如何在Python中执行 Breusch-Pagan 测试
异方差是一个统计术语,它被定义为残差的不均等分散。更具体地说,它指的是测量值范围内残差分布的变化。异方差性具有挑战,因为普通最小二乘 (OLS) 回归考虑了从具有同方差性的总体中抛出的残差,这意味着方差不变。如果回归分析存在异方差性,则分析的结果不能轻易被信任。
Breusch-Pagan检验是检验回归分析中是否存在异方差性的一种方法。 Breusch-Pagan 检验遵循以下假设:
假设:
- 原假设 (H0):表示存在同方差性。
- 备择假设:(Ha):表示不存在同方差性(即存在异方差性)
安装 numNumPypy、pandas 和 statsmodels 库的语法:
pip3 install numpy pandas statsmodels执行 Breusch-Pegan 测试:
执行 Breusch-Pegan 测试是一个循序渐进的过程。这些已在下文讨论。
第 1 步:导入库。
第一步是导入我们在上面安装的库。
Python3
# Importing libraries
import numpy as np
import pandas as pd
import statsmodels.formula.api as smfPython3
# Create a dataset
dataframe = pd.DataFrame({'rating': [92, 84, 87, 82, 98,
94, 75, 80, 83, 89],
'points': [27, 30, 15, 26, 27,
20, 16, 18, 19, 20],
'runs': [5000, 7000, 5102, 8019,
1200, 7210, 6200, 9214,
4012, 3102],
'wickets': [110, 120, 110, 80, 90,
119, 116, 100, 90, 76]})Python3
# Importing libraries
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
# Create a dataset
dataframe = pd.DataFrame({'rating': [92, 84, 87, 82,
98, 94, 75, 80,
83, 89],
'points': [27, 30, 15, 26,
27, 20, 16, 18,
19, 20],
'runs': [5000, 7000, 5102,
8019, 1200, 7210,
6200, 9214, 4012,
3102],
'wickets': [110, 120, 110,
80, 90, 119,
116, 100, 90,
76]})
# fit regression model
fit = smf.ols('rating ~ points+runs+wickets', data=dataframe).fit()
print(fit.summary())Python3
# Importing libraries
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
from statsmodels.compat import lzip
import statsmodels.stats.api as sms
# Creating a dataset
dataframe = pd.DataFrame({'rating': [92, 84, 87, 82,
98, 94, 75, 80,
83, 89],
'points': [27, 30, 15, 26,
27, 20, 16, 18,
19, 20],
'runs': [5000, 7000, 5102,
8019, 1200, 7210,
6200, 9214, 4012,
3102],
'wickets': [110, 120, 110,
80, 90, 119,
116, 100, 90,
76]})
# Fit the regression model
fit = smf.ols('rating ~ points+runs+wickets', data=dataframe).fit()
# Conduct the Breusch-Pagan test
names = ['Lagrange multiplier statistic', 'p-value',
'f-value', 'f p-value']
# Get the test result
test_result = sms.het_breuschpagan(fit.resid, fit.model.exog)
lzip(names, test_result)第 2 步:创建数据集。
然后我们需要创建一个数据集。
Python3
# Create a dataset
dataframe = pd.DataFrame({'rating': [92, 84, 87, 82, 98,
94, 75, 80, 83, 89],
'points': [27, 30, 15, 26, 27,
20, 16, 18, 19, 20],
'runs': [5000, 7000, 5102, 8019,
1200, 7210, 6200, 9214,
4012, 3102],
'wickets': [110, 120, 110, 80, 90,
119, 116, 100, 90, 76]})
第 3 步:拟合多元线性回归模型。
下一步是拟合多元线性回归模型。例如,我们考虑将评分作为响应变量,将点数、跑数和检票口作为解释变量。
Python3
# Importing libraries
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
# Create a dataset
dataframe = pd.DataFrame({'rating': [92, 84, 87, 82,
98, 94, 75, 80,
83, 89],
'points': [27, 30, 15, 26,
27, 20, 16, 18,
19, 20],
'runs': [5000, 7000, 5102,
8019, 1200, 7210,
6200, 9214, 4012,
3102],
'wickets': [110, 120, 110,
80, 90, 119,
116, 100, 90,
76]})
# fit regression model
fit = smf.ols('rating ~ points+runs+wickets', data=dataframe).fit()
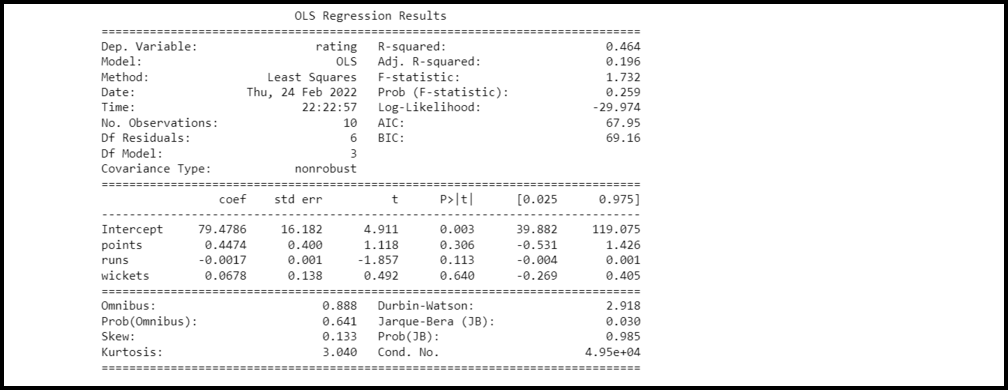
print(fit.summary())
输出:
第 4 步:进行 Breusch-Pagan 测试。
下一步是进行 Breusch-Pagan 检验以确定是否存在异方差性。
Python3
# Importing libraries
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
from statsmodels.compat import lzip
import statsmodels.stats.api as sms
# Creating a dataset
dataframe = pd.DataFrame({'rating': [92, 84, 87, 82,
98, 94, 75, 80,
83, 89],
'points': [27, 30, 15, 26,
27, 20, 16, 18,
19, 20],
'runs': [5000, 7000, 5102,
8019, 1200, 7210,
6200, 9214, 4012,
3102],
'wickets': [110, 120, 110,
80, 90, 119,
116, 100, 90,
76]})
# Fit the regression model
fit = smf.ols('rating ~ points+runs+wickets', data=dataframe).fit()
# Conduct the Breusch-Pagan test
names = ['Lagrange multiplier statistic', 'p-value',
'f-value', 'f p-value']
# Get the test result
test_result = sms.het_breuschpagan(fit.resid, fit.model.exog)
lzip(names, test_result)
输出:

输出解释:
在这里,检验的拉格朗日乘数统计量等于 4.364,相应的 p 值等于 0.224。由于 p 值大于 0.05,因此我们不能拒绝原假设。因此,我们没有足够的证据表明回归模型中存在异方差性。
如何解决异方差性:
在上面的例子中,回归模型中不存在异方差性。但是对于实际存在异方差性的情况,有三种方法可以解决这个问题:
- 转换因变量:我们可以使用一些技术来改变因变量。例如,我们可以取因变量的对数。
- 重新定义因变量:我们可以重新定义因变量。例如,使用因变量的比率而不是有缺陷的值。
- 使用加权回归:最后一种方法是使用加权回归。在这种类型的回归中,权重根据其拟合值的方差分配给每个数据点。使用适当的权重可以消除异方差问题。