链接预测——使用 Networkx 预测网络中的边缘
链路预测用于预测网络中未来可能的链路。 Link Prediction 是 Facebook 推荐您可能认识的人、Amazon 预测您可能会感兴趣的商品以及 Zomato 推荐您可能会订购的食物的算法。
对于本文,我们将考虑如下构造的 Graph:
import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
G.add_edges_from([(1, 2), (1, 3), (1, 4), (3, 4), (4, 5)])
plt.figure(figsize =(10, 10))
nx.draw_networkx(G, with_labels = True)
输出: 
为了成功预测网络中的边缘,可以假设以下方法:
- 三元闭合
- 杰卡德系数
- 资源分配指数
- Adamic Adar 指数
- 优先附加
- 社区共同邻居
- 社区资源分配
三元闭包:
如果两个顶点连接到相同的第三个顶点,则它们共享连接的趋势是三元闭包。
comm_neighb(X, Y) = |N(X)  N(Y)|, where N(X) is the set of all neighbours of X.
N(Y)|, where N(X) is the set of all neighbours of X.
import networkx as nx
G = nx.Graph()
G.add_edges_from([(1, 2), (1, 3), (1, 4), (3, 4), (4, 5)])
e = list(G.edges())
def triadic(e):
new_edges = []
for i in e:
a, b = i
for j in e:
x, y = j
if i != j:
if a == x and (b, y) not in e and (y, b) not in e:
new_edges.append((b, y))
if a == y and (b, x) not in e and (x, b) not in e:
new_edges.append((b, x))
if b == x and (a, y) not in e and (y, a) not in e:
new_edges.append((a, y))
if b == y and (a, x) not in e and (x, a) not in e:
new_edges.append((a, x))
return new_edges
print("The possible new edges according to Triadic closure are :")
print(triadic(e))
输出:
The possible new edges according to Triadic closure are :
[(2, 3), (2, 4), (3, 2), (4, 2), (1, 5), (3, 5), (5, 1), (5, 3)]
杰卡德系数:
它是通过按邻居总数归一化的公共邻居数来计算的。它用于衡量两个有限样本集之间的相似性,定义为交集的大小除以样本集的并集的大小。
杰卡德系数(X, Y) = 
import networkx as nx
G = nx.Graph()
G.add_edges_from([(1, 2), (1, 3), (1, 4), (3, 4), (4, 5)])
print(list(nx.jaccard_coefficient(G))
输出:
[(1, 5, 0.3333333333333333), (2, 3, 0.5), (2, 4, 0.3333333333333333), (2, 5, 0.0), (3, 5, 0.5)]
Networkx 的jaccard_coefficient内置函数必然返回一个包含 3 个元组 (u, v, p) 的列表,其中 u, v 是下一个将添加的新边,概率度量为 p (p 是节点的 Jaccard 系数u 和 v)。
资源分配指数:
在许多基于相似性的复杂网络中预测缺失链接的方法中,Research Allocation Index 表现良好,时间复杂度较低。它被定义为一个节点可以通过它们的公共邻居发送给另一个资源的一部分。
研究分配指数(X, Y) = 
import networkx as nx
G = nx.Graph()
G.add_edges_from([(1, 2), (1, 3), (1, 4), (3, 4), (4, 5)])
print(list(nx.resource_allocation_index(G)))
输出:
[(1, 5, 0.3333333333333333), (2, 3, 0.3333333333333333), (2, 4, 0.3333333333333333), (2, 5, 0), (3, 5, 0.3333333333333333)]
networkx 包提供了resource_allocation_index的内置函数,它提供了 3 个元组 (u, v, p) 的列表,其中 u, v 是新边,p 是新边 u, v 的资源分配索引。
Adamic Adar 指数:
这项措施于 2003 年引入,用于根据两个节点之间共享链接的数量预测网络中缺失的链接。计算如下:
Adamic Adar 指数(X, Y) = 
import networkx as nx
G = nx.Graph()
G.add_edges_from([(1, 2), (1, 3), (1, 4), (3, 4), (4, 5)])
print(list(nx.adamic_adar_index(G)))
输出:
[(1, 5, 0.9102392266268373), (2, 3, 0.9102392266268373), (2, 4, 0.9102392266268373), (2, 5, 0), (3, 5, 0.9102392266268373)]
networkx 包提供了adamic_adar_index的内置函数,它提供了 3 个元组 (u, v, p) 的列表,其中 u, v 是新边,p 是新边 u, v 的 adar 索引。
优先附件:
优先依附是指一个节点连接的越多,就越有可能接收到新的链接(参考这篇文章参考了基于优先依附概念形成的Barabasi Albert图) 度数越高的节点获得的邻居越多。
Preferential Attachment(X, Y) = |N(X)|.|N(Y)|import networkx as nx
G = nx.Graph()
G.add_edges_from([(1, 2), (1, 3), (1, 4), (3, 4), (4, 5)])
print(list(nx.preferential_attachment(G)))
输出:
[(1, 5, 3), (2, 3, 2), (2, 4, 3), (2, 5, 1), (3, 5, 2)]
networkx 包提供了一个内建的preferential_attachment附加函数,它提供了一个包含 3 个元组 (u, v, p) 的列表,其中 u, v 是新边,p 是新边 u, v 的优先附加分数。
社区共同邻居:
同一社区中邻居获得奖励的共同邻居数量。为此,我们必须指定所有节点的社区。
Community Common Neighbors(X, Y) = |N(X)  N(Y)| +
N(Y)| +  ,
,
where f(u) = 1, if u is in a community; otherwise 0.
import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
G.add_node('A', community = 0)
G.add_node('B', community = 0)
G.add_node('C', community = 0)
G.add_node('D', community = 0)
G.add_node('E', community = 1)
G.add_node('F', community = 1)
G.add_node('G', community = 1)
G.add_node('H', community = 1)
G.add_node('I', community = 1)
G.add_edges_from([('A', 'B'), ('A', 'D'), ('A', 'E'), ('B', 'C'),
('C', 'D'), ('C', 'F'), ('E', 'F'), ('E', 'G'),
('F', 'G'), ('G', 'H'), ('G', 'I')])
nx.draw_networkx(G)
print(list(nx.cn_soundarajan_hopcroft(G)))
输出: 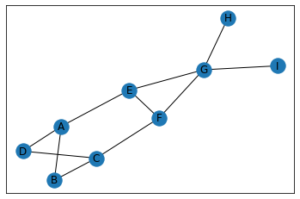
[('I', 'A', 0),
('I', 'C', 0),
('I', 'D', 0),
('I', 'E', 2),
('I', 'H', 2),
('I', 'F', 2),
('I', 'B', 0),
('A', 'H', 0),
('A', 'C', 4),
('A', 'G', 1),
('A', 'F', 1),
('C', 'H', 0),
('C', 'G', 1),
('C', 'E', 1),
('D', 'G', 0),
('D', 'E', 1),
('D', 'H', 0),
('D', 'F', 1),
('D', 'B', 4),
('G', 'B', 0),
('E', 'H', 2),
('E', 'B', 1),
('H', 'F', 2),
('H', 'B', 0),
('F', 'B', 1)]
networkx 包提供了cn_soundarajan_hopcroft的内置函数,它提供了 3 个元组 (u, v, p) 的列表,其中 u, v 是新边,p 是新边 u, v 的分数。
社区资源分配:
使用社区信息计算所有节点对的资源分配指数。
社区资源分配(X, Y) = 
import networkx as nx
G = nx.Graph()
G.add_node('A', community = 0)
G.add_node('B', community = 0)
G.add_node('C', community = 0)
G.add_node('D', community = 0)
G.add_node('E', community = 1)
G.add_node('F', community = 1)
G.add_node('G', community = 1)
G.add_node('H', community = 1)
G.add_node('I', community = 1)
G.add_edges_from([('A', 'B'), ('A', 'D'), ('A', 'E'), ('B', 'C'),
('C', 'D'), ('C', 'F'), ('E', 'F'), ('E', 'G'),
('F', 'G'), ('G', 'H'), ('G', 'I')])
print(list(nx.ra_index_soundarajan_hopcroft(G)))
输出:
[('I', 'A', 0),
('I', 'C', 0),
('I', 'D', 0),
('I', 'E', 0.25),
('I', 'H', 0.25),
('I', 'F', 0.25),
('I', 'B', 0),
('A', 'H', 0),
('A', 'C', 1.0),
('A', 'G', 0),
('A', 'F', 0),
('C', 'H', 0),
('C', 'G', 0),
('C', 'E', 0),
('D', 'G', 0),
('D', 'E', 0),
('D', 'H', 0),
('D', 'F', 0),
('D', 'B', 0.6666666666666666),
('G', 'B', 0),
('E', 'H', 0.25),
('E', 'B', 0),
('H', 'F', 0.25),
('H', 'B', 0),
('F', 'B', 0)]
networkx 包提供了ra_index_soundarajan_hopcroft的内置函数,它提供了 3 个元组 (u, v, p) 的列表,其中 u, v 是新边,p 是新边 u, v 的分数。
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。