Python中Set的内部工作
Python中的 Set及其工作Set 可以定义为项目的集合。在Python中,这些基本上用于包括成员资格测试和消除重复条目。这里使用的数据结构是散列,这是一种在平均 O(1) 中执行插入、删除和遍历的流行技术。 Hash Table 上的操作有些类似于 Linked List。 Python中的集合是删除了重复元素的无序列表。
集合的基本方法是:-
创建集合:- 在Python中,集合是通过 set()函数创建的。将创建一个空列表。请注意,不能通过 {} 创建空 Set,它会创建字典。
检查项目是否在 :此操作的时间复杂度平均为 O(1)。然而,在最坏的情况下,它可能变成 O(n)。
添加元素:- set 中的插入是通过 set.add()函数完成的,其中创建适当的记录值以存储在哈希表中。与检查项目相同,即平均 O(1)。然而,在最坏的情况下,它可能变成 O(n)。
Union :- 可以使用 union()函数或 | 合并两个集合运算符。访问和遍历这两个哈希表值,并对它们执行合并操作以组合元素,同时删除重复项。其时间复杂度为 O(len(s1) + len(s2)),其中 s1 和 s2 是需要合并的两个集合。
Intersection :- 这可以通过 intersection() 或 &运算符来完成。公共元素被选中。它们类似于对哈希列表的迭代并在两个表上组合相同的值。其时间复杂度为 O(min(len(s1), len(s2)),其中 s1 和 s2 是需要合并的两个集合。
差异:- 找出集合之间的差异。类似于在链表中查找差异。这是通过 difference() 或 – 运算符完成的。求差 s1 – s2 的时间复杂度为 O(len(s1))
对称差异:- 在两个集合中查找除公共元素外的元素。使用 ^运算符。 s1^s2 的时间复杂度为 O(len(s1))
Symmetric Difference Update :返回一个包含两个集合的对称差的新集合。时间复杂度为 O(len(s2)) clear :- 清除集合或哈希表。
时间复杂度来源: Python Wiki
如果多个值存在于同一索引位置,则将该值附加到该索引位置,以形成链接列表。其中,CPython 集是使用带有虚拟变量的字典来实现的,其中键是成员集,对时间复杂度进行了更大的优化。设置实施:- 
在单个 HashTable 上设置许多操作:- 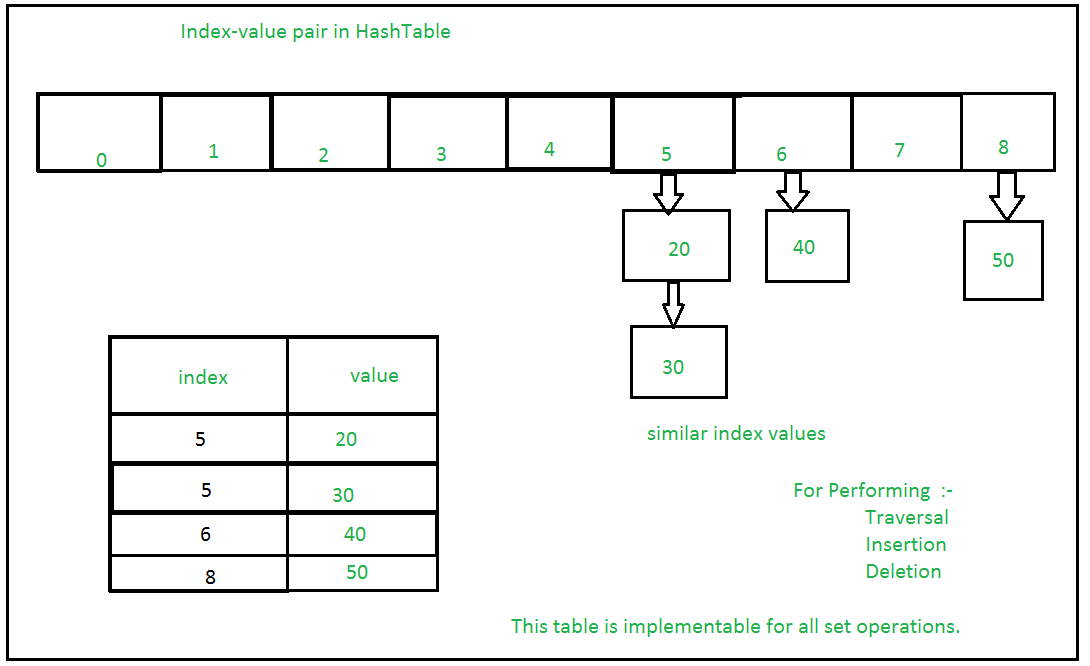 例子:
例子:
# empty set, avoid using {} in creating set or dictionary is created
x = set()
# set {'e', 'h', 'l', 'o'} is created in unordered way
B = set('hello')
# set{'a', 'c', 'd', 'b', 'e', 'f', 'g'} is created
A = set('abcdefg')
# set{'a', 'b', 'h', 'c', 'd', 'e', 'f', 'g'}
A.add('h')
fruit ={'orange', 'banana', 'pear', 'apple'}
# True fast membership testing in sets
'pear' in fruit
'mango' in fruit # False
A == B # A is equivalent to B
A != B # A is not equivalent to B
A <= B # A is subset of B A = B
A > B # A is proper superset of B
A | B # the union of A and B
A & B # the intersection of A and B
A - B # the set of elements in A but not B
A ˆ B # the symmetric difference
a = {x for x in A if x not in 'abc'} # Set Comprehension