将 Scrapy Python输出写入 JSON 文件
在本文中,我们将看到如何在Python中将 scrapy 输出写入 JSON 文件。
使用scrapy命令行shell
这是将数据保存到 JSON 的最简单方法是使用以下命令:
scrapy crawl -O .json 这将生成一个文件,其提供的文件名包含所有抓取的数据。
请注意,在命令行中使用-O 会覆盖任何具有该名称的现有文件,而使用-o会将新内容附加到现有文件中。但是,附加到 JSON 文件会使文件内容成为无效的 JSON。因此,使用以下命令将数据附加到现有文件。
scrapy crawl -o .jl 注意: .jl 表示 JSON 行格式。
分步实施:
第 1 步:创建项目
现在在scrapy中启动一个新项目,使用以下命令
scrapy startproject tutorial这将创建一个包含以下内容的目录:

使用以下命令移动到我们创建的教程目录:
cd tutorial第 2 步:创建蜘蛛(tutorial/spider/quotes_spider.py)
蜘蛛是用户定义的程序,scrapy 用来从网站上抓取信息。这是我们Spider的代码。在你的项目中的tutorial/spiders目录下创建一个名为quotes_spider.py 的文件:
Python3
import scrapy
class QuotesSpider(scrapy.Spider):
# name of variable should be 'name' only
name = "quotes"
# urls from which will be used to extract information
# list should be named 'start_urls' only
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
# handle the response downloaded for each of the
# requests made should be named 'parse' only
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}这是一个简单的蜘蛛程序,用于从网站获取报价、作者姓名和标签。
第 5 步:运行程序
要运行程序并将乱写的数据保存到 JSON,请使用:
scrapy crawl quotes -O quotes.json
我们可以看到在我们的项目结构中已经创建了一个文件quotes.json ,这个文件包含了所有抓取的数据。
JSON 输出:
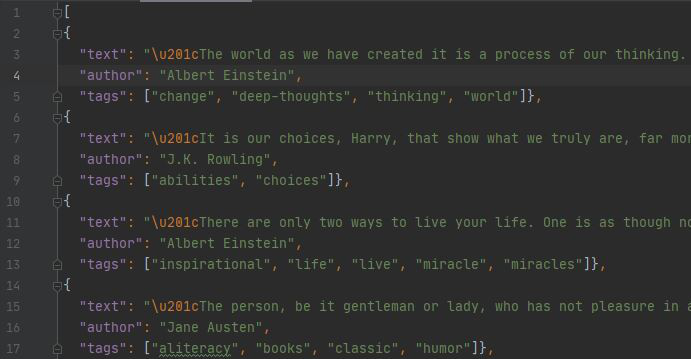
这些只是我们的蜘蛛抓取的quotes.json 文件的许多引号中的一小部分。