在Python中读取和写入 XML 文件
可扩展标记语言( Extensible Markup Language ),通常称为 XML,是一种专门设计为易于人类和计算机共同解释的语言。该语言定义了一组规则,用于以特定格式对文档进行编码。在本文中,已经描述了在Python中读取和写入 XML 文件的方法。
注意:通常,从 XML 文件读取数据并分析其逻辑组件的过程称为解析。因此,当我们提到读取 xml 文件时,我们指的是解析 XML 文档。
在本文中,我们将介绍两个可用于 xml 解析的库。他们是:
- BeautifulSoup 与 lxml xml 解析器一起使用
- 元素树库。
将 BeautifulSoup 与 lxml 解析器一起使用
为了读取和写入 xml 文件,我们将使用名为 BeautifulSoup 的Python库。为了安装库,在终端中输入以下命令。
pip install beautifulsoup4Beautiful Soup 支持 Python 标准库中包含的 HTML 解析器,但它也支持许多第三方Python解析器。一种是 lxml 解析器(用于解析 XML/HTML 文档)。可以通过在操作系统的命令处理器中运行以下命令来安装 lxml:
pip install lxml首先,我们将学习如何读取 XML 文件。我们还将解析存储在其中的数据。稍后我们将学习如何创建 XML 文件并向其写入数据。
从 XML 文件中读取数据
解析 xml 文件需要两个步骤:-
- 查找标签
- 从标签中提取
例子:
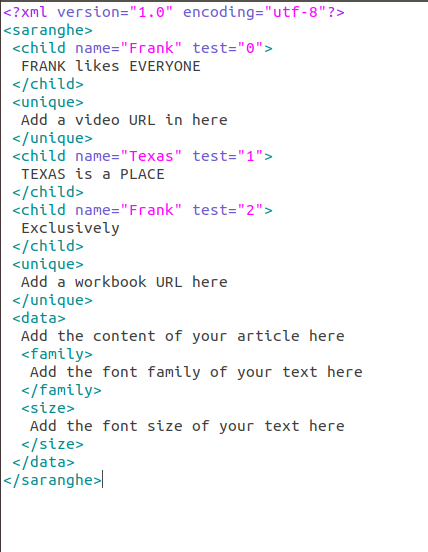
使用的 XML 文件:
Python3
from bs4 import BeautifulSoup
# Reading the data inside the xml
# file to a variable under the name
# data
with open('dict.xml', 'r') as f:
data = f.read()
# Passing the stored data inside
# the beautifulsoup parser, storing
# the returned object
Bs_data = BeautifulSoup(data, "xml")
# Finding all instances of tag
# `unique`
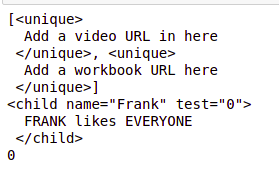
b_unique = Bs_data.find_all('unique')
print(b_unique)
# Using find() to extract attributes
# of the first instance of the tag
b_name = Bs_data.find('child', {'name':'Frank'})
print(b_name)
# Extracting the data stored in a
# specific attribute of the
# `child` tag
value = b_name.get('test')
print(value)Python3
from bs4 import BeautifulSoup
# Reading data from the xml file
with open('dict.xml', 'r') as f:
data = f.read()
# Passing the data of the xml
# file to the xml parser of
# beautifulsoup
bs_data = BeautifulSoup(data, 'xml')
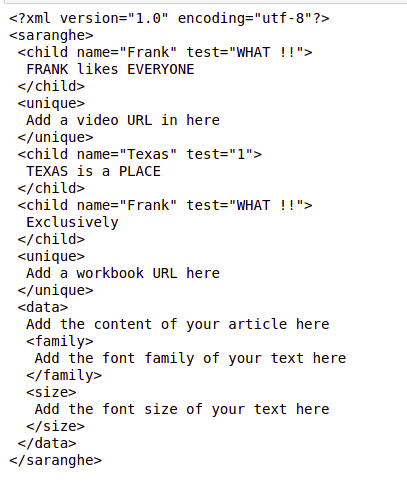
# A loop for replacing the value
# of attribute `test` to WHAT !!
# The tag is found by the clause
# `bs_data.find_all('child', {'name':'Frank'})`
for tag in bs_data.find_all('child', {'name':'Frank'}):
tag['test'] = "WHAT !!"
# Output the contents of the
# modified xml file
print(bs_data.prettify())Python3
# importing element tree
# under the alias of ET
import xml.etree.ElementTree as ET
# Passing the path of the
# xml document to enable the
# parsing process
tree = ET.parse('dict.xml')
# getting the parent tag of
# the xml document
root = tree.getroot()
# printing the root (parent) tag
# of the xml document, along with
# its memory location
print(root)
# printing the attributes of the
# first tag from the parent
print(root[0].attrib)
# printing the text contained within
# first subtag of the 5th tag from
# the parent
print(root[5][0].text)Python3
import xml.etree.ElementTree as ET
# This is the parent (root) tag
# onto which other tags would be
# created
data = ET.Element('chess')
# Adding a subtag named `Opening`
# inside our root tag
element1 = ET.SubElement(data, 'Opening')
# Adding subtags under the `Opening`
# subtag
s_elem1 = ET.SubElement(element1, 'E4')
s_elem2 = ET.SubElement(element1, 'D4')
# Adding attributes to the tags under
# `items`
s_elem1.set('type', 'Accepted')
s_elem2.set('type', 'Declined')
# Adding text between the `E4` and `D5`
# subtag
s_elem1.text = "King's Gambit Accepted"
s_elem2.text = "Queen's Gambit Declined"
# Converting the xml data to byte object,
# for allowing flushing data to file
# stream
b_xml = ET.tostring(data)
# Opening a file under the name `items2.xml`,
# with operation mode `wb` (write + binary)
with open("GFG.xml", "wb") as f:
f.write(b_xml)输出:
编写 XML 文件
编写 xml 文件是一个原始过程,原因是 xml 文件没有以特殊方式编码。修改 xml 文档的各个部分首先需要对其进行解析。在下面的代码中,我们将修改上述 xml 文档的某些部分。
例子:
Python3
from bs4 import BeautifulSoup
# Reading data from the xml file
with open('dict.xml', 'r') as f:
data = f.read()
# Passing the data of the xml
# file to the xml parser of
# beautifulsoup
bs_data = BeautifulSoup(data, 'xml')
# A loop for replacing the value
# of attribute `test` to WHAT !!
# The tag is found by the clause
# `bs_data.find_all('child', {'name':'Frank'})`
for tag in bs_data.find_all('child', {'name':'Frank'}):
tag['test'] = "WHAT !!"
# Output the contents of the
# modified xml file
print(bs_data.prettify())
输出:
使用元素
Elementree 模块为我们提供了大量用于操作 XML 文件的工具。它最好的部分是它包含在标准 Python 的内置库中。因此,不必为此安装任何外部模块。由于 xmlformat 是一种固有的分层数据格式,因此用树来表示它要容易得多。该模块提供 ElementTree 提供将整个 XML 文档表示为单个树的方法。
在后面的示例中,我们将了解在 XML 文件中读取和写入数据的离散方法。
读取 XML 文件
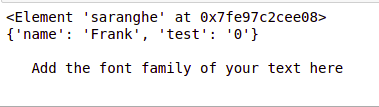
要使用 ElementTree 读取 XML 文件,首先,我们导入在 xml 库中找到的 ElementTree 类,名称为 ET(通用约定)。然后将 xml 文件的文件名传递给 ElementTree.parse() 方法,以启用对我们的 xml 文件的解析。然后使用 getroot() 获取我们 xml 文件的根(父标签)。然后显示(打印)我们的 xml 文件的根标签(非显式方式)。然后使用 root[0].attrib 显示我们父标签的子标签的属性。 root[0] 用于父根的第一个标签,attrib 用于获取它的属性。然后我们显示包含在标签根的第 5 个子标签的第 1 个子标签内的文本。
例子:
Python3
# importing element tree
# under the alias of ET
import xml.etree.ElementTree as ET
# Passing the path of the
# xml document to enable the
# parsing process
tree = ET.parse('dict.xml')
# getting the parent tag of
# the xml document
root = tree.getroot()
# printing the root (parent) tag
# of the xml document, along with
# its memory location
print(root)
# printing the attributes of the
# first tag from the parent
print(root[0].attrib)
# printing the text contained within
# first subtag of the 5th tag from
# the parent
print(root[5][0].text)
输出:
编写 XML 文件
现在,我们将看看一些可用于在 xml 文档上写入数据的方法。在本例中,我们将从头开始创建一个 xml 文件。
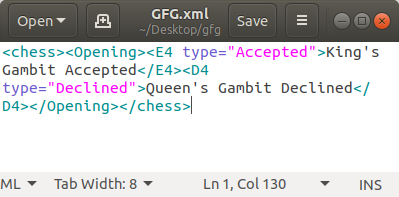
为此,首先,我们使用命令 ET.Element('chess') 在chess名称下创建一个根(父)标签。所有标签都将落在该标签之下,即一旦定义了根标签,就可以在其下创建其他子元素。然后我们使用命令 ET.SubElement() 在chess标签内创建了一个名为Opening的子标签/子元素。然后我们在名为E4和D4的标签Opening下创建了另外两个子标签。然后我们使用 set() 为E4和D4标签添加属性,set() 是 SubElement() 中的一个方法,用于定义标签的属性。然后我们使用在 SubElement函数中找到的属性文本在E4和D4标记之间添加文本。最后,我们使用命令 ET.tostring() 将我们正在创建的内容的数据类型从 'xml.etree.ElementTree.Element' 转换为字节对象(即使函数名称在某些实现中是 tostring() 它转换数据类型为 `bytes` 而不是 `str`)。最后,我们将数据刷新到名为 gameofsquares.xml 的文件中,该文件以 `wb` 模式打开,允许向其写入二进制数据。最后,我们将数据保存到我们的文件中。
例子:
Python3
import xml.etree.ElementTree as ET
# This is the parent (root) tag
# onto which other tags would be
# created
data = ET.Element('chess')
# Adding a subtag named `Opening`
# inside our root tag
element1 = ET.SubElement(data, 'Opening')
# Adding subtags under the `Opening`
# subtag
s_elem1 = ET.SubElement(element1, 'E4')
s_elem2 = ET.SubElement(element1, 'D4')
# Adding attributes to the tags under
# `items`
s_elem1.set('type', 'Accepted')
s_elem2.set('type', 'Declined')
# Adding text between the `E4` and `D5`
# subtag
s_elem1.text = "King's Gambit Accepted"
s_elem2.text = "Queen's Gambit Declined"
# Converting the xml data to byte object,
# for allowing flushing data to file
# stream
b_xml = ET.tostring(data)
# Opening a file under the name `items2.xml`,
# with operation mode `wb` (write + binary)
with open("GFG.xml", "wb") as f:
f.write(b_xml)
输出: