Python:更新嵌套字典
Python中的字典与现实世界中的字典类似。 Dictionary 的键必须是唯一的并且是不可变的数据类型,例如字符串、整数和元组,但键值可以重复并且可以是任何类型。
Refer to the below article to get the idea about dictionaries:
- Python Dictionary
嵌套字典: Python中的嵌套字典只不过是字典中的字典。
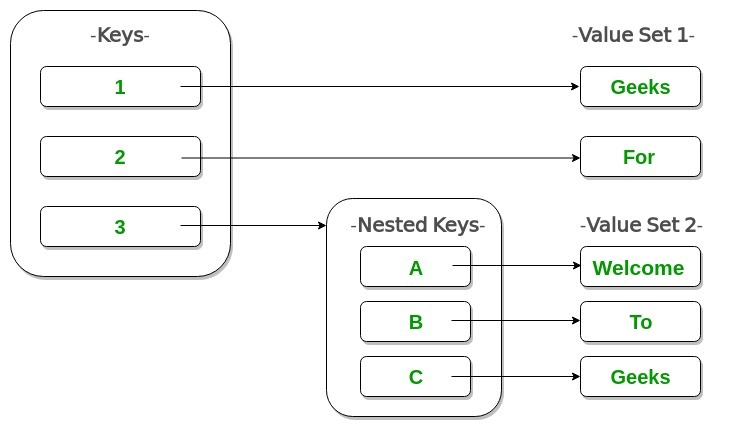
考虑如下给出的员工记录:
Employees
emp1:
name:Lisa
age:29
designation:Programmer
emp2:
name:Steve
age:45
designation:HR
在这里,员工是外部字典。 emp1、emp2是具有另一个字典作为其值的键。上述信息的字典结构显示为:
employees:
{
emp1:
{
'name':'Lisa',
'age':29,
'designation':'Programmer'
},
emp2:
{
'name':'Steve',
'age':45,
'designation':'HR'
}
}
考虑一个简单的字典,如d={'a':1, 'b':2, 'c':3} 。如果要将'b'的值更新为7 ,可以写为d['b']=7 。但是,相同的方法不能应用于嵌套的方法。这将创建一个新键,因为只有在您尝试更新时才会搜索外部字典中的键。例如,请参见下面的代码:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '45',
'Designation':'HR'
}
}
# updating in the way similar to
# simple dictionary
Employee['name']='Kate'
print(Employee)
{‘name’: ‘Kate’, ’emp1′: {‘Designation’: ‘Programmer’, ‘name’: ‘Lisa’, ‘age’: ’29’}, ’emp2′: {‘Designation’: ‘HR’, ‘name’: ‘Steve’, ‘age’: ’45’}}
在输出中,'name':'Kate' 被添加为一个新的键值对,这不是我们想要的输出。让我们考虑一下,我们需要将第一个员工的姓名更新为“Kate”。让我们把我们的字典看成一个二维数组。这将有助于我们轻松更新信息。上述字典的二维数组视图如下:
Employee name age Designation
emp1 Lisa 29 Programmer
emp2 Steve 45 HR
现在我们必须将第一个员工的姓名更新为“Kate”。所以我们必须更新 Employee['emp1']['name']。修改后的代码如下:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# updating in the way similar to simple dictionary
Employee['emp1']['name']='Kate'
print(Employee)
{’emp2′: {‘Designation’: ‘HR’, ‘age’: ’25’, ‘name’: ‘Steve’}, ’emp1′: {‘Designation’: ‘Programmer’, ‘age’: ’29’, ‘name’: ‘Kate’}}
如果字典中存在上述键,则上述方法会更新该键的值。否则,它会创建一个新条目。例如,如果您想为第一个员工添加一个新属性“salary” ,那么您可以将上面的代码编写为:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# updating in the way similar to
# simple dictionary
Employee['emp1']['name']='Kate'
# adding new key-value pair to first
# employee record
Employee['emp1']['salary']= 56000
print(Employee)
{’emp1′: {‘Designation’: ‘Programmer’, ‘salary’: 56000, ‘name’: ‘Kate’, ‘age’: ’29’}, ’emp2′: {‘Designation’: ‘HR’, ‘name’: ‘Steve’, ‘age’: ’25’}}
上述方法是静态的。现在为了让它与用户交互,我们可以稍微修改一下代码,如下所示:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# to make the updation dynamic
# Get input from the user for which
# employee he needs to update
empid = input("Employee id :")
# which attribute / key to update
attribute = input("Attribute to be updated :")
# what value to update
new_value = input("New value :")
# updation of the dictionary
Employee[empid][attribute]= new_value
print(Employee)
Employee id :emp1
Attribute to be updated :name
New value :Kate
{’emp1′: {‘age’: ’29’, ‘Designation’: ‘Programmer’, ‘name’: ‘Kate’}, ’emp2′: {‘age’: ’25’, ‘Designation’: ‘HR’, ‘name’: ‘Steve’}}
让我们尝试更专业一点!!
