绕过 Pandas 内存限制
Pandas 是一个用于分析和操作数据集的Python库,但 Pandas 的主要缺点之一是处理大型数据集时的内存限制问题,因为 Pandas DataFrames(二维数据结构)保存在内存中,如何一次可以处理大量数据。
使用中的数据集: train_dataset
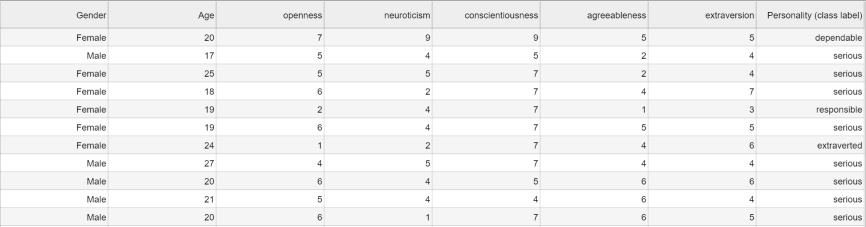
在 Pandas 中处理大量数据需要以下方法之一:
方法一:分块加载数据
pandas.read_csv()有一个名为 chunksize 的参数,用于分块加载数据。参数 chunksize 是 Pandas 一次在文件中读取的行数。它返回一个迭代器 TextFileReader,需要对其进行迭代以获取数据。
句法:
pd.read_csv(‘file_name’, chunksize= size_of_chunk)
例子:
Python3
import pandas as pd
data = pd.read_csv('train dataset.csv', chunksize=100)
for x in data:
print(x.shape[0])Python3
import pandas as pd
data=pd.read_csv('train_dataset.csv')
data = data[['Gender', 'Age', 'openness', 'neuroticism',
'conscientiousness', 'agreeableness', 'extraversion']]
display(data)Python3
import pandas as pd
data = pd.read_csv('train_dataset.csv', dtype={'Age': 'int32'})
print(data.info())Python3
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10000, 4))
df.iloc[:9998] = np.nan
sdf = df.astype(pd.SparseDtype("float", np.nan))
sdf.head()
sdf.dtypesPython3
import pandas as pd
data = pd.read_csv('train_dataset.csv')
del data输出:

方法二:过滤掉有用的数据
大型数据集有很多列/特征,但只有其中一些被实际使用。因此,为了节省更多时间用于数据操作和计算,请仅加载有用的列。
句法:
dataframe = dataframe[[‘column_1’, ‘column_2’, ‘column_3’, ‘column_4’, ‘column_5’]]
例子 :
蟒蛇3
import pandas as pd
data=pd.read_csv('train_dataset.csv')
data = data[['Gender', 'Age', 'openness', 'neuroticism',
'conscientiousness', 'agreeableness', 'extraversion']]
display(data)
输出 :
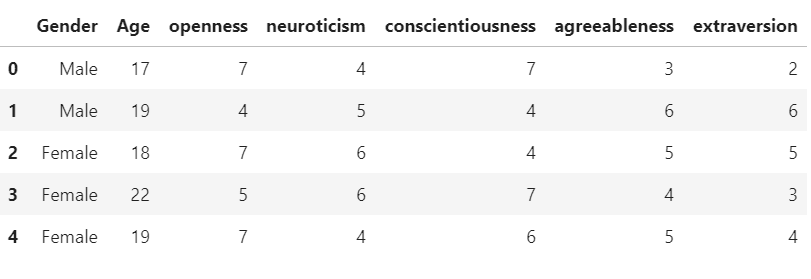
方法 3:为列指定 dtypes
默认情况下,pandas 为所有数值分配 int64 范围(这是最大的可用数据类型)。但是如果数值列中的值小于 int64 范围,则可以使用较小容量的 dtypes 来防止额外的内存分配,因为较大的 dtypes 使用更多内存。
句法:
dataframe =pd.read_csv(‘file_name’,dtype={‘col_1’:‘dtype_value’,‘col_2’:‘dtype_value’})
例子 :
蟒蛇3
import pandas as pd
data = pd.read_csv('train_dataset.csv', dtype={'Age': 'int32'})
print(data.info())
输出 :
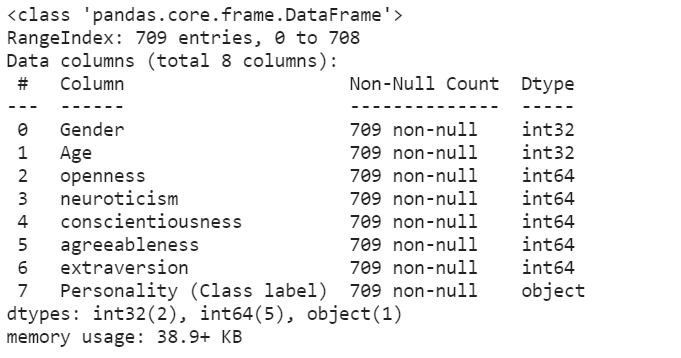
方法四:稀疏数据结构
Pandas Dataframe 可以转换为 Sparse Dataframe,这意味着在表示中省略任何匹配特定值的数据。稀疏 DataFrame 允许更有效的存储。
句法:
dataframe = dataFrame.to_sparse(fill_value=None, kind=’block’)
由于上述数据集中没有空值,让我们用一些空值创建数据帧并将其转换为稀疏数据帧。
例子 :
蟒蛇3
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10000, 4))
df.iloc[:9998] = np.nan
sdf = df.astype(pd.SparseDtype("float", np.nan))
sdf.head()
sdf.dtypes
输出:


方法五:删除未使用的对象
在数据清理/预处理过程中,会创建许多临时数据帧和对象,在使用后应将其删除,以减少使用内存。 Python的 del 关键字主要用于删除Python的对象。
句法:
del object_name
例子 :
蟒蛇3
import pandas as pd
data = pd.read_csv('train_dataset.csv')
del data