Pyspark – 将多个数组列拆分成行
假设我们有一个 DataFrame,其中包含具有不同类型值的列,例如字符串、 integer 等,有时列数据也是数组格式。使用数组有时很困难,为了消除我们想要将这些数组数据拆分成行的困难。
将多个数组列数据拆分为行 pyspark 提供了一个名为 expand ()的函数。使用explode,我们将为数组中的每个元素获得一个新行。当一个数组被传递给这个函数,它会创建一个新的默认列,它包含所有数组元素作为它的行,并且数组中存在的空值将被忽略。这是pyspark.sql.functions 模块中可用的内置函数。
Syntax: pyspark.sql.functions.explode(col)
Parameters:
- col is an array column name which we want to split into rows.
Note: It takes only one positional argument i.e. at a time only one column can be split.
示例:使用explode() 拆分数组列
在此示例中,我们将创建一个包含三列的数据框,其中一列“姓名”包含学生姓名,另一列“年龄”包含学生年龄,最后一列和第三列“Courses_enrolled”包含已注册的课程通过这些学生。前两列包含字符串类型的简单数据,但第三列包含数组格式的数据。我们将包含数组格式数据的“Courses_enrolled”列拆分为行。
Python3
# importing pyspark
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# importing all from pyspark.sql.functions
# like Row, array, explode etc.
from pyspark.sql.functions import *
# creating a sparksession object and
# providing appName
spark=SparkSession.builder.appName("sparkdf").getOrCreate()
# now creating dataframe
# creating the row data and giving array
# values for dataframe
data = [('Jaya', '20', ['SQL','Data Science']),
('Milan', '21', ['ML','AI']),
('Rohit', '19', ['Programming', 'DSA']),
('Maria', '20', ['DBMS', 'Networking']),
('Jay', '22', ['Data Analytics','ML'])]
# column names for dataframe
columns = ['Name', 'Age', 'Courses_enrolled']
# creating dataframe with createDataFrame()
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()Python3
# using select function applying
# explode on array column
df2 = df.select(df.Name,explode(df.Courses_enrolled))
# printing the schema of the df2
df2.printSchema()
# show df2
df2.show()Python3
# creating the row data and giving array
# values for dataframe along with null values
data = [('Jaya', '20', ['SQL', 'Data Science']),
('Milan', '21', ['ML', 'AI']),
('Rohit', '19', None),
('Maria', '20', ['DBMS', 'Networking']),
('Jay', '22', None)]
# column names for dataframe
columns = ['Name', 'Age', 'Courses_enrolled']
# creating dataframe with createDataFrame()
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()Python3
# now using select function applying
# explode_outer on array column
df4 = df.select(df.Name, explode_outer(df.Courses_enrolled))
# printing the schema of the df4
df4.printSchema()
# show df2
df4.show()Python3
# using select function applying
# explode on array column
df2 = df.select(df.Name, posexplode(df.Courses_enrolled))
# printing the schema of the df2
df2.printSchema()
# show df2
df2.show()Python3
# using select function applying
# explode on array column
df2 = df.select(df.Name, posexplode_outer(df.Courses_enrolled))
# printing the schema of the df2
df2.printSchema()
# show df2
df2.show()输出:
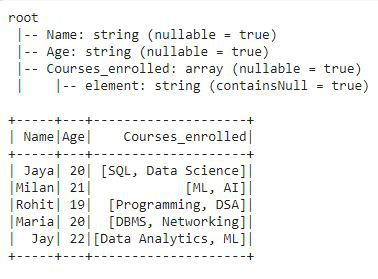
在数据框的模式中,我们可以看到前两列是字符串类型数据,第三列是数组数据。现在,我们将使用explode() 将数组列拆分为行。
蟒蛇3
# using select function applying
# explode on array column
df2 = df.select(df.Name,explode(df.Courses_enrolled))
# printing the schema of the df2
df2.printSchema()
# show df2
df2.show()
输出:

在这个输出中,我们可以看到数组列被拆分成行。 Explode()函数为数组列创建了一个默认列 'col',每个数组元素都转换为一行,并且列的类型也更改为字符串,之前它的类型是上面 df 输出中提到的数组。
爆炸的类型()
分解数组列的方法有以下三种:
- 爆炸外()
- 姿势爆炸()
- 姿势爆炸_外()
让我们通过一个例子来理解它们。为此,我们将创建一个包含一些空数组的数据框,并将使用不同类型的爆炸将数组列拆分为行。
蟒蛇3
# creating the row data and giving array
# values for dataframe along with null values
data = [('Jaya', '20', ['SQL', 'Data Science']),
('Milan', '21', ['ML', 'AI']),
('Rohit', '19', None),
('Maria', '20', ['DBMS', 'Networking']),
('Jay', '22', None)]
# column names for dataframe
columns = ['Name', 'Age', 'Courses_enrolled']
# creating dataframe with createDataFrame()
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()
输出:

1.explode_outer(): explode_outer函数为数组元素的每个元素将数组列拆分为一行,不管它是否包含空值。而简单的 expand() 忽略列中存在的空值。
蟒蛇3
# now using select function applying
# explode_outer on array column
df4 = df.select(df.Name, explode_outer(df.Courses_enrolled))
# printing the schema of the df4
df4.printSchema()
# show df2
df4.show()
输出:

正如我们上面定义的那样,explode_outer() 不会忽略数组列的空值。显然,我们可以看到空值也显示为数据帧的行。
2.posexplode(): posexplode() 将数组列拆分为数组中每个元素的行,并提供数组中元素的位置。它创建两列“pos”来携带数组元素的位置,“col”来携带特定的数组元素并忽略空值。现在,我们将对数组列“Courses_enrolled”应用poseexplode()。
蟒蛇3
# using select function applying
# explode on array column
df2 = df.select(df.Name, posexplode(df.Courses_enrolled))
# printing the schema of the df2
df2.printSchema()
# show df2
df2.show()
输出:

由于poseexplode() 将数组拆分为行并提供数组元素的位置,在此输出中,我们获得了“pos”列中数组元素的位置。它忽略了数组列中存在的空值。
3.posexplode_outer(): posexplode_outer() 将数组列拆分为数组中每个元素的行,并提供数组中元素的位置。它创建两列“pos”来携带数组元素的位置和“col”来携带特定的数组元素,无论它是否包含空值。这意味着posexplode_outer() 具有explode_outer() 和posexplode() 函数的功能。让我们在示例中看到这一点:
现在,我们将在数组列“Courses_enrolled”上应用poseexplode_outer()。
蟒蛇3
# using select function applying
# explode on array column
df2 = df.select(df.Name, posexplode_outer(df.Courses_enrolled))
# printing the schema of the df2
df2.printSchema()
# show df2
df2.show()
输出:

因为,posexplode_outer() 提供了爆炸函数explode_outer() 和posexplode() 的功能。在输出中,我们可以清楚地看到,我们已经获得了所有数组元素的行和位置值,包括 'pos' 和 'col' 列中的空值。