Pandas 删除带有特殊字符的行
在本文中,我们将学习如何删除带有特殊字符的行,即;如果一行包含任何包含特殊字符(如@、%、&、$、#、+、-、*、/ 等)的值,则删除该行并修改数据。要删除此类行,首先,我们必须搜索每列具有特殊字符的行,然后删除。为了搜索,我们使用正则表达式 [@#&$%+-/*] 或 [^0-9a-zA-Z]。让我们用一些例子来讨论整个过程:
示例 1:
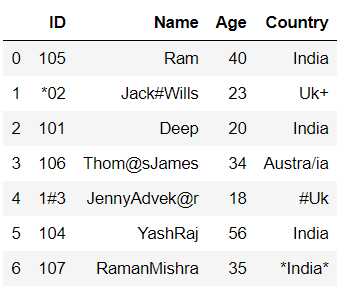
本示例由部分代码组成,使用的数据框可以通过点击data1.csv下载或如下所示。
Python3
# importing package
import pandas as pd
# load dataset
df = pd.read_csv("data1.csv")
# view dataset
print(df)Python3
# select the rows
# if Name column
# has special characters
print(df[df.Name.str.contains(r'[@#&$%+-/*]')])Python3
# select the rows
# if Grade column
# has special characters
print(df[df.Grade.str.contains(r'[^0-9a-zA-Z]')])Python3
# merge the selected rows
# by using or
print(df[df.Name.str.contains(r'[^0-9a-zA-Z]')
| df.Grade.str.contains(r'[@#&$%+-/*]')])Python3
# drop the merged selected rows
print(df.drop(df[df.Name.str.contains(r'[^0-9a-zA-Z]')
| df.Grade.str.contains(r'[^0-9a-zA-Z]')].index))Python3
# importing package
import pandas as pd
# load dataset
df = pd.read_csv("data2.csv")
# view dataset
print(df)
# select and then merge rows
# with special characters
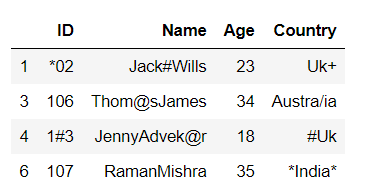
print(df[df.ID.str.contains(r'[^0-9a-zA-Z]') |
df.Name.str.contains(r'[^0-9a-zA-Z]') |
df.Age.str.contains(r'[^0-9a-zA-Z]') |
df.Country.str.contains(r'[^0-9a-zA-Z]')])
# drop the rows
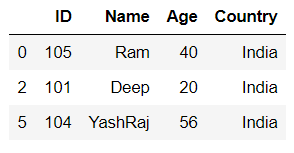
print(df.drop(df[df.ID.str.contains(r'[^0-9a-zA-Z]') |
df.Name.str.contains(r'[^0-9a-zA-Z]') |
df.Age.str.contains(r'[^0-9a-zA-Z]') |
df.Country.str.contains(r'[^0-9a-zA-Z]')].index))输出:

选择具有特殊字符值的列的行
蟒蛇3
# select the rows
# if Name column
# has special characters
print(df[df.Name.str.contains(r'[@#&$%+-/*]')])
输出:
蟒蛇3
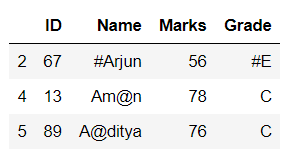
# select the rows
# if Grade column
# has special characters
print(df[df.Grade.str.contains(r'[^0-9a-zA-Z]')])
输出:
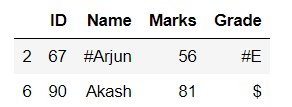
合并选定行
蟒蛇3
# merge the selected rows
# by using or
print(df[df.Name.str.contains(r'[^0-9a-zA-Z]')
| df.Grade.str.contains(r'[@#&$%+-/*]')])
输出:
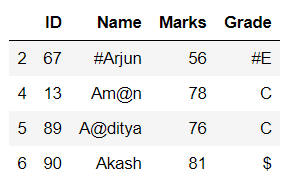
删除合并的选定行
蟒蛇3
# drop the merged selected rows
print(df.drop(df[df.Name.str.contains(r'[^0-9a-zA-Z]')
| df.Grade.str.contains(r'[^0-9a-zA-Z]')].index))
输出:
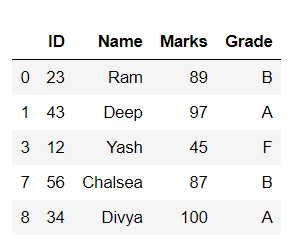
示例 2:此示例使用可以通过单击data2.csv或如下所示下载的数据帧:
蟒蛇3
# importing package
import pandas as pd
# load dataset
df = pd.read_csv("data2.csv")
# view dataset
print(df)
# select and then merge rows
# with special characters
print(df[df.ID.str.contains(r'[^0-9a-zA-Z]') |
df.Name.str.contains(r'[^0-9a-zA-Z]') |
df.Age.str.contains(r'[^0-9a-zA-Z]') |
df.Country.str.contains(r'[^0-9a-zA-Z]')])
# drop the rows
print(df.drop(df[df.ID.str.contains(r'[^0-9a-zA-Z]') |
df.Name.str.contains(r'[^0-9a-zA-Z]') |
df.Age.str.contains(r'[^0-9a-zA-Z]') |
df.Country.str.contains(r'[^0-9a-zA-Z]')].index))
输出 :