ML——注意力机制
介绍:
假设我们已经了解普通 Seq2Seq 或编码器-解码器模型的工作原理,让我们关注如何进一步提升它并提高我们预测的准确性。我们将考虑机器翻译这个很好的老例子。
动机:
在 Seq2Seq 模型中,编码器读取输入句子一次并对其进行编码。在每个时间步,解码器使用这个嵌入并产生一个输出。但是人类不会翻译这样的句子。我们不会记住输入并尝试重新创建它,如果我们这样做,我们可能会忘记某些单词。此外,在生成每个单词时,整个句子在每个时间步骤中是否重要?不,只有某些词很重要。理想情况下,我们只需要向解码器输入相关信息(相关词的编码)。
“学会只注意句子的某些重要部分。”
目标:
我们的目标是提出一个概率分布,它说明在每个时间步应该对输入词给予多少重要性或注意力。
它是如何工作的:
考虑以下带有注意力的编码器-解码器架构。
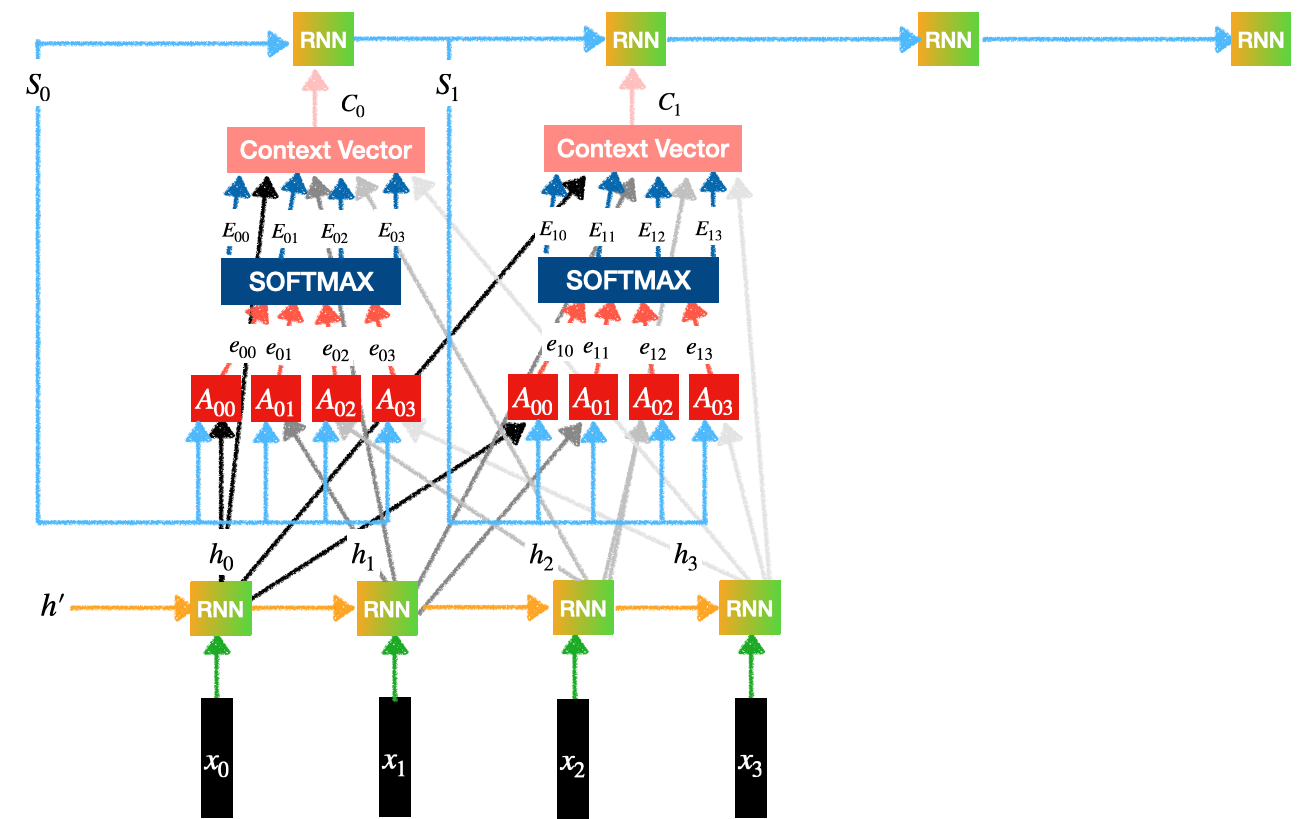
带注意力的编码器-解码器
我们可以观察上图中的 3 个子部件/组件:
- 编码器
- 注意力
- 解码器
编码器:

