Linux 中的 hexdump 命令及示例
Linux 中的hd或hexdump命令用于过滤和显示指定的文件,或以人类可读的指定格式的标准输入。例如,如果要查看程序的可执行代码,可以使用hexdump来执行此操作。
句法:
hd [OPTIONS...] [FILES...]选项:
- -b :一字节八进制显示。以十六进制显示输入偏移量,后跟十六进制分隔、三列、零填充、八进制、每行的输入数据字节。
句法:
hd -b input.txt
输出的第一列表示文件中的输入偏移量。 - -c :一字节字符显示。以十六进制显示输入偏移量,然后是每行输入数据的十六个空格分隔、三列、空格填充的字符。
句法:
hd -c input.txt
- -C :规范的十六进制+ASCII 显示。以十六进制显示输入偏移量,后跟十六个空格分隔的两列十六进制字节,后跟以“|”括起来的 %_p 格式相同的十六个字节字符。
句法:
hexdump -C input.txt
- -d:两字节十进制显示。以十六进制显示输入偏移量,后跟八个空格分隔、五列、零填充、两字节单位的输入数据,无符号十进制,每行。
句法:
hd -d input.txt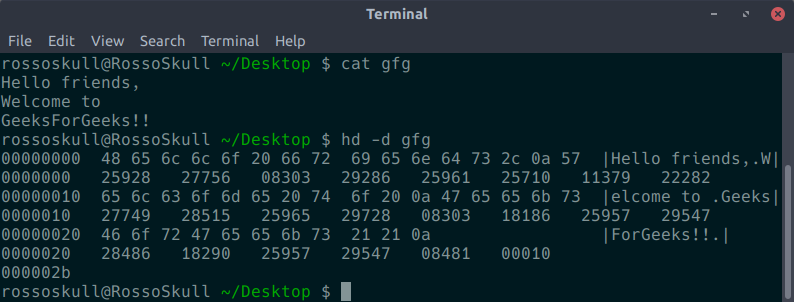
- -n 长度:其中长度是一个整数。仅解释输出的“长度”字节。
句法:
hd -n length input.txt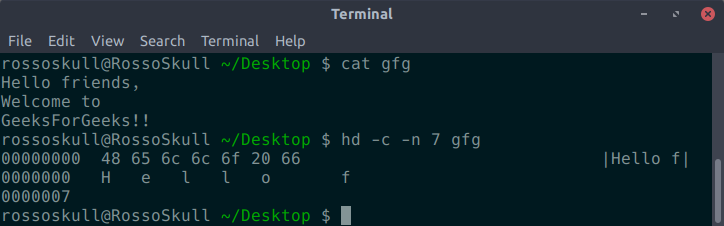
- -o:两字节八进制显示。以十六进制显示输入偏移量,后跟八个空格分隔、六列、零填充、两个字节的输入数据量,以八进制表示,每行。
句法:
hd -o input.txt
- -s offset :从输入的开头跳过“偏移”字节。默认情况下,偏移量被解释为十进制数。前导 0x 或 0X,offset 被解释为十六进制数,否则,前导 0,offset 被解释为八进制数。将字符b、k 或 m 附加到 offset 会使其分别被解释为 512、1024 或 1048576 的倍数。
句法:
hd -s offset input.txt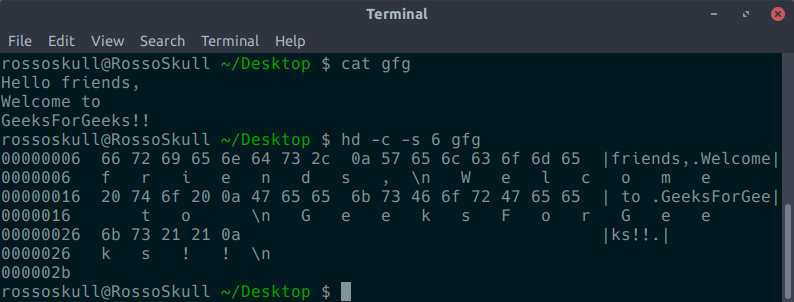
如您所见,在输出中,跳过了前 6 个字符,即 'Hello '。 - -v : 使hexdump 显示所有输入数据。如果没有 -v 选项,与前一组输出行(输入偏移除外)相同的任意数量的输出行组将替换为由单个星号组成的行。
句法:
hd -v input.txt当我们使用
-c标志显示输出时,我们将看到此选项的使用。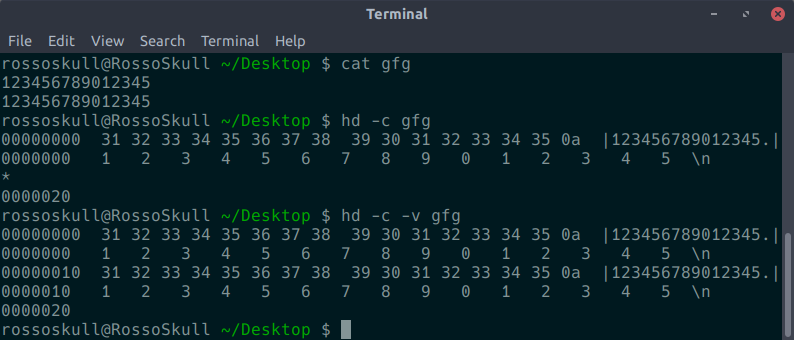
如您所见,当我们第一次使用
hd时,没有 -v,当出现类似的输出时,它会打印出一个星号 (*)。但是当我们传递一个-v标志时,我们得到了所有的输出行。 - -x :两字节十六进制显示。以十六进制显示输入偏移量,后跟八位、空格分隔、四列、零填充、两字节的输入数据量,以十六进制表示,每行。
句法:
hd -x input.txt