另一种方法
这个想法是先展平嵌套字典,然后更新它并再次展平它。为了更清楚,请考虑以下字典作为示例:
dict1={
'a':{
'b':1
},
'c':{
'd':2,
'e':5
}
}
展平嵌套字典只不过是使用适当的分隔符将父键与真实键附加在一起。分隔符可以是任何符号。它可以是逗号 (, ),或连字符 (-),或下划线 (_),或句点 (.),甚至只是一个空格 ()。在这里,用下划线作为分隔符进行展平后,该字典将如下所示:
dict1={'a_b':1, 'c_d':2, 'c_e':5}
扁平化可以通过Python中的flatten-dict包提供的内置方法轻松完成。它提供了扁平化字典之类的对象和取消扁平化它们的方法。使用 pip 命令安装软件包,如下所示:
pip install flatten-dict flatten()方法:
flatten 方法具有各种参数,可以以理想、可读和可理解的方式对其进行格式化。其中最重要的两个论点是:
- dict :必须转换的扁平字典
- reducer :它指定父键如何与子键连接。可能的值是元组、路径、下划线或用户定义的函数名。
- tuple:创建一个由父键和子键组成的元组作为键并将值分配给它。
- path :在父键和子键之间附加“/”。
- 下划线:在父键和子键之间附加“_”。
- 用户定义函数:父键和子键应作为参数传递给函数。该函数应将它们作为由所需符号分隔的字符串返回
其他参数 enumerate_types、keep_empty_types 是可选的
unflatten()方法:
此方法将扁平化字典展开并将其转换为嵌套字典。它可以采用三个参数:
- dict :必须还原的扁平字典
- splitter :必须在其上拆分扁平字典的符号。像 flatten 方法一样,这也占用了值元组、路径、下划线或用户定义的函数。
- inverse :取一个布尔值,指示键和值是否必须反转。这是可选的。
让我们考虑一下我们在上面尝试过的同一个 Employee 示例。代码如下:
from flatten_dict import flatten
from flatten_dict import unflatten
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# flattening the dictionary, default
# reducer is 'tuple'
dict3 = flatten(Employee)
print("Flattened dictionary :", dict3)
# adding new key-value pair to second
# employee's record
dict3[('emp2', 'salary')]= 34000
print(dict3)
# unflattening the dictionary, default
# splitter is 'tuple'
Employee = unflatten(dict3)
print("\nUnflattened and updated dictionary :", Employee)
输出:
Flattened dictionary : {(’emp1′, ‘name’): ‘Lisa’, (’emp1′, ‘age’): ’29’, (’emp1′, ‘Designation’): ‘Programmer’, (’emp2′, ‘name’): ‘Steve’, (’emp2′, ‘age’): ’25’, (’emp2′, ‘Designation’): ‘HR’}
{(’emp1′, ‘name’): ‘Lisa’, (’emp1′, ‘age’): ’29’, (’emp1′, ‘Designation’): ‘Programmer’, (’emp2′, ‘name’): ‘Steve’, (’emp2′, ‘age’): ’25’, (’emp2′, ‘Designation’): ‘HR’, (’emp2′, ‘salary’): 34000}
Unflattened and updated dictionary : {’emp1′: {‘name’: ‘Lisa’, ‘age’: ’29’, ‘Designation’: ‘Programmer’}, ’emp2′: {‘name’: ‘Steve’, ‘age’: ’25’, ‘Designation’: ‘HR’, ‘salary’: 34000}}