用于从维基百科中删除单词定义的 Shell 脚本
Web Scrapping 是程序员工具包中非常有趣且强大的工具或技能。它有助于分析数据并以各种格式获取一些信息。 Web Scraping 是一个过程,在该过程中,用户使用这些 HTML 标签中的某种模式以及要获取或抓取的所需内容来获取网站内容。
对于本文,我们的目标是获取用户从 Wikipedia 网站输入的单词的含义。我们只需要从其中的 HTML 标签打印单词的含义。要完成所有这些,我们必须对 HTML 和一些基本的 Linux 工具(如 cURL、grep、sed 等)有很好的了解。
检查目标网站:
首先,报废网站,首先,检查网站并查看其源代码绝对重要。为此,我们可以在浏览器中使用 Inspect 工具。只需右键单击您正在查看的网站或要抓取的网站,您面前就会出现一个选项列表。您必须选择 Inspect 选项(还有 Shift + control + I),这将打开一个带有大量选项的侧窗。您只需从菜单顶部选择元素。您将看到的代码是网站的源代码。不,不要认为您可以从这里更改网站的内容。
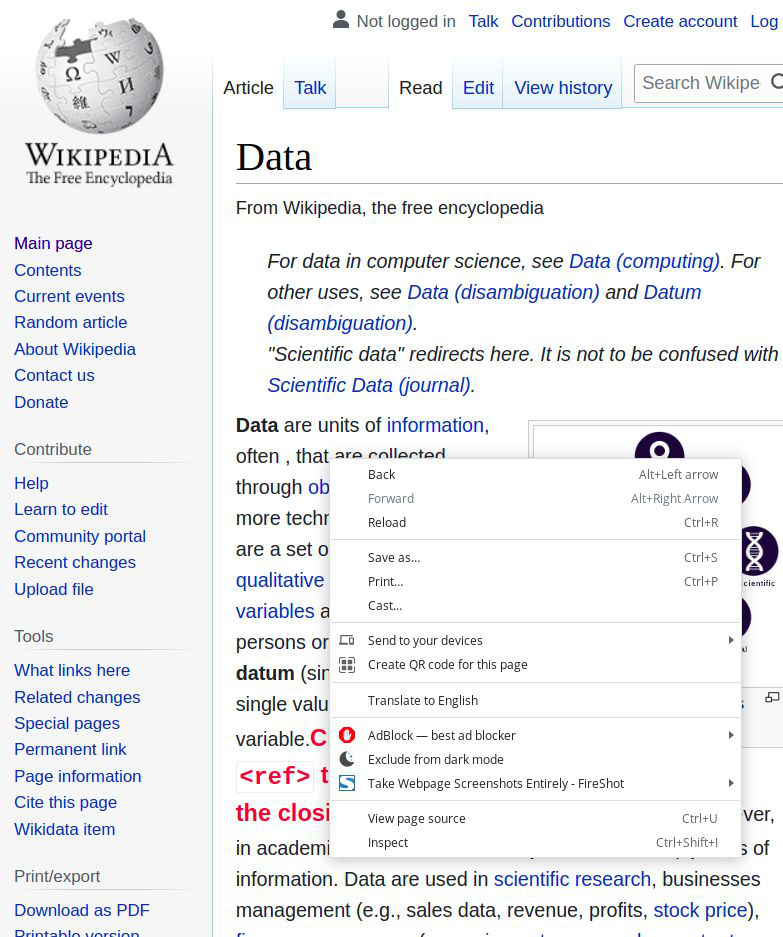
现在我们必须用我们想要抓取的内容来分析网站。您可以继续单击左上角的“选择页面中的元素进行检查”选项或图标。这将允许您检查您在网页上选择的特定元素。您现在可以看到获取元素内容所需的元素标签、id、类和其他属性。
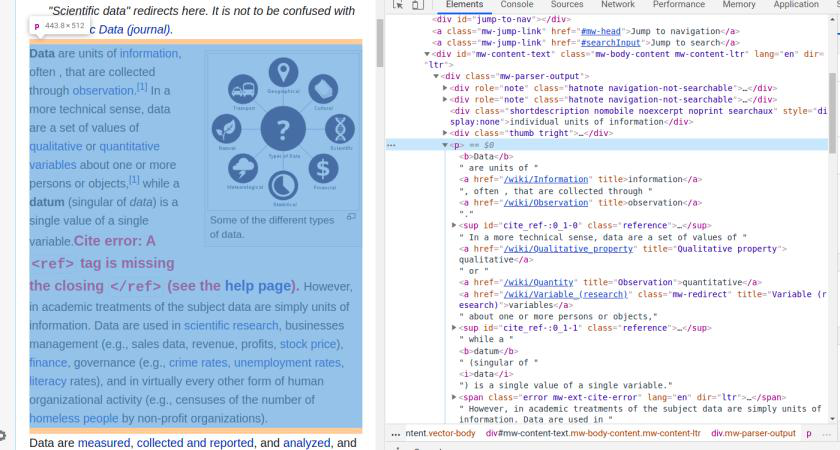
从命令行/终端访问网站:
现在了解了网站结构,我们实际上可以将其废弃。为此,我们需要在我们的本地机器上拥有网站的内容。首先,我们需要从其他地方而不是从浏览器访问该网站,因为您无法从那里复制粘贴内容。所以让我们在这里使用命令行。我们有一个流行的工具,称为 cURL,它代表客户端 URL。该工具获取提供的 URL 的内容。它还具有多个可用于修改其输出的参数或参数。我们可以使用命令
$ curl -o output.txt https://en.wikipedia.org/wiki/Data例子:
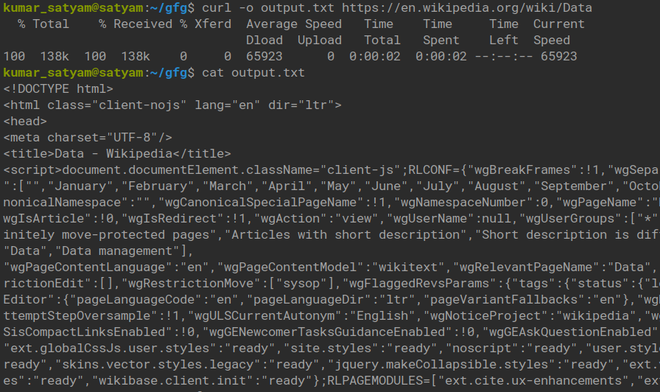
上面的命令获取单词 Computer 的 HTML 页面,它可以是您可能正在搜索的任何单词。
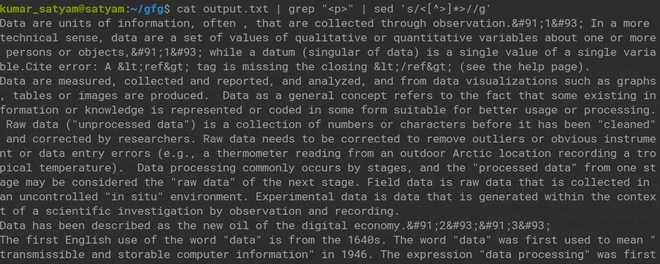
现在,我们必须过滤标签,如上图所示,这里我们使用 Regex 从文件中删除 <> 标签,因此它们之间的任何内容也被删除,我们只得到纯文本,但它也可能包含特殊的字符和符号。为了删除它,我们将再次使用 grep 并过滤我们文件中的精细含义。
cat output.txt | grep "" | sed 's/<[^>]*>//g'
制作 Shell 脚本:
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $(basename $0) 'word '"
exit 1
fi
curl=$(which curl)
outfile="output.txt"
word=$(echo $1)
url="https://en.wikipedia.org/wiki/$word"
echo $url
curl -o "output.txt" $url
function strip_html(){
grep "" $outfile | sed 's/<[^>]*>//g' > temp.txt && cp temp.txt $outfile
}
function res(){
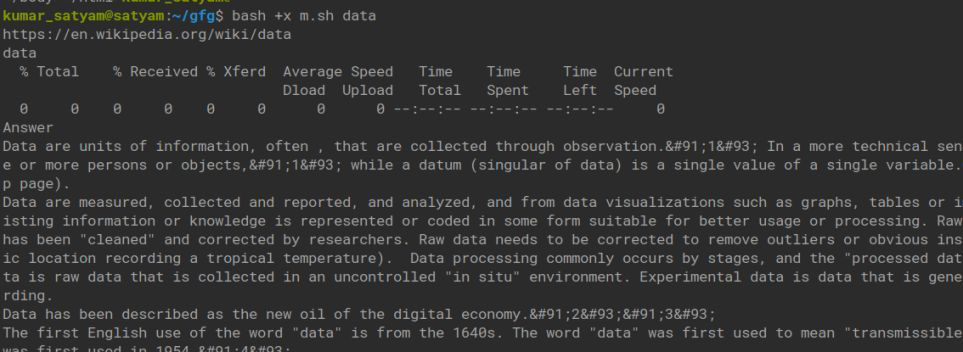
echo "Answer"
while read result; do
echo "${result}"
done < $outfile
}
strip_html
res
输出: