以使用 Pandas 库在Python中填充多个列。数据框是一种二维数据结构,可以以 CSV、Excel、.dB、SQL 格式存储。我们将使用Python的 Pandas 库来填充 Data Frame 中的缺失值。
让我们通过实现来理解这一点:
首先用熊猫创建一个数据集
Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan,
np.nan, 4,
2, np.nan,
np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Printing The dataframe
display(dataframe)Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan, 4, 2,
np.nan,np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Creating a constant value for column Count
constant_values = {'Count': 10}
dataframe = dataframe.fillna(value = constant_values)
# Printing the dataframe
display(dataframe)Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan, 4, 2,
np.nan,np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Filling Count column with mean of Count column
dataframe.fillna(dataframe['Count'].mean(), inplace = True)
# Printing the Dataframe
display(dataframe)Python3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan,
1, 2, np.nan,np.nan,
5, 1],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Using Mode() function to impute the values using fillna
dataframe.fillna(dataframe['Count'].mode()[0], inplace = True)
# Printing the Dataframe
display(dataframe)输出:
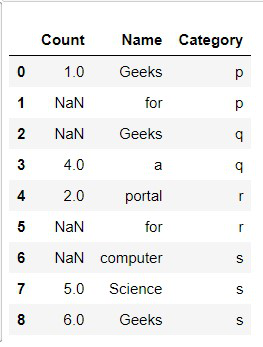
示例 1:用固定值填充缺失的列值:
我们可以使用 fillna()函数将数据框的缺失值插补到值字典定义的每一列。 这种方法的局限性是我们只能使用常量值进行填充。
蟒蛇3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan, 4, 2,
np.nan,np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Creating a constant value for column Count
constant_values = {'Count': 10}
dataframe = dataframe.fillna(value = constant_values)
# Printing the dataframe
display(dataframe)
输出:

示例 2:使用 mean() 填充缺失的列值:
在此方法中,值由称为mean()的方法定义,该方法找出给定列的现有值的平均值,然后估算每个缺失 (NaN) 值中的平均值。
蟒蛇3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan, 4, 2,
np.nan,np.nan, 5, 6],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Filling Count column with mean of Count column
dataframe.fillna(dataframe['Count'].mean(), inplace = True)
# Printing the Dataframe
display(dataframe)
输出:

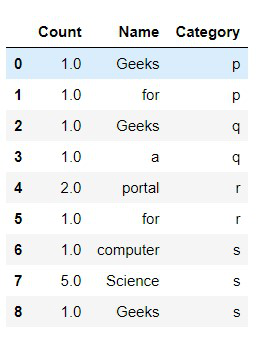
示例 3:使用 mode() 填充缺失的列值。
众数是一组数据值中最常出现的值。如果 X 是离散随机变量,则众数是概率质量函数取其最大值时的值 x。换句话说,它是最有可能被采样的值。
蟒蛇3
# Importing Required Libraries
import pandas as pd
import numpy as np
# Creating a sample dataframe with NaN values
dataframe = pd.DataFrame({'Count': [1, np.nan, np.nan,
1, 2, np.nan,np.nan,
5, 1],
'Name': ['Geeks','for', 'Geeks','a','portal','for',
'computer', 'Science','Geeks'],
'Category':list('ppqqrrsss')})
# Using Mode() function to impute the values using fillna
dataframe.fillna(dataframe['Count'].mode()[0], inplace = True)
# Printing the Dataframe
display(dataframe)
输出:
.