Python中的单例模式——完整指南
Python中的单例模式是一种设计模式,它允许您在程序的整个生命周期中只创建一个类的实例。使用单例模式有很多好处。其中一些是:
- 限制对共享资源的并发访问。
- 为资源创建全局访问点。
- 在程序的整个生命周期中只创建一个类的实例。
实现单例的不同方式:
单例模式可以通过三种不同的方式实现。它们如下:
- 模块级单例
- 经典单身人士
- 博格·辛格尔顿
模块级单例:
根据定义,所有模块都是单例的。让我们创建一个简单的模块级单例,其中数据在其他模块之间共享。在这里,我们将创建三个Python文件——singleton.py、sample_module1.py 和 sample_module2.py——其中其他示例模块共享来自 singleton.py 的变量。
## singleton.py
shared_variable = "Shared Variable"单例.py
## samplemodule1.py
import singleton
print(singleton.shared_variable)
singleton.shared_variable += "(modified by samplemodule1)"示例模块1.py
##samplemodule2.py
import singleton
print(singleton.shared_variable)示例模块2.py
让我们看看输出。

这里,samplemodule1改变的值也反映在samplemodule2中。
经典单例:
Classic Singleton 仅在目前没有创建实例时才创建实例;否则,它将返回已经创建的实例。我们来看看下面的代码。
Python3
class SingletonClass(object):
def __new__(cls):
if not hasattr(cls, 'instance'):
cls.instance = super(SingletonClass, cls).__new__(cls)
return cls.instance
singleton = SingletonClass()
new_singleton = SingletonClass()
print(singleton is new_singleton)
singleton.singl_variable = "Singleton Variable"
print(new_singleton.singl_variable)Python3
class SingletonClass(object):
def __new__(cls):
if not hasattr(cls, 'instance'):
cls.instance = super(SingletonClass, cls).__new__(cls)
return cls.instance
class SingletonChild(SingletonClass):
pass
singleton = SingletonClass()
child = SingletonChild()
print(child is singleton)
singleton.singl_variable = "Singleton Variable"
print(child.singl_variable)Python3
class BorgSingleton(object):
_shared_borg_state = {}
def __new__(cls, *args, **kwargs):
obj = super(BorgSingleton, cls).__new__(cls, *args, **kwargs)
obj.__dict__ = cls._shared_borg_state
return obj
borg = BorgSingleton()
borg.shared_variable = "Shared Variable"
class ChildBorg(BorgSingleton):
pass
childBorg = ChildBorg()
print(childBorg is borg)
print(childBorg.shared_variable)Python3
class BorgSingleton(object):
_shared_borg_state = {}
def __new__(cls, *args, **kwargs):
obj = super(BorgSingleton, cls).__new__(cls, *args, **kwargs)
obj.__dict__ = cls._shared_borg_state
return obj
borg = BorgSingleton()
borg.shared_variable = "Shared Variable"
class NewChildBorg(BorgSingleton):
_shared_borg_state = {}
newChildBorg = NewChildBorg()
print(newChildBorg.shared_variable)Python3
import httplib2
import os
import re
import threading
import urllib
import urllib.request
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
class CrawlerSingleton(object):
def __new__(cls):
""" creates a singleton object, if it is not created,
or else returns the previous singleton object"""
if not hasattr(cls, 'instance'):
cls.instance = super(CrawlerSingleton, cls).__new__(cls)
return cls.instance
def navigate_site(max_links = 5):
""" navigate the website using BFS algorithm, find links and
arrange them for downloading images """
# singleton instance
parser_crawlersingleton = CrawlerSingleton()
# During the initial stage, url_queue has the main_url.
# Upon parsing the main_url page, new links that belong to the
# same website is added to the url_queue until
# it equals to max _links.
while parser_crawlersingleton.url_queue:
# checks whether it reached the max. link
if len(parser_crawlersingleton.visited_url) == max_links:
return
# pop the url from the queue
url = parser_crawlersingleton.url_queue.pop()
# connect to the web page
http = httplib2.Http()
try:
status, response = http.request(url)
except Exception:
continue
# add the link to download the images
parser_crawlersingleton.visited_url.add(url)
print(url)
# crawl the web page and fetch the links within
# the main page
bs = BeautifulSoup(response, "html.parser")
for link in BeautifulSoup.findAll(bs, 'a'):
link_url = link.get('href')
if not link_url:
continue
# parse the fetched link
parsed = urlparse(link_url)
# skip the link, if it leads to an external page
if parsed.netloc and parsed.netloc != parsed_url.netloc:
continue
scheme = parsed_url.scheme
netloc = parsed.netloc or parsed_url.netloc
path = parsed.path
# construct a full url
link_url = scheme +'://' +netloc + path
# skip, if the link is already added
if link_url in parser_crawlersingleton.visited_url:
continue
# Add the new link fetched,
# so that the while loop continues with next iteration.
parser_crawlersingleton.url_queue = [link_url] +\
parser_crawlersingleton.url_queue
class ParallelDownloader(threading.Thread):
""" Download the images parallelly """
def __init__(self, thread_id, name, counter):
threading.Thread.__init__(self)
self.name = name
def run(self):
print('Starting thread', self.name)
# function to download the images
download_images(self.name)
print('Finished thread', self.name)
def download_images(thread_name):
# singleton instance
singleton = CrawlerSingleton()
# visited_url has a set of URLs.
# Here we will fetch each URL and
# download the images in it.
while singleton.visited_url:
# pop the url to download the images
url = singleton.visited_url.pop()
http = httplib2.Http()
print(thread_name, 'Downloading images from', url)
try:
status, response = http.request(url)
except Exception:
continue
# parse the web page to find all images
bs = BeautifulSoup(response, "html.parser")
# Find all ![]() tags
images = BeautifulSoup.findAll(bs, 'img')
for image in images:
src = image.get('src')
src = urljoin(url, src)
basename = os.path.basename(src)
print('basename:', basename)
if basename != '':
if src not in singleton.image_downloaded:
singleton.image_downloaded.add(src)
print('Downloading', src)
# Download the images to local system
urllib.request.urlretrieve(src, os.path.join('images', basename))
print(thread_name, 'finished downloading images from', url)
def main():
# singleton instance
crwSingltn = CrawlerSingleton()
# adding the url to the queue for parsing
crwSingltn.url_queue = [main_url]
# initializing a set to store all visited URLs
# for downloading images.
crwSingltn.visited_url = set()
# initializing a set to store path of the downloaded images
crwSingltn.image_downloaded = set()
# invoking the method to crawl the website
navigate_site()
## create images directory if not exists
if not os.path.exists('images'):
os.makedirs('images')
thread1 = ParallelDownloader(1, "Thread-1", 1)
thread2 = ParallelDownloader(2, "Thread-2", 2)
# Start new threads
thread1.start()
thread2.start()
if __name__ == "__main__":
main_url = ("https://www.geeksforgeeks.org/")
parsed_url = urlparse(main_url)
main()
tags
images = BeautifulSoup.findAll(bs, 'img')
for image in images:
src = image.get('src')
src = urljoin(url, src)
basename = os.path.basename(src)
print('basename:', basename)
if basename != '':
if src not in singleton.image_downloaded:
singleton.image_downloaded.add(src)
print('Downloading', src)
# Download the images to local system
urllib.request.urlretrieve(src, os.path.join('images', basename))
print(thread_name, 'finished downloading images from', url)
def main():
# singleton instance
crwSingltn = CrawlerSingleton()
# adding the url to the queue for parsing
crwSingltn.url_queue = [main_url]
# initializing a set to store all visited URLs
# for downloading images.
crwSingltn.visited_url = set()
# initializing a set to store path of the downloaded images
crwSingltn.image_downloaded = set()
# invoking the method to crawl the website
navigate_site()
## create images directory if not exists
if not os.path.exists('images'):
os.makedirs('images')
thread1 = ParallelDownloader(1, "Thread-1", 1)
thread2 = ParallelDownloader(2, "Thread-2", 2)
# Start new threads
thread1.start()
thread2.start()
if __name__ == "__main__":
main_url = ("https://www.geeksforgeeks.org/")
parsed_url = urlparse(main_url)
main()True
Singleton Variable在这里,在 __new__ 方法中,我们将检查是否创建了一个实例。如果创建,它将返回实例;否则,它将创建一个新实例。您可以注意到 singleton 和 new_singleton 返回相同的实例并具有相同的变量。
让我们来看看当我们继承一个单例类时会发生什么。
蟒蛇3
class SingletonClass(object):
def __new__(cls):
if not hasattr(cls, 'instance'):
cls.instance = super(SingletonClass, cls).__new__(cls)
return cls.instance
class SingletonChild(SingletonClass):
pass
singleton = SingletonClass()
child = SingletonChild()
print(child is singleton)
singleton.singl_variable = "Singleton Variable"
print(child.singl_variable)
True
Singleton Variable在这里,您可以看到 SingletonChild 具有相同的 SingletonClass 实例并且也共享相同的状态。但是在某些情况下,我们需要一个不同的实例,但应该共享相同的状态。这种状态共享可以使用 Borg 单例来实现。
博格·辛格尔顿:
Borg 单例是Python中的一种设计模式,它允许不同实例的状态共享。让我们看看下面的代码。
蟒蛇3
class BorgSingleton(object):
_shared_borg_state = {}
def __new__(cls, *args, **kwargs):
obj = super(BorgSingleton, cls).__new__(cls, *args, **kwargs)
obj.__dict__ = cls._shared_borg_state
return obj
borg = BorgSingleton()
borg.shared_variable = "Shared Variable"
class ChildBorg(BorgSingleton):
pass
childBorg = ChildBorg()
print(childBorg is borg)
print(childBorg.shared_variable)
False
Shared Variable随着新实例的创建过程,在 __new__ 方法中也定义了一个共享状态。这里使用 shared_borg_state 属性保留共享状态,并将其存储在每个实例的 __dict__ 字典中。
如果你想要一个不同的状态,那么你可以重置 shared_borg_state 属性。让我们看看如何重置共享状态。
蟒蛇3
class BorgSingleton(object):
_shared_borg_state = {}
def __new__(cls, *args, **kwargs):
obj = super(BorgSingleton, cls).__new__(cls, *args, **kwargs)
obj.__dict__ = cls._shared_borg_state
return obj
borg = BorgSingleton()
borg.shared_variable = "Shared Variable"
class NewChildBorg(BorgSingleton):
_shared_borg_state = {}
newChildBorg = NewChildBorg()
print(newChildBorg.shared_variable)
在这里,我们重置了共享状态并尝试访问 shared_variable。让我们看看错误。
Traceback (most recent call last):
File "/home/329d68500c5916767fbaf351710ebb13.py", line 16, in
print(newChildBorg.shared_variable)
AttributeError: 'NewChildBorg' object has no attribute 'shared_variable' 单例用例:
让我们列出一些单例类的用例。它们如下:
- 管理数据库连接
- 全局点访问写入日志消息
- 文件管理器
- 打印后台处理程序
使用经典单例创建一个网络爬虫:
让我们创建一个利用经典单例优势的网络爬虫。在这个实际例子中,爬虫扫描一个网页,获取与同一网站相关联的链接,并下载其中的所有图像。在这里,我们有两个主要类和两个主要功能。
- CrawlerSingleton:这个类是一个经典的单身人士
- ParallelDownloader:此类提供下载图像的线程功能
- 导航站点:该函数抓取网站并获取属于同一网站的链接。最后,它会安排下载图像的链接。
- download_images:该函数抓取页面链接并下载图像。
除了上面的类和函数,我们还使用了两组库来解析网页—— BeautifulSoap 和 HTTP Client 。
看看下面的代码。
注意:在本地机器上执行代码
蟒蛇3
import httplib2
import os
import re
import threading
import urllib
import urllib.request
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
class CrawlerSingleton(object):
def __new__(cls):
""" creates a singleton object, if it is not created,
or else returns the previous singleton object"""
if not hasattr(cls, 'instance'):
cls.instance = super(CrawlerSingleton, cls).__new__(cls)
return cls.instance
def navigate_site(max_links = 5):
""" navigate the website using BFS algorithm, find links and
arrange them for downloading images """
# singleton instance
parser_crawlersingleton = CrawlerSingleton()
# During the initial stage, url_queue has the main_url.
# Upon parsing the main_url page, new links that belong to the
# same website is added to the url_queue until
# it equals to max _links.
while parser_crawlersingleton.url_queue:
# checks whether it reached the max. link
if len(parser_crawlersingleton.visited_url) == max_links:
return
# pop the url from the queue
url = parser_crawlersingleton.url_queue.pop()
# connect to the web page
http = httplib2.Http()
try:
status, response = http.request(url)
except Exception:
continue
# add the link to download the images
parser_crawlersingleton.visited_url.add(url)
print(url)
# crawl the web page and fetch the links within
# the main page
bs = BeautifulSoup(response, "html.parser")
for link in BeautifulSoup.findAll(bs, 'a'):
link_url = link.get('href')
if not link_url:
continue
# parse the fetched link
parsed = urlparse(link_url)
# skip the link, if it leads to an external page
if parsed.netloc and parsed.netloc != parsed_url.netloc:
continue
scheme = parsed_url.scheme
netloc = parsed.netloc or parsed_url.netloc
path = parsed.path
# construct a full url
link_url = scheme +'://' +netloc + path
# skip, if the link is already added
if link_url in parser_crawlersingleton.visited_url:
continue
# Add the new link fetched,
# so that the while loop continues with next iteration.
parser_crawlersingleton.url_queue = [link_url] +\
parser_crawlersingleton.url_queue
class ParallelDownloader(threading.Thread):
""" Download the images parallelly """
def __init__(self, thread_id, name, counter):
threading.Thread.__init__(self)
self.name = name
def run(self):
print('Starting thread', self.name)
# function to download the images
download_images(self.name)
print('Finished thread', self.name)
def download_images(thread_name):
# singleton instance
singleton = CrawlerSingleton()
# visited_url has a set of URLs.
# Here we will fetch each URL and
# download the images in it.
while singleton.visited_url:
# pop the url to download the images
url = singleton.visited_url.pop()
http = httplib2.Http()
print(thread_name, 'Downloading images from', url)
try:
status, response = http.request(url)
except Exception:
continue
# parse the web page to find all images
bs = BeautifulSoup(response, "html.parser")
# Find all ![]() tags
images = BeautifulSoup.findAll(bs, 'img')
for image in images:
src = image.get('src')
src = urljoin(url, src)
basename = os.path.basename(src)
print('basename:', basename)
if basename != '':
if src not in singleton.image_downloaded:
singleton.image_downloaded.add(src)
print('Downloading', src)
# Download the images to local system
urllib.request.urlretrieve(src, os.path.join('images', basename))
print(thread_name, 'finished downloading images from', url)
def main():
# singleton instance
crwSingltn = CrawlerSingleton()
# adding the url to the queue for parsing
crwSingltn.url_queue = [main_url]
# initializing a set to store all visited URLs
# for downloading images.
crwSingltn.visited_url = set()
# initializing a set to store path of the downloaded images
crwSingltn.image_downloaded = set()
# invoking the method to crawl the website
navigate_site()
## create images directory if not exists
if not os.path.exists('images'):
os.makedirs('images')
thread1 = ParallelDownloader(1, "Thread-1", 1)
thread2 = ParallelDownloader(2, "Thread-2", 2)
# Start new threads
thread1.start()
thread2.start()
if __name__ == "__main__":
main_url = ("https://www.geeksforgeeks.org/")
parsed_url = urlparse(main_url)
main()
tags
images = BeautifulSoup.findAll(bs, 'img')
for image in images:
src = image.get('src')
src = urljoin(url, src)
basename = os.path.basename(src)
print('basename:', basename)
if basename != '':
if src not in singleton.image_downloaded:
singleton.image_downloaded.add(src)
print('Downloading', src)
# Download the images to local system
urllib.request.urlretrieve(src, os.path.join('images', basename))
print(thread_name, 'finished downloading images from', url)
def main():
# singleton instance
crwSingltn = CrawlerSingleton()
# adding the url to the queue for parsing
crwSingltn.url_queue = [main_url]
# initializing a set to store all visited URLs
# for downloading images.
crwSingltn.visited_url = set()
# initializing a set to store path of the downloaded images
crwSingltn.image_downloaded = set()
# invoking the method to crawl the website
navigate_site()
## create images directory if not exists
if not os.path.exists('images'):
os.makedirs('images')
thread1 = ParallelDownloader(1, "Thread-1", 1)
thread2 = ParallelDownloader(2, "Thread-2", 2)
# Start new threads
thread1.start()
thread2.start()
if __name__ == "__main__":
main_url = ("https://www.geeksforgeeks.org/")
parsed_url = urlparse(main_url)
main()
让我们看看下载的图像和Python shell 输出。

下载的图像
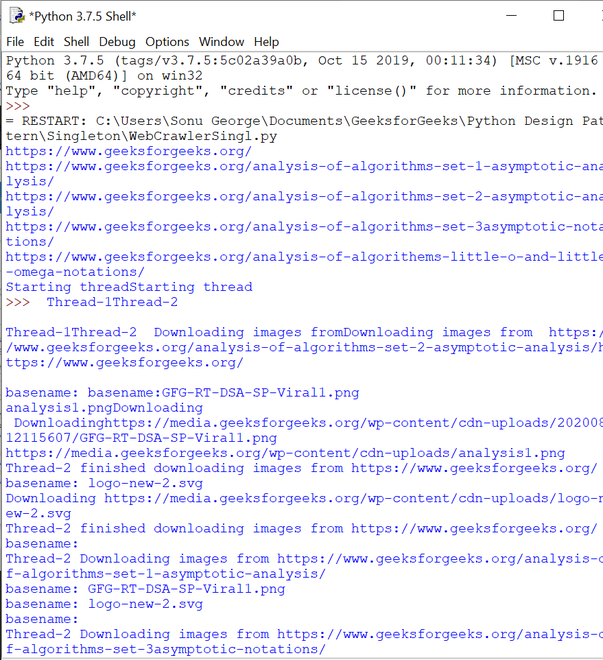
Python Shell 输出
概括:
单例模式是Python中的一种设计模式,它将类的实例化限制为一个对象。它可以限制对共享资源的并发访问,还有助于为资源创建全局访问点。