机器学习中的堆叠
Stacking 是一种集成多个分类或回归模型的方法。集成模型的方法有很多,广为人知的模型是Bagging或Boosting 。 Bagging 允许对多个具有高方差的相似模型进行平均以减少方差。 Boosting 构建多个增量模型以减少偏差,同时保持较小的方差。
堆叠(有时称为堆叠泛化)是一种不同的范式。堆叠的目的是为同一问题探索不同模型的空间。这个想法是你可以用不同类型的模型来解决学习问题,这些模型能够学习问题的一部分,而不是问题的整个空间。因此,您可以构建多个不同的学习器,并使用它们构建一个中间预测,每个学习模型一个预测。然后添加一个新模型,该模型从中间预测中学习相同的目标。
据说这个最终模型堆叠在其他模型的顶部,因此得名。因此,您可能会提高整体性能,并且通常最终会得到比任何单个中间模型都更好的模型。但是请注意,它并没有给您任何保证,就像任何机器学习技术一样。 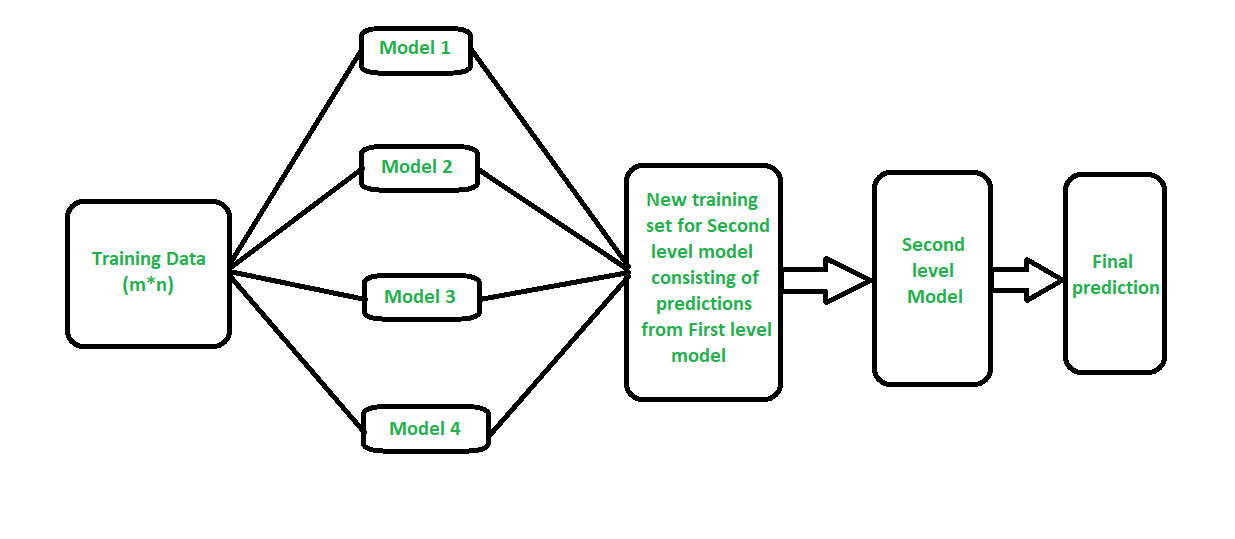
堆叠如何工作?
- 我们将训练数据拆分为 K 折,就像 K 折交叉验证一样。
- 在 K-1 零件上拟合基本模型,并对第 K 零件进行预测。
- 我们对训练数据的每一部分都做。
- 然后在整个训练数据集上拟合基础模型,以计算其在测试集上的性能。
- 我们对其他基本模型重复最后 3 个步骤。
- 来自训练集的预测用作第二级模型的特征。
- 二级模型用于对测试集进行预测。

混合——
混合是一种类似的堆叠方法。
- 训练集分为训练集和验证集。
- 我们在训练集上训练基础模型。
- 我们只对验证集和测试集进行预测。
- 验证预测用作构建新模型的特征。
- 该模型用于使用预测值作为特征对测试集进行最终预测。