Bash 脚本 – 子字符串
在本文中,我们将讨论如何编写 bash 脚本来从字符串中提取子字符串。
提取基于索引的子字符串
有多种方法可以根据字符串中字符的索引来获取子字符串:
- 使用剪切命令
- 使用 Bash 子字符串
- 使用 expr substr 命令
- 使用 awk 命令
方法一:使用cut命令
剪切命令用于执行切片操作以获得所需的结果。
句法:
cut [option] range [string/filename]-c 选项用于按字符剪切字符串。必须指定字符数的列表或范围,否则此选项会出错。在 range 中,指定 original 的索引范围以获取子字符串。它使用基于 1 的索引(索引从 1 开始)系统。
示例 1:出于演示目的,让我们提取字符串“01010string”中字符的最后一个 0。
代码:
cut -c 6-11<<< '01010string'<<< 被称为此处字符串。使用它,可以将预先制作的文本字符串传递给程序。我们指定了范围 6-11,因为 6 是起始索引,而 11 是我们想要的结果的结束索引。
输出:
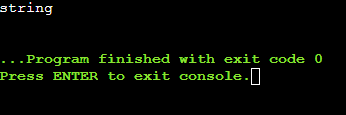
示例 2:现在提取字符'01010string' 中 's' 之前的字符串。
代码:
cut -c 1-5<<< '01010string'我们指定了 1-5 的范围,因为 1 是起始索引,5 是我们想要的结果的结束索引。
输出:

方法 2: Bash 的子字符串(不使用外部命令)
句法:
${VAR:start_index:length}它使用基于 0 的索引系统。
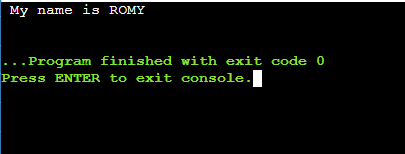
示例 1:为了演示,我们将从索引 11 到索引 15 的字符串“我的名字是 ROMY”中提取子字符串。对于 11 到 15 的索引,子字符串的长度将变为 4。
代码:
STR="My name is ROMY"
echo ${STR:11:4}输出:
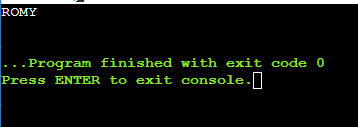
示例 2:提取位于索引 10 之前的字符串。由于此方法使用基于 0 的索引系统,因此所需字符串的长度将为 10。
代码:
STR="My name is ROMY"
echo ${STR:0:10}输出:
方法三:使用 expr 命令
它用于执行:
- 加法、减法、乘法、除法和模数运算。
- 评估正则表达式,字符串操作,如子字符串。
它使用基于 1 的索引系统。
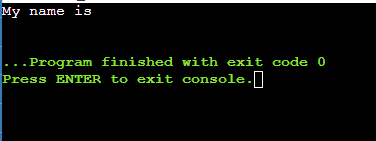
示例 1:为了演示,我们将从索引 12 到索引 16 的字符串'My name is ROMY' 中提取子字符串。对于 12 到 16 的索引,子字符串的长度将变为 4。
句法:
expr substr 代码:
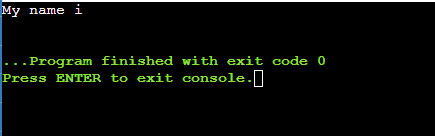
expr substr "My name is ROMY" 12 4输出:

示例 2:从字符串start 到索引 10 提取子字符串。由于该方法使用基于 1 的索引系统,因此到索引 10 的字符串的长度为 9。
代码:
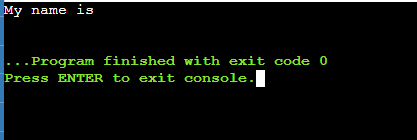
expr substr "My name is ROMY" 1 9输出:
方法四:使用awk命令
它是一种用于操作数据的脚本语言。它不需要编译,允许字符串函数、变量等。它有一个内置的 substr()函数,可以直接用来获取子字符串。
substr(s, i, n)函数接受三个参数。
- s : 输入字符串
- i : 子串的起始索引
- n :子字符串的长度。
它使用基于 1 的索引系统。
句法:
awk '{print substr($var,start_index, length)}'示例 1:从索引 12 开始提取长度为 5 的子字符串。
代码:
awk '{print substr($0, 12, 5)}' <<< 'My name is ROMY'输出:

示例 2:从索引 1 开始提取长度为 10 的字符串。
代码:
awk '{print substr($0, 1, 10)}' <<< 'My name is ROMY'输出:
提取基于模式的子字符串
有多种方法可以根据字符串的模式获取子字符串:
- 使用剪切命令
- 使用 awk 命令
方法一:使用cut命令
为了演示,将输入字符串设为逗号分隔值:“Romy, Pushkar, Kareena, Katrina”。 (-d ,) 选项与 cut 命令一起使用,以告诉命令输入字符串是逗号分隔值。 -f 选项告诉 cut 命令根据字段(如 (-f 3) 用于字符串。
句法:
cut [option] field_position <<< "comma_seperated_string"代码:
cut -d, -f 3 <<< “Romy,Pushkar,Kareena,Katrina”.这将提取第三个字段。
输出:

方法二:使用awk命令
句法:
awk [option] field_separator ‘{print $field_position}’ <<< “input_string”
代码:
从字符串中提取第三个字段
awk -F’,’ ‘{print $1}’ <<< “Romy,Pushkar,Kareena,Katrina”
输出:

不同的基于模式的子串案例
输入字符串不一定是逗号分隔值。
在此方法中,我们将看到获取位于字符串中两个模式之间的子字符串的方法。这个问题可以使用 awk 命令解决。
- sub(/.*start/, “”) - 它在开始之前删除所有内容,直到“开始”。
- sub(/end.*/, “”) - 它从“end”中删除所有内容以及 end。
句法:
awk ‘{ sub(/.*BEGIN:/, “”); sub(/END:.*/, “”); print }’ <<< “input_string”
代码:
STR="Hello!! My name is ROMY kumari"
awk '{ sub(/.*!!/, ""); sub(/kumari.*/, ""); print }' <<< "$STR"输出: