数据挖掘中的冗余和相关性
先决条件:卡方检验、协方差和相关
什么是数据冗余?
在数据挖掘中的数据集成过程中,会使用各种数据存储。这会导致数据冗余的问题。如果一个属性(数据集的列或特征)可以从任何其他属性或属性集导出,则称为冗余。属性或维度命名的不一致也会导致数据集的冗余。
例子 -
我们有一个具有三个属性的数据集- person_name , is_male , is_female 。
- 如果对应的人是男性,则
is_male - 如果对应的人是女性,则
is_female
在分析一个事实,如果一个人不是男性(即
is_male是 0 对应于person_name ),那么这个人肯定是一个女性(因为输出类中只有两个值 - 男性和女性)。这意味着这两个属性高度相关,一个属性可以决定另一个。因此,这些属性之一变得多余。因此,可以删除这两个属性之一而不会丢失任何信息。检测数据冗余 –
可以使用以下方法检测冗余
- χ 2检验(用于名义数据或分类或定性数据)
- 相关系数和协方差(用于数值数据或定量数据)
χ 2名义数据检验 –
这个测试是在名义数据上进行的。假设一个数据集中有两个属性 A 和 B。制作一个列联表来表示数据元组。
本次测试使用的公式为:
其中观察值是实际计数,预期值是从列联表联合事件中获得的计数。χ 2检验 A 和 B 独立的假设。如果这个假设可以被拒绝,我们可以说 A 和 B 是统计相关的,可以丢弃其中一个(A 或 B)。
数值数据的相关系数 -
此测试用于数字数据。在这种情况下,属性(例如 A 和 B)之间的相关性由Pearson 的乘积矩系数计算,也称为相关系数
使用的公式为: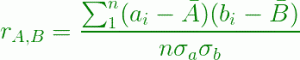
其中 n 是元组的数量, a i , b i分别是元组 i 中 A 和 B 的值。结论:相关系数越高,属性相关性越强,可以丢弃其中一个(A 或 B)。如果相关常数为 0,则属性是独立的,如果为负,则一个属性会阻碍另一个属性,即如果一个属性的值增加,则其他属性的值减少。