理解 OpenSeq2Seq
先决条件: LTSM、GRU
在本文中,我们将讨论一个深度学习工具包,用于改善当前语音识别模型的训练时间,包括自然语言翻译、语音合成和语言建模等。使用此工具包构建的模型以 1.5-3 倍的训练时间提供最先进的性能。
OpenSeq2Seq
OpenSeq2Seq 是一个基于 TensorFlow 的开源工具包,具有多 GPU 和混合精度训练,可显着减少各种 NLP 模型的训练时间。例如,
1. Natural Language Translation: GNMT, Transformer, ConvS2S
2. Speech Recognition: Wave2Letter, DeepSpeech2
3. Speech Synthesis: Tacotron 2
它使用 Sequence to Sequence 范式来构建和训练模型以执行各种任务,例如机器翻译、文本摘要。
序列到序列模型
该模型由 3 部分组成:编码器、编码器向量和解码器。
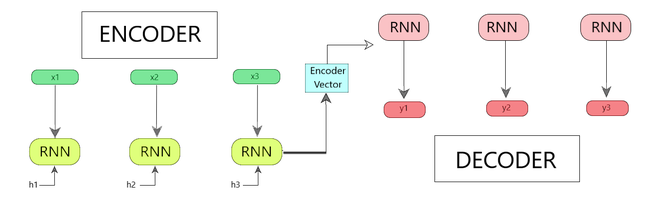
图 1:编码器-解码器序列到序列模型
- 编码器
- 在这方面,使用了几个循环单元,如 LTSM (长期短期记忆)和 GRU (门控循环单元)来增强性能。
- 这些循环单元中的每一个都接受输入序列的单个元素,收集该元素的信息并将其向前传播。
- 输入序列是问题中所有单词的集合。
- 隐藏状态 (h 1 , h 2 …, h n ) 使用以下公式计算。 [方程 1]
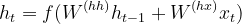
方程 1
where,
ht = hidden state
ht-1 = previous hidden state
W(hh) = weights attached to the previous hidden state. (ht-1)
xt = input vector
W(hx) = weights attached to the input vector.
- 编码器矢量
- 最终的隐藏状态是使用模型编码器部分的方程 1 计算的。
- 编码器向量收集所有输入元素的信息,以帮助解码器做出准确的预测。
- 它作为模型解码器部分的初始隐藏状态。
- 解码器
- 在这种情况下,存在几个循环单元,其中每个单元在时间步长 t 预测输出 y t 。
- 每个循环单元从前一个单元接受一个隐藏状态,并产生一个输出以及它自己的隐藏状态。
- 隐藏状态 (h 1 , h 2 …, h n ) 使用以下公式计算。 [方程 2]
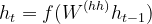
方程 2
例如,图 1. 显示了对话系统的序列到序列模型。

图 2:对话系统的序列到序列模型
每个序列到序列模型都有一个编码器和一个解码器。例如,S-no. Task Encoder Decoder 1. Sentiment Analysis RNN Linear SoftMax 2. Image Classification CNN Linear SoftMax
设计与建筑
OpenSeq2Seq 工具包提供了各种类,从用户可以继承自己的模块。该模型分为 5 个不同的部分:
- 数据层
- 编码器
- 解码器
- 损失函数
- 超参数
- 优化器
- 学习率
- 退出
- 正则化
- Batch_Size 等
For example, an OpenSeq2Seq model for Machine Translation would look like :
Encoder - GNMTLikeEncoderWithEmbedding
Decoder - RNNDecoderWithAttention
Loss Function - BasicSequenceLoss
Hyperparameters -
Learning Rate = 0.0008
Optimizer = 'Adam'
Regularization = 'weight decay'
Batch_Size = 32
混合精度训练:
在使用 float16 训练大型神经网络模型时,有时需要应用某些算法技术并将一些输出保留在 float32 中。 (因此得名,混合精度)。
混合精度支持 [使用算法]
该模型使用 TensorFlow 作为其基础,因此具有张量核心,可提供训练大型神经网络所需的性能。它们允许以两种方式进行矩阵-矩阵乘法:
- 单精度浮点(FP-32)
- 单精度浮点格式是一种计算机数字格式,在计算机内存中占据 32 位(现代计算机中为 4 个字节)。
- 在 32 位浮点数中,8 位保留给指数(“幅度”),23 位保留给尾数(“精度”)。
- 半精度浮点 (FP-16)
- 半精度是一种二进制浮点格式,是一种在计算机内存中占据 16 位(现代计算机中为两个字节)的计算机数字格式。
早些时候,在训练神经网络时,由于各种原因,使用FP-32 (如图 2 所示)来表示网络中的权重,例如:
- 更高的精度 — 32 位浮点数具有足够的精度,因此我们可以将不同大小的数字彼此区分开来。
- 广泛的范围——32 位浮点有足够的范围来表示比大多数应用程序所需的更小 (10^-45) 和更大 (10^38) 的数量。
- 可支持——所有硬件(GPU、CPU)和 API 都非常有效地支持 32 位浮点指令。

图 3:FP-32 表示
但是,后来发现,对于最大深度学习模型,不需要如此大的量级和精度。因此,NVIDIA 创建了支持 16 位浮点指令的硬件,并观察到大多数权重和梯度往往落在 16 位可表示范围内。
因此,在 OpenSeq2Seq 模型中,一直使用FP-16 。使用它,我们可以有效地防止浪费所有这些额外的位。使用 FP-16,我们将位数减半,指数从 8 位减少到 5,尾数从 23 位减少到 10。(如图 3 所示)
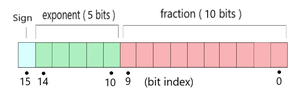
图 4:FP-16 表示
Risks of using FP-16 :
1. Underflow : attempting to represent numbers so small they clamp to zero.
2. Overflow : numbers so large (outside FP-16 range) that they become NaN, not a number.
- With underflow, our network never learns anything.
- With overflow, it learns garbage.
- For Mixed-Precision Training, we follow an algorithm that involves the following 2 steps:
Step 1 - Maintain float32 master copy of weights for weights update while using the float16
weights for forward and back propagation.
Step 2 - Apply loss scaling while computing gradients to prevent underflow during backpropagation.
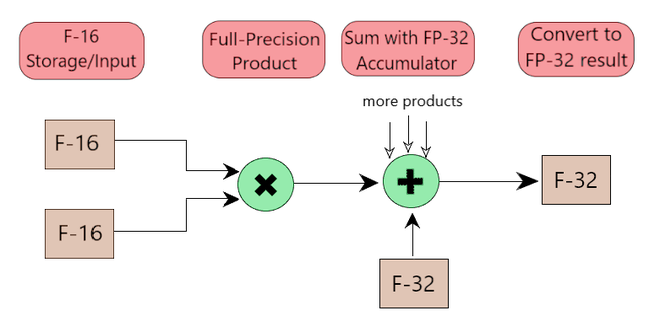
图 5:FP16 中的算术运算和 FP32 中的累加
OpenSeq2Seq 模型的混合精度训练涉及三件事:
- 混合精度优化器
- 混合精度正则化器
- 自动损失缩放
1.混合精度优化器
该模型默认所有变量和梯度都为FP-16,如图6所示。在这个过程中发生了以下步骤:
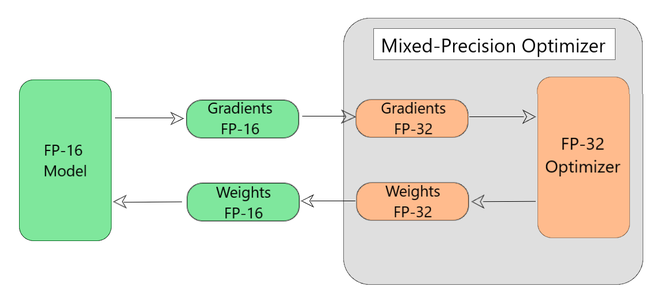
图 6:围绕 TensorFlow 优化器的混合精度包装器
Working of Mixed Precision Wrapper (Step by Step)
Each Iteration
{
Step 1 - The wrapper automatically converts FP-16 gradients and FP-32 and feed them
to the tensorflow optimizer.
Step 2 - The tensorflow optimizer then updates the copy of weights in FP-32.
Step 3 - The updated FP-32 weights are then converted back to FP-16.
Step 4 - The FP-16 weights are then used by the model for the next iteration.
}
2. 混合精度正则化
如前所述,使用 F-16 所涉及的风险,如数值上溢/下溢。混合精度正则化确保在训练过程中不会发生这种情况。因此,为了克服此类问题,我们执行以下步骤:
Step 1 - All regularizers should be defined during variable creation.
Step 2 - The regularizer function should be wrapped with the 'Mixed Precision Wrapper'. This takes care of 2 things:
2.1 - Adds the regularized variables to a tensorflow collection.
2.2 - Disables the underlying regularization function for FP-16 copy.
Step 3 - This collection is then retrieved by Mixed Precision Optimizer Wrapper.
Step 4 - The corresponding functions obtained from the MPO wrapper will be applied to the FP-32 copy
of the weights ensuring that their gradients always stay in full precision.
3. 自动损失缩放
OpenSeq2Seq 模型涉及自动损失缩放。因此,用户不必手动选择损失值。优化器在每次迭代后分析梯度并更新下一次迭代的损失值。
涉及的模型
OpenSeq2Seq 目前提供了多种模型的完整实现:
- 机器翻译
- 语音识别
- 语音合成
- 情绪分析
- 图像分类
OpenSeq2Seq 具有用于语言建模、机器翻译、语音合成、语音识别、情感分析等的各种模型。它旨在提供丰富的常用编码器和解码器库。这是 OpenSeq2Seq 模型的基本概述,涵盖了所涉及的直觉、架构和概念。如有任何疑问/疑问,请在下方评论。