使用Python从网站上抓取表格 – Selenium
Selenium是获取网站、执行各种操作或从网站获取数据的自动化软件测试工具。它主要是为了通过自动化 Web 应用程序来简化测试工作而开发的。如今,除了用于测试之外,它还可以用于使繁琐的工作变得有趣。你知道在Selenium的帮助下,你还可以从网站上的表格中提取数据吗?答案是肯定的,我们可以轻松地从网站上抓取表格数据。这篇文章解释了从网站上抓取表格数据需要做什么。
应遵循的方法:
让我们考虑包含表格的简单 HTML 程序,以了解从网站上抓取表格的方法。
HTML
Selenium Table
Name
Class
Vinayak
12
Ishita
10
Python
# Python program to scrape table from website
# import libraries selenium and time
from selenium import webdriver
from time import sleep
# Create webdriver object
driver = webdriver.Chrome(
executable_path="C:\selenium\chromedriver_win32\chromedriver.exe")
# Get the website
driver.get(
"https://www.geeksforgeeks.org/find_element_by_link_text-driver-method-selenium-python/")
# Make Python sleep for some time
sleep(2)
# Obtain the number of rows in body
rows = 1+len(driver.find_elements_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr"))
# Obtain the number of columns in table
cols = len(driver.find_elements_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr[1]/td"))
# Print rows and columns
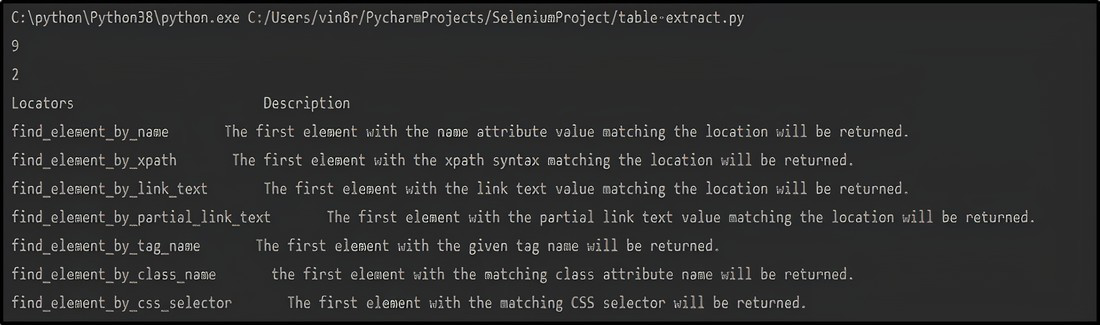
print(rows)
print(cols)
# Printing the table headers
print("Locators "+" Description")
# Printing the data of the table
for r in range(2, rows+1):
for p in range(1, cols+1):
# obtaining the text from each column of the table
value = driver.find_element_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr["+str(r)+"]/td["+str(p)+"]").text
print(value, end=' ')
print()浏览器输出:

请按照以下步骤操作:
创建 HTML 文件后,您可以按照以下步骤自行从网站的表格中提取数据。
- 首先声明web驱动
driver=webdriver.Chrome(executable_path=”Declare the path where web driver is installed”)
- 现在,打开要从中获取表格数据的网站
driver.get("Specify the path of the website")- 接下来,您需要在表中查找行
rows=1+len(driver.find_elements_by_xpath("Specify the altered path"))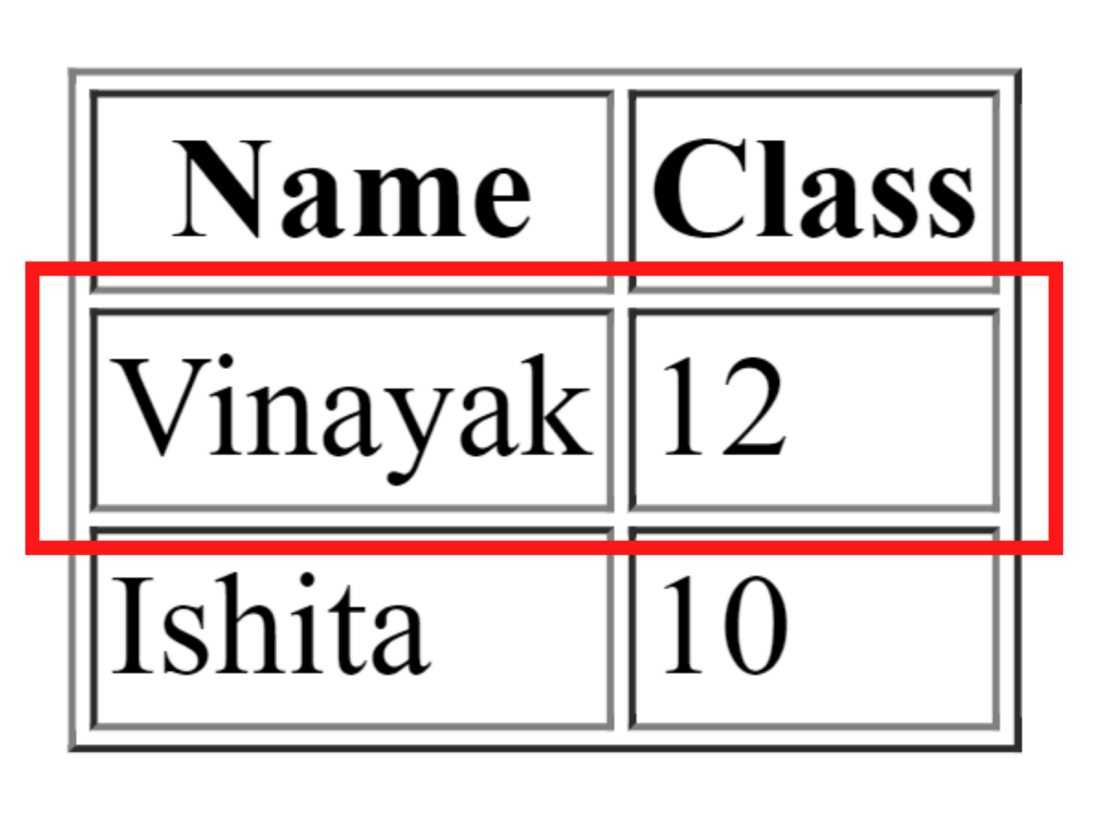
在这里,修改后的 xpath 意味着如果第 1 行的 xpath 是/html/body/table/tbody/tr[1]那么,修改后的 xpath 将是/html/body/table/tbody/tr这里需要做的是删除表行的索引值。
注意:请记住将表头的行值加 1,因为在计算表行时不包括在内。
- 此外,查找表中的列
cols=len(driver.find_elements_by_xpath("Specify the altered path"))
在这里,更改的 xpath 意味着如果显示输出 Vinayak 的列的 xpath 是/html/body/table/tbody/tr[1]/td[1]那么,更改的 xpath 将是/html/body/table/tbody/tr /td这里需要做的就是去掉表行和表数据的索引值。
- 此外,从表体的每一列获取数据
for r in range(2, rows+1):
for p in range(1, cols+1):
value = driver.find_element_by_xpath("Specify the altered path").text
在这里,更改的 xpath 意味着如果显示输出 Vinayak 的列的 xpath 是/html/body/table/tbody/tr[1]/td[1]那么,更改的 xpath 将是/html/body/table/tbody/tr [“+str(r)+”]/td[“+str(p)+”]这里需要做的就是为表行和表的索引值加上str(r)和str(p)数据分别。
- 最后,打印表的数据
print(value, end=' ')
print() 如何从Selenium的网站上抓取表格数据?
正如我们现在看到的,在使用自动化工具Selenium时提取表数据的方法。现在,让我们看看来自网站的报废表数据的完整示例。我们将使用该网站在下面给出的程序中提取其表格数据。
Python
# Python program to scrape table from website
# import libraries selenium and time
from selenium import webdriver
from time import sleep
# Create webdriver object
driver = webdriver.Chrome(
executable_path="C:\selenium\chromedriver_win32\chromedriver.exe")
# Get the website
driver.get(
"https://www.geeksforgeeks.org/find_element_by_link_text-driver-method-selenium-python/")
# Make Python sleep for some time
sleep(2)
# Obtain the number of rows in body
rows = 1+len(driver.find_elements_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr"))
# Obtain the number of columns in table
cols = len(driver.find_elements_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr[1]/td"))
# Print rows and columns
print(rows)
print(cols)
# Printing the table headers
print("Locators "+" Description")
# Printing the data of the table
for r in range(2, rows+1):
for p in range(1, cols+1):
# obtaining the text from each column of the table
value = driver.find_element_by_xpath(
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr["+str(r)+"]/td["+str(p)+"]").text
print(value, end=' ')
print()
此外,使用以下命令运行Python代码:
python run.py输出: