用于机器学习问题的 Pywedge 包
当人们开始学习机器学习和数据科学时,他们总会听到的一个事实/观察结果是,将机器学习模型拟合到数据集很容易,但为任务准备数据集却不然。在解决机器学习问题时,我们通常需要经过一系列步骤才能真正找到最适合我们数据集的机器学习算法。几个主要步骤可以命名为:
- 数据收集:可以从各种来源收集现实数据,也可以手动制作。
- 数据集预处理:收集原始数据后,我们需要将其转换为有意义的形式,以便算法可以很好地解释它。它还涉及一系列步骤,例如 - 使用探索性数据分析理解数据,删除数据集中的缺失值(通过插补方法/手动)。
- 特征工程:在特征工程中,我们实现了将分类特征转换为数值特征、标准化、归一化、使用卡方检验等不同方法进行特征选择、使用额外的树分类器等过程。
- 处理数据集中的不平衡:有时我们收集的数据集处于高度不平衡状态。将任何模型拟合到这种类型的数据集都会给我们带来不准确的结果,因为模型总是对数据集中频繁出现的数据有偏见。
- 制作基线模型:在这个过程中,我们将不同的 ML 算法应用于我们的数据,并尝试找出哪种模型能给我们提供更准确的结果。
- 超参数调整:在我们从所有模型中选择最佳模型后,我们调整模型的超参数,以通过解决欠拟合/过拟合问题来提高模型的准确性。
因此,我们可以得出结论,在得到我们想要的结果之前,我们必须经历许多不同的步骤。就时间而言,大约 80% 的时间用于数据准备,以便模型可以适应它,其余 20% 的时间用于拟合 ML 算法和进行预测。因此,执行所有这些任务肯定是一项详尽的任务,但是如果我们可以使用一些方法/函数/库,让我们的这项任务变得容易。
在本文中,我们将了解一个名为Pywedge的开源Python包。
什么是 Pywedge?
Pywedge 是一个开源的Python包,可以通过 pip 安装,由Venkatesh Rengarajan Muthu开发,它可以帮助我们自动化编写用于数据预处理、数据可视化、特征工程、处理不平衡数据和制定标准基线的代码的任务模型,以非常交互的方式调整超参数。
Pywedge 的特点:
- 它可以制作8种不同类型的交互式图表,例如:散点图、饼图、箱形图、条形图、直方图等。
- 使用交互方法进行数据预处理,例如处理缺失值、将分类特征转换为数值特征、标准化、归一化、处理类不平衡等。
- 它会自动将我们的数据拟合到不同的 ML 算法上,并为我们提供 10 个最佳基线模型。
- 我们还可以在我们想要的模型上应用超参数调整。
让我们使用这个 pywedge 库来解决一个回归问题,在这个问题中,我们必须使用以下数据集来预测发电厂产生的能量 Dockship 的电厂能源预测人工智能挑战赛。
导入重要的库
Python3
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorPython
# Loading testing Data
test_data = pd.read_csv("TEST.csv")
# Loading training Data
data = pd.read_csv("TRAIN.csv")
# Printing the shape of train dataset
data.shapePython
data.head()Python
data.info()Python
import pywedge as pw
ppd = pw.Pre_process_data(data, test_data, y='PE',c=None,type="Regression")
new_X, new_y, new_test = ppd.dataframe_clean()Python
# Assigning preprocessed data to make train and test data
X_train = new_X
y_train = new_y
X_test = new_test
# calling baseline_model method to prepare all the baseline models
blm = pw.baseline_model(X_train,y_train)
# printing the regression summary
blm.Regression_summary()加载训练和测试数据集:
Python
# Loading testing Data
test_data = pd.read_csv("TEST.csv")
# Loading training Data
data = pd.read_csv("TRAIN.csv")
# Printing the shape of train dataset
data.shape
(8000, 5)现在,我们将使用 head() 方法检查我们的数据集的外观,并在后续步骤中检查其一些信息,如下所示:
Python
data.head()

我们可以从上图中推断出我们的数据集有 5 列,其中前四列是我们的特征,最后一列 (PE) 是我们的目标列。
Python
data.info()

使用info()方法,我们可以解释我们的数据集没有缺失值,并且每个特征的数据类型都是 float64 类型。
使用 pywedge 库:
Python
import pywedge as pw
ppd = pw.Pre_process_data(data, test_data, y='PE',c=None,type="Regression")
new_X, new_y, new_test = ppd.dataframe_clean()

我们使用pywedge的Pre_process_data方法加载训练数据,并创建一个Pre_process_data对象,该对象具有返回预先处理的数据的dataframe_clean方法。该方法以交互方式询问将分类特征转换为数值特征的方法,并且还提供了选择不同标准化技术来标准化数据集的选项。
使用 pywedge 准备基线模型:
制作修改后的训练和测试数据并准备基线模型-
Python
# Assigning preprocessed data to make train and test data
X_train = new_X
y_train = new_y
X_test = new_test
# calling baseline_model method to prepare all the baseline models
blm = pw.baseline_model(X_train,y_train)
# printing the regression summary
blm.Regression_summary()
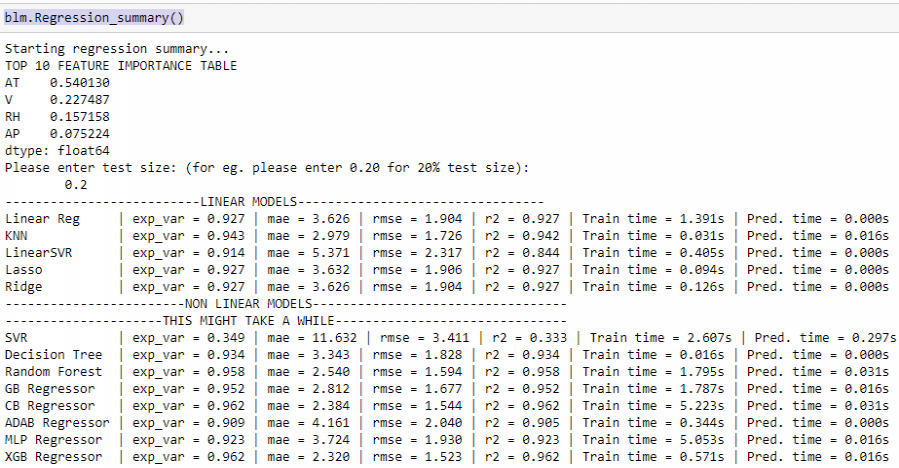
标准基线模型
baseline_model方法创建一个对象“blm” , Regression_summary()方法返回有关已实现模型的摘要。它为我们提供了使用AdaBoost回归器和最佳基线模型计算的前 10 个最重要的特征。此外,我们可以检查哪种算法需要多少时间来训练和做出预测。还显示了我们评估模型所使用的不同指标。但是,它不执行任何超参数调整,因此以后可以对最佳模型进行微调以获得更准确的结果。
因此,我们可以注意到,只需编写几行代码,就可以多快地找出应该使用哪种机器学习模型来解决我们的问题。