将文本文件读入 PySpark 数据帧
在本文中,我们将了解如何在 PySpark Dataframe 中读取文本文件。
有三种方法可以将文本文件读入 PySpark DataFrame。
- 使用 spark.read.text()
- 使用 spark.read.csv()
- 使用 spark.read.format().load()
使用这些,我们可以将目录中的单个文本文件、多个文件和所有文件读取到 Spark DataFrame 和 Dataset 中。
使用的文本文件:

方法一:使用 spark.read.text()
它用于将文本文件加载到 DataFrame 中,其架构以字符串列开头。文本文件中的每一行都是生成的 DataFrame 中的一个新行。使用这种方法,我们还可以一次读取多个文件。
Syntax: spark.read.text(paths)
Parameters: This method accepts the following parameter as mentioned above and described below.
- paths: It is a string, or list of strings, for input path(s).
Returns: DataFrame
示例:使用 spark.read.text() 读取文本文件。
在这里,我们将导入模块并创建一个 spark 会话,然后使用spark.read.text()读取文件,然后创建列并将 txt 文件中的数据拆分为数据帧。
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataFrame").getOrCreate()
df = spark.read.text("output.txt")
df.selectExpr("split(value, ' ') as\
Text_Data_In_Rows_Using_Text").show(4,False)Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.csv("output.txt")
df.selectExpr("split(_c0, ' ')\
as Text_Data_In_Rows_Using_CSV").show(4,False)Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
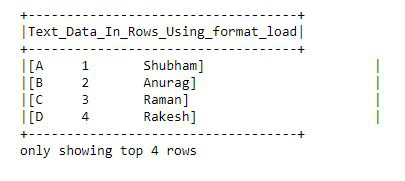
df = spark.read.format("text").load("output.txt")
df.selectExpr("split(value, ' ')\
as Text_Data_In_Rows_Using_format_load").show(4,False)输出:

方法二:使用 spark.read.csv()
它用于将文本文件加载到 DataFrame 中。如果启用了 inferSchema,我们将使用此方法检查输入一次以确定输入模式。为避免一次遍历整个数据,请禁用 inferSchema 选项或使用架构显式指定架构。
Syntax: spark.read.csv(path)
Returns: DataFrame
示例:使用 spark.read.csv() 读取文本文件。
首先,导入模块并创建一个 spark 会话,然后使用 spark.read.csv() 读取文件,然后创建列并将 txt 文件中的数据拆分为数据帧。
蟒蛇3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.csv("output.txt")
df.selectExpr("split(_c0, ' ')\
as Text_Data_In_Rows_Using_CSV").show(4,False)
输出:

方法 3:使用 spark.read.format()
它用于将文本文件加载到 DataFrame 中。 .format()将输入数据源格式指定为“文本”。 .load()从数据源加载数据并返回 DataFrame。
Syntax: spark.read.format(“text”).load(path=None, format=None, schema=None, **options)
Parameters: This method accepts the following parameter as mentioned above and described below.
- paths : It is a string, or list of strings, for input path(s).
- format : It is an optional string for format of the data source. Default to ‘parquet’.
- schema : It is an optional pyspark.sql.types.StructType for the input schema.
- options : all other string options
Returns: DataFrame
示例:使用 spark.read.format() 读取文本文件。
首先,导入模块并创建一个 spark 会话,然后使用spark.read.format()读取文件,然后创建列并将 txt 文件中的数据拆分为数据帧。
蟒蛇3
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.format("text").load("output.txt")
df.selectExpr("split(value, ' ')\
as Text_Data_In_Rows_Using_format_load").show(4,False)
输出: