使用 Scrapy 将抓取的项目保存到 JSON 和 CSV 文件
在本文中,我们将看到如何使用 Scrapy 进行爬网,以及将数据导出为 JSON 和 CSV 格式。我们将使用 Scrapy 蜘蛛从网页中抓取数据,并将其导出为两种不同的文件格式。
在这里,我们将从链接 http://quotes.toscrape.com/tag/friendship/ 中提取。本网站由 Scrapy 的制作者提供,用于了解该库。让我们逐步理解上述方法:
第一步:创建scrapy项目
在终端执行以下命令,创建一个 Scrapy 项目——
scrapy startproject gfg_friendshipquotes 这将在您的当前目录中创建一个名为“gfg_friendshipquotes”的新目录。现在将目录更改为新创建的文件夹。

'gfg_friendshipquotes' 的文件夹结构如下所示。当前保持配置文件的内容不变。


第 2 步:要创建蜘蛛文件,我们使用命令“genspider”。请注意 genspider 命令在同一目录级别执行,其中存在 scrapy.cfg 文件。命令是——
scrapy genspider spider_filename “url_of_page_to_scrape”
现在,在终端执行以下命令:
scrapy genspider gfg_friendquotes “quotes.toscrape.com/tag/friendship/”
应该在蜘蛛文件夹中创建一个名为“gfg_friendquotes.py”的蜘蛛Python文件,如下所示:

gfg_friendquotes.py 文件的默认代码如下:
Python
# Import the required library
import scrapy
# Spider class
class GfgFriendquotesSpider(scrapy.Spider):
# The name of the spider
name = 'gfg_friendquotes'
# The domain, the spider will crawl
allowed_domains = ['quotes.toscrape.com/tag/friendship/']
# The URL of the webpage, data from which
# will get scraped
start_urls = ['http://quotes.toscrape.com/tag/friendship/']
# default start function which will hold
# the code for navigating and gathering
# the data from tags
def parse(self, response):
passPython3
# Import the required libraries
import scrapy
# Default class created when we run the "genspider" command
class GfgFriendquotesSpider(scrapy.Spider):
# Name of the spider as mentioned in the "genspider" command
name = 'gfg_friendquotes'
# Domains allowed for scraping, as mentioned in the "genspider" command
allowed_domains = ['quotes.toscrape.com/tag/friendship/']
# URL(s) to scrape as mentioned in the "genspider" command
# The scrapy spider, starts making requests, to URLs mentioned here
start_urls = ['http://quotes.toscrape.com/tag/friendship/']
# Default callback method responsible for returning the scraped output and processing it.
def parse(self, response):
# XPath expression of all the Quote elements.
# All quotes belong to CSS attribute class having value 'quote'
quotes = response.xpath('//*[@class="quote"]')
# Loop through the quotes object, to get required elements data.
for quote in quotes:
# XPath expression to fetch 'title' of the Quote
# Title belong to CSS attribute class having value 'text'
title = quote.xpath('.//*[@class="text"]/text()').extract_first()
# XPath expression to fetch 'author name' of the Quote
# Author name belong to CSS attribute itemprop having value 'author'
author = quote.xpath(
'.//*[@itemprop="author"]/text()').extract_first()
# XPath expression to fetch 'tags' of the Quote
# Tags belong to CSS attribute itemprop having value 'keywords'
tags = quote.xpath(
'.//*[@itemprop="keywords"]/@content').extract_first()
# Return the output
yield {'Text': title,
'Author': author,
'Tags': tags}Python
BOT_NAME = 'gfg_friendshipquotes'
SPIDER_MODULES = ['gfg_friendshipquotes.spiders']
NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Desired file format
FEED_FORMAT = "json"
# Name of the file where
# data extracted is stored
FEED_URI = "friendshipfeed.json"Python
BOT_NAME = 'gfg_friendshipquotes'
SPIDER_MODULES = ['gfg_friendshipquotes.spiders']
NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Desired file format
FEED_FORMAT = "csv"
# Name of the file where data extracted is stored
FEED_URI = "friendshipfeed.csv"第 3 步:现在,让我们分析所需元素的 XPath 表达式。如果您访问该链接,http://quotes.toscrape.com/tag/friendship/ 如下所示:
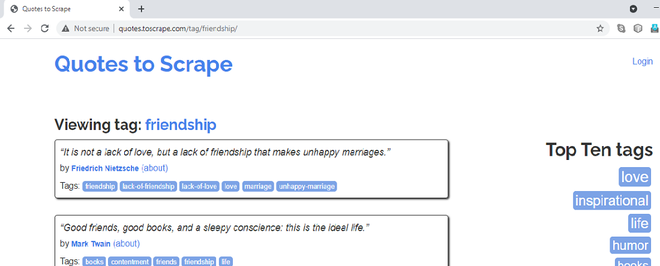
我们将抓取的页面的 URL
我们将抓取友谊引述的标题、作者和标签。当您右键单击 Quotes 并阻止它并选择 Inspect 选项时,您会注意到它们属于“quote”类。当您将鼠标悬停在引用块的其余部分上时,您会注意到网页中的所有引用都将 CSS 类属性设为“quote”。
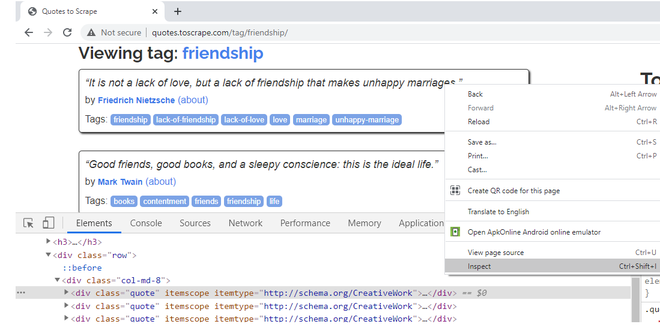
右键单击,检查,检查第一个 Quote 块的 CSS 属性
要提取引用的文本,请右键单击第一个引用,然后说“检查”。引用的标题/文本属于 CSS 类属性“文本”。
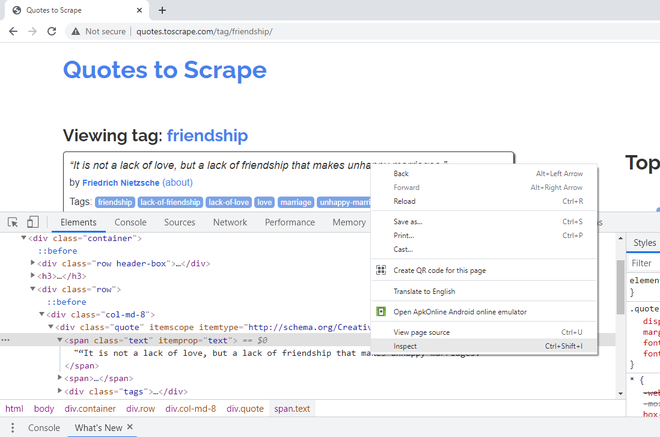
右键单击第一个标题,检查,检查 CSS 类属性
要提取引文的作者姓名,请右键单击名字,然后说“检查”。它属于 CSS 类“作者”。有一个 itemprop CSS 属性,这里也定义了同名。我们将在我们的代码中使用这个属性。
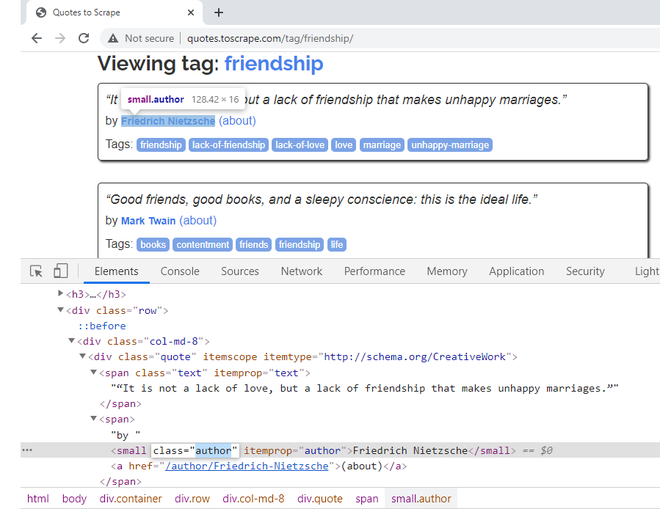
右键单击作者姓名以获取其 CSS 属性
第 7 步:要提取引用的标签,请右键单击第一个标签,然后说“检查”。单个标签属于 CSS 类“标签”。它们一起有一个 itemprop CSS 属性,定义了“关键字”。它们还有一个“内容”CSS 属性,所有标签都在一行中。如果您观察到,标签的实际文本存在于 超链接元素中。因此,从“内容”属性中获取会更容易。
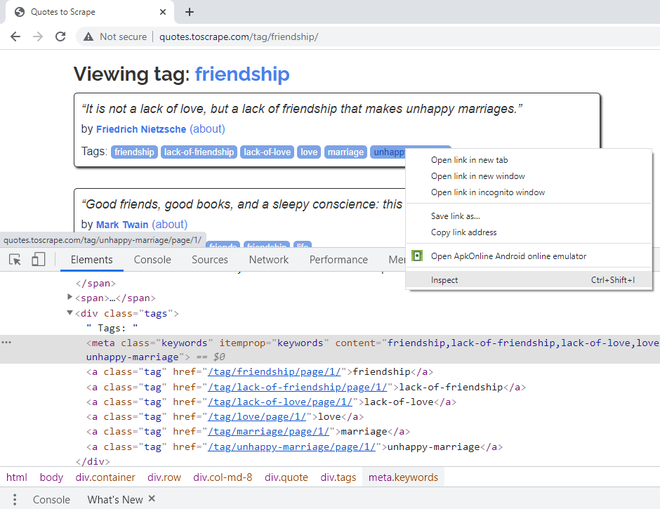
右键单击标签以获取其 CSS 属性
在包含 XPath 表达式之后,蜘蛛文件的最终代码如下:
蟒蛇3
# Import the required libraries
import scrapy
# Default class created when we run the "genspider" command
class GfgFriendquotesSpider(scrapy.Spider):
# Name of the spider as mentioned in the "genspider" command
name = 'gfg_friendquotes'
# Domains allowed for scraping, as mentioned in the "genspider" command
allowed_domains = ['quotes.toscrape.com/tag/friendship/']
# URL(s) to scrape as mentioned in the "genspider" command
# The scrapy spider, starts making requests, to URLs mentioned here
start_urls = ['http://quotes.toscrape.com/tag/friendship/']
# Default callback method responsible for returning the scraped output and processing it.
def parse(self, response):
# XPath expression of all the Quote elements.
# All quotes belong to CSS attribute class having value 'quote'
quotes = response.xpath('//*[@class="quote"]')
# Loop through the quotes object, to get required elements data.
for quote in quotes:
# XPath expression to fetch 'title' of the Quote
# Title belong to CSS attribute class having value 'text'
title = quote.xpath('.//*[@class="text"]/text()').extract_first()
# XPath expression to fetch 'author name' of the Quote
# Author name belong to CSS attribute itemprop having value 'author'
author = quote.xpath(
'.//*[@itemprop="author"]/text()').extract_first()
# XPath expression to fetch 'tags' of the Quote
# Tags belong to CSS attribute itemprop having value 'keywords'
tags = quote.xpath(
'.//*[@itemprop="keywords"]/@content').extract_first()
# Return the output
yield {'Text': title,
'Author': author,
'Tags': tags}
Scrapy 允许以 JSON、CSV、XML 等格式存储提取的数据。本教程展示了两种方法。可以在终端写以下命令:
scrapy crawl “spider_name” -o store_data_extracted_filename.file_extension
或者,可以通过在 settings.py 文件中提及 FEED_FORMAT 和 FEED_URI 将输出导出到文件。
创建 JSON 文件
要将数据存储在 JSON 文件中,可以采用以下任何一种方法:
scrapy crawl gfg_friendquotes -o friendshipquotes.json或者,我们可以在 settings.py 文件中提及 FEED_FORMAT 和 FEED_URI。 settings.py 文件应如下所示:
Python
BOT_NAME = 'gfg_friendshipquotes'
SPIDER_MODULES = ['gfg_friendshipquotes.spiders']
NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Desired file format
FEED_FORMAT = "json"
# Name of the file where
# data extracted is stored
FEED_URI = "friendshipfeed.json"
输出:

使用上述任何一种方法,JSON 文件在项目文件夹中生成为:
提取的数据,导出到 JSON 文件
预期的 JSON 文件如下所示:
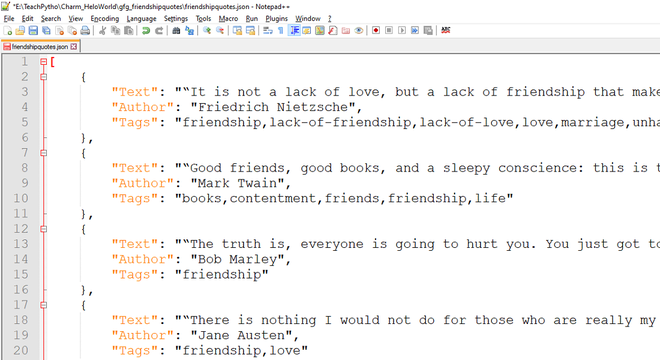
导出的 JSON 数据,爬虫代码爬取
创建 CSV 文件:
要将数据存储在 CSV 文件中,可以按照下面提到的任何一种方法进行操作。
在终端写入以下命令:
scrapy crawl gfg_friendquotes -o friendshipquotes.csv或者,我们可以在 settings.py 文件中提及 FEED_FORMAT 和 FEED_URI。 settings.py 文件应如下所示:
Python
BOT_NAME = 'gfg_friendshipquotes'
SPIDER_MODULES = ['gfg_friendshipquotes.spiders']
NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Desired file format
FEED_FORMAT = "csv"
# Name of the file where data extracted is stored
FEED_URI = "friendshipfeed.csv"
输出:

CSV 文件在项目文件夹中生成为:
导出的文件在您的scrapy 项目结构中创建
导出的 CSV 文件如下所示:

导出的CSV数据,爬虫代码爬取