在Python中使用来自 books.toscrape 的 Beautifulsoup 的废书
Web Scraping 是一种从网站中提取大量数据的技术,其中提取的数据保存在您计算机上的本地文件中。最简单的 Web Scrapping 形式是手动将数据从网页复制并粘贴到文本文件或电子表格中。有时这是网站设置障碍的唯一解决方案。但在大多数情况下,需要大量的数据,人类很难抓取。因此,我们有 Web Scrapping 工具来自动化这个过程。 BeautifulSoup就是这样一种 Web Scraping 工具。
BeautifulSoup是一个Python Web Scrapping 库,用于提取数据并解析 HTML 和 XML 文件。要安装 BeautifulSoup,请在终端中键入以下命令。
pip install BeautifulSoup4 BeautifulSoup 是一个 HTML 解析工具,但我们需要一个 web 客户端来从互联网上获取一些东西。
这可以通过使用包urllib在Python中实现。
在本文中,我们的任务是——
- 收集产品名称和价格。
- 以 .csv 格式保存收集的数据。
例如,我们将从以下网站收集书名和价格:BookToScrape
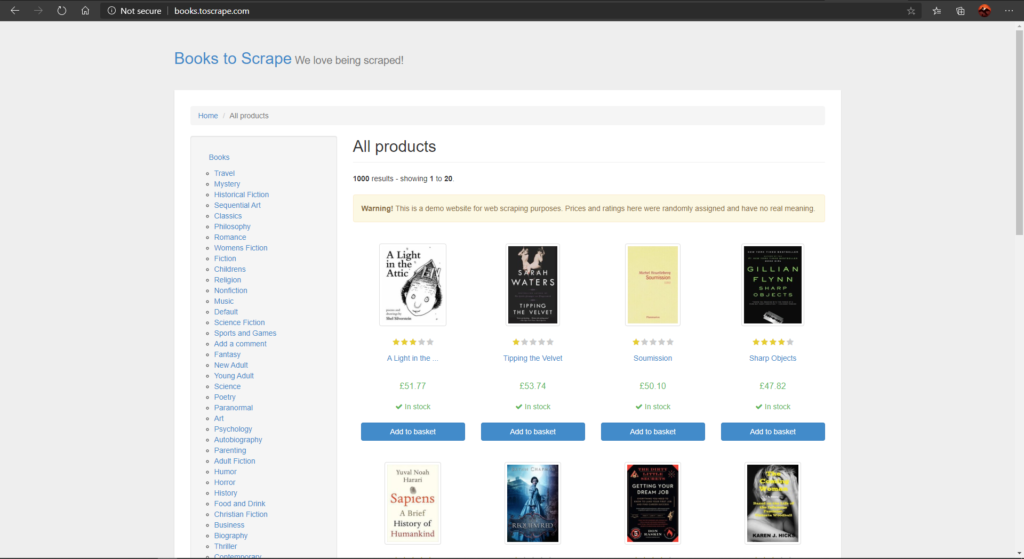
BooksToScrape 网站,第一页包含所有产品
方法
- 导入库:BeautifulSoup 和 urllib。
- 使用 urllib 读取 HTML 链接。
- 允许使用 Beautiful Soup 解析链接。
- 查找包含该特定网页的所有产品的标签并将其提取。
- 查找显示书名和价格的标签并提取它。
- 提取所有信息后,打印所有内容并将其保存在 csv 文件中。

所有书籍及其基础信息。
下面是实现。
Python3
# import web grabbing client and
# HTML parser
from urllib.request import urlopen as uReq
from bs4 import BeautifulSoup as soup
# variable to store website link as string
myurl = 'http://books.toscrape.com/index.html'
# grab website and store in variable uclient
uClient = uReq(myurl)
# read and close HTML
page_html = uClient.read()
uClient.close()
# call BeautifulSoup for parsing
page_soup = soup(page_html, "html.parser")
# grabs all the products under list tag
bookshelf = page_soup.findAll(
"li", {"class": "col-xs-6 col-sm-4 col-md-3 col-lg-3"})
# create csv file of all products
filename = ("Books.csv")
f = open(filename, "w")
headers = "Book title, Price\n"
f.write(headers)
for books in bookshelf:
# collect title of all books
book_title = books.h3.a["title"]
# collect book price of all books
book_price = books.findAll("p", {"class": "price_color"})
price = book_price[0].text.strip()
print("Title of the book :" + book_title)
print("Price of the book :" + price)
f.write(book_title + "," + price+"\n")
f.close()输出 :

CSV 文件:

我们来解释一下上面的代码。在此示例中,一本书及其信息包含在
- findAll()函数查找所有带有名为“col-xs-6 col-sm-4 col-md-3 col-lg-3”的类(如果其 ID 可以是 ID)的 li 标签并将其存储在变量中书架。
bookshelf = page_soup.findAll(“li” , {“class” : “col-xs-6 col-sm-4 col-md-3 col-lg-3”})
- 它将存储有关该类的所有信息,即书籍。你可以在上图中看到,每个
- 标签
和类:“col-xs-6 col-sm-4 col-md-3 col-lg-3”代表一本书。 - 现在我们拥有了所有书籍,我们需要选择必须从每本书中提取哪些特定信息,即Title和Price 。
- 您可以在上图中看到,每本书的标题都在
标签
下,该标签在 标签下,带有 'title'。所以上面的函数用于提取每本书的标题。
book_title = books.h3.a["title"]- 对于价格,我们可以看到它在 class 中的
标签
下: “price_color” ,所以我们使用findAll()
book_price = books.findAll("p", {"class" : "price_color"})
price = book_price[0].text.strip()- 0 索引接收页面第一本书的价格并将其存储在变量price中。函数.text.strip()仅收集前后任何空格的文本和条带。