在 Pandas 列中搜索一个值
先决条件:熊猫
在本文中,我们将讨论如何使用 Pandas 搜索给定特定值的数据框。
使用的函数
- where() - 用于检查数据框的一个或多个条件并相应地返回结果。默认情况下,不满足条件的行填充为 NaN 值。
- dropna() - 此方法允许用户分析和删除具有 Null 值的行/列。在本文中,它用于处理由于不满足特定条件而将值为 NaN 的行的情况。
方法
- 导入模块
- 创建数据
- 遍历列查找特定值
- 如果匹配,请选择
选择特定值和选择具有特定值的行之间存在基本区别。对于后一种情况,要检索的索引必须存储在列表中。这两种情况的实现都包含在本文中:
使用中的数据框:
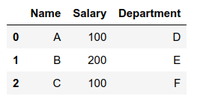
示例 1:选择包含工资为 200 的元组
Python3
import pandas as pd
x = pd.DataFrame([["A", 100, "D"], ["B", 200, "E"], ["C", 100, "F"]],
columns=["Name", "Salary", "Department"])
# Searching in whole column
for i in range(len(x.Name)):
if 200 == x.Salary[i]:
# indx will store the tuple having that
# particular value in column.
indx = i
# below line will print that tuple
x.iloc[indx]Python3
import pandas as pd
x = pd.DataFrame([["A", 100, "D"], ["B", 200, "E"], ["C", 100, "F"]],
columns=[ "Name", "Salary", "Department"])
# initialize the indx as a list
indx = []
# Searching in whole column
for i in range(len(x.Name)):
if 100 == x.Salary[i]:
# indx will store all the tuples having
# that particular value in column.
indx.append(i)
# Final Dataframe having tuples
df = pd.DataFrame()
# this will append all tuples to the final
# dataframe.
for indexes in indx:
df = df.append(x.iloc[indexes])
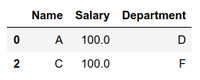
df = x.where(x.Salary == 100)
# It will remove NaN rows.
df.dropna()输出:
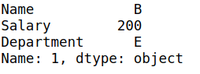
示例 2:搜索薪水为 100 的人员并将输出再次存储在数据帧中。
蟒蛇3
import pandas as pd
x = pd.DataFrame([["A", 100, "D"], ["B", 200, "E"], ["C", 100, "F"]],
columns=[ "Name", "Salary", "Department"])
# initialize the indx as a list
indx = []
# Searching in whole column
for i in range(len(x.Name)):
if 100 == x.Salary[i]:
# indx will store all the tuples having
# that particular value in column.
indx.append(i)
# Final Dataframe having tuples
df = pd.DataFrame()
# this will append all tuples to the final
# dataframe.
for indexes in indx:
df = df.append(x.iloc[indexes])
df = x.where(x.Salary == 100)
# It will remove NaN rows.
df.dropna()
输出: