使用Python下载 Instagram Reel
在本文中,我们将讨论如何使用Python下载 Instagram reel。
Instagram 是 Facebook 旗下的社交网络平台。在Python中,有许多可用的库可以用来解决一些现实生活中的问题,它还提供了一些从 Instagram 抓取信息的工具。其中一个工具是 Instascrape Python包。 Instascrape 是强大的 Instagram 数据抓取工具包。
安装:
从 PyPI 安装insta-scrape库
pip install insta-scrape
要从 Instagram 下载卷轴,首先导入所有必需的库。在我们的示例中,我们正在导入时间模块,因为在保存文件时,我们会将时间与文件名连接起来以避免命名冲突。现在添加 Session-Id 和标头。 Session-Id 在您注销之前一直有效。所以当你下一次时,你需要再次传递一个新的会话 ID。 (您将通过检查页面获得会话存储中的会话 ID)。由于 Instagram 的更新政策,直接抓取数据并不容易,因此我们必须将会话 ID 传递到标头中。使用卷轴模块并提供下载位置,我们可以完成工作。
句法:
insta_reel=Reel(‘instagram link’)
insta_reel.scrape(headers=headers)
insta_reel.download(download_path.mp4″)
按照上述步骤,您将在指定目录中下载卷轴。
示例:使用Python下载 Instagram 卷轴
Python3
from instascrape import Reel
import time
# session id
SESSIONID = "Paste session Id Here"
# Header with session id
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.74 \
Safari/537.36 Edg/79.0.309.43",
"cookie": f'sessionid={SESSIONID};'
}
# Passing Instagram reel link as argument in Reel Module
insta_reel = Reel(
'https://www.instagram.com/reel/CKWDdesgv2l/?utm_source=ig_web_copy_link')
# Using scrape function and passing the headers
insta_reel.scrape(headers=headers)
# Giving path where we want to download reel to the
# download function
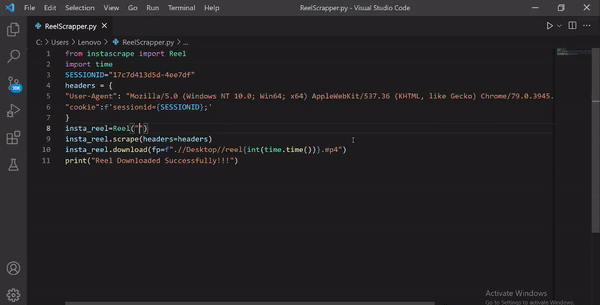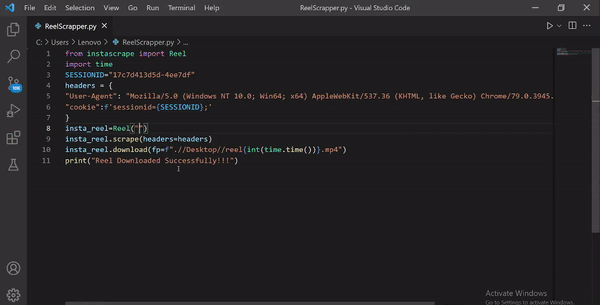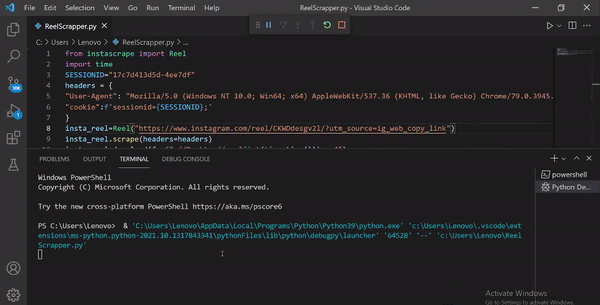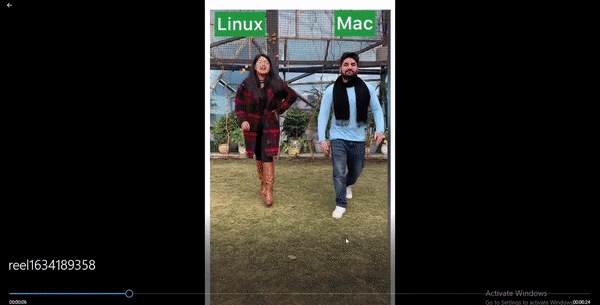
insta_reel.download(fp=f".\\Desktop\\reel{int(time.time())}.mp4")
# printing success Message
print('Downloaded Successfully.')输出: