Python| Selenium中的 page_source 方法
page_source方法用于检索用户当前访问的网页的页面源。此方法主要用于在页面源中查找某些内容,例如查找任何数据或关键字。
页面源:源代码/页面源是任何网页背后的编程。
句法 :
driver.page_source
争论 :
它不需要争论。
返回值:
它以字符串格式返回页面源。
代码 1。
# importing webdriver from selenium
from selenium import webdriver
# Here Chrome will be used
driver = webdriver.Chrome()
# URL of the website
url = "https://www.geeksforgeeks.org/"
# Opening the URL
driver.get(url)
# Getting current URL source code
get_source = driver.page_source
# Printing the URL
print(get_source)
输出:此代码将打印“https://www.geeksforgeeks.org/”的源代码。
代码 2.当没有打开网页时。
# importing webdriver from selenium
from selenium import webdriver
# Here Chrome will be used
driver = webdriver.Chrome()
# Getting current URL source code
get_source = driver.page_source
# Printing the URL
print(get_source)
输出 : 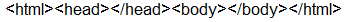
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。