编码器
包含一个 RNN 层(可以是 LSTM 或 GRU):
- 有4个输入:

- 每个输入都经过一个嵌入层。
- 每个输入都会生成一个隐藏表示。
- 这将生成编码器的输出:

注意力:
- 我们的目标是生成上下文向量。
- 例如,上下文向量
 告诉我们应该给予输入多大的重要性/注意力:
告诉我们应该给予输入多大的重要性/注意力:  .
. - 该层又包含 3 个子部分:
- 前馈网络
- Softmax 计算
- 上下文向量生成
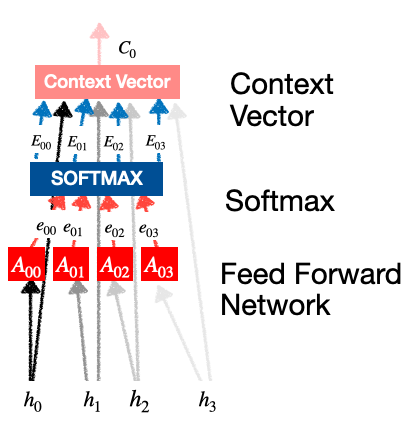
注意力
前馈网络:
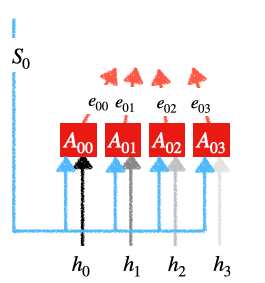
前馈网络
每个
 是一个带有一个隐藏层的简单前馈神经网络。这个前馈网络的输入是:
是一个带有一个隐藏层的简单前馈神经网络。这个前馈网络的输入是:- 以前的解码器状态
- 编码器状态的输出。
每个单元生成输出:  .
.  .
.  可以是任何激活函数,例如 sigmoid、tanh 或 ReLu。
可以是任何激活函数,例如 sigmoid、tanh 或 ReLu。
Softmax 计算:
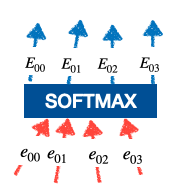
softmax 计算

这些
 称为注意力权重。这决定了输入的重要性
称为注意力权重。这决定了输入的重要性 .
.接触向量生成:
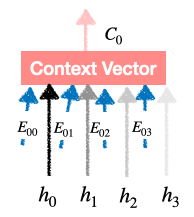
上下文向量生成
 .
.我们发现
 以相同的方式将其馈送到 Decoder 层的不同 RNN 单元。
以相同的方式将其馈送到 Decoder 层的不同 RNN 单元。所以这是最终的向量,它是(概率分布)和(编码器的输出)的乘积,它只是对输入词的关注。
解码器:
我们将这些上下文向量提供给解码器层的 RNN。每个解码器产生一个输出,它是输入词的翻译。
观察:
如果我们知道真正的注意力权重,  那么计算误差然后调整参数以最小化这种损失会更容易。但在实践中,我们不会有这个。我们需要有人手动将每个词注释为一组贡献词。这是不可能的。
那么计算误差然后调整参数以最小化这种损失会更容易。但在实践中,我们不会有这个。我们需要有人手动将每个词注释为一组贡献词。这是不可能的。
那为什么这个模型应该起作用呢?
与其他模型相比,这是一个更好的模型,因为我们要求模型做出明智的选择。给定足够的数据,模型应该能够像人类一样学习这些注意力权重。事实上,这些比普通的编码器-解码器模型工作得更好。