使用Python和Selenium下载 Google 图像
在本文中,我们将看到如何使用Python和Selenium下载 google Image。
安装
在 PC 的终端上,键入以下命令。
pip install selenium我们还需要安装一个网络驱动程序,以帮助我们自动运行网络浏览器。您可以安装 Firefox 网络驱动程序、Internet Explorer 网络驱动程序或 Chrome 网络驱动程序。在本文中,我们将使用 Chrome Web Driver。
自动化脚本通过查找我们指定的元素与网页交互。有多种方法可以在网页中查找元素。最简单的方法是选择所需元素的 HTML 标记并复制其 XPath。为此,只需右键单击网页,单击“检查”,然后复制所需元素的 XPath。如果需要,您还可以使用元素的名称或 CSS。
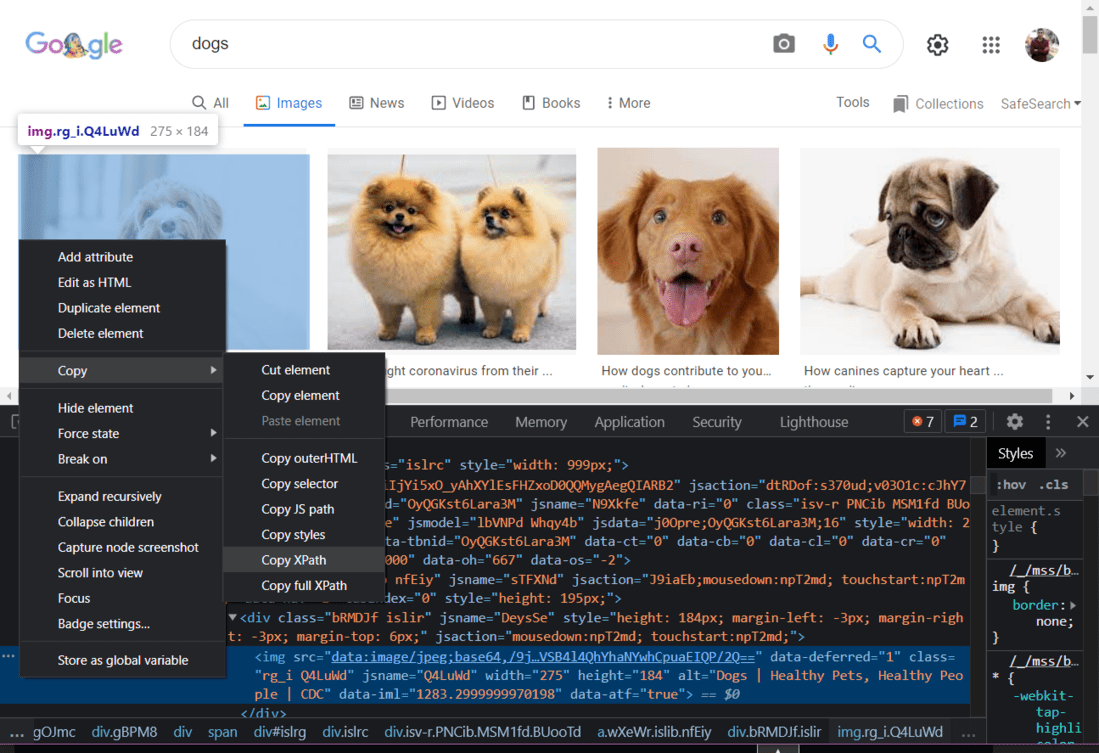
Google 图片结果的 HTML
下面是实现:
Python3
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# What you enter here will be searched for in
# Google Images
query = "dogs"
# Creating a webdriver instance
driver = webdriver.Chrome('Enter-Location-Of-Your-Webdriver')
# Maximize the screen
driver.maximize_window()
# Open Google Images in the browser
driver.get('https://images.google.com/')
# Finding the search box
box = driver.find_element_by_xpath('//*[@id="sbtc"]/div/div[2]/input')
# Type the search query in the search box
box.send_keys(query)
# Pressing enter
box.send_keys(Keys.ENTER)
# Fumction for scrolling to the bottom of Google
# Images results
def scroll_to_bottom():
last_height = driver.execute_script('\
return document.body.scrollHeight')
while True:
driver.execute_script('\
window.scrollTo(0,document.body.scrollHeight)')
# waiting for the results to load
# Increase the sleep time if your internet is slow
time.sleep(3)
new_height = driver.execute_script('\
return document.body.scrollHeight')
# click on "Show more results" (if exists)
try:
driver.find_element_by_css_selector(".YstHxe input").click()
# waiting for the results to load
# Increase the sleep time if your internet is slow
time.sleep(3)
except:
pass
# checking if we have reached the bottom of the page
if new_height == last_height:
break
last_height = new_height
# Calling the function
# NOTE: If you only want to capture a few images,
# there is no need to use the scroll_to_bottom() function.
scroll_to_bottom()
# Loop to capture and save each image
for i in range(1, 50):
# range(1, 50) will capture images 1 to 49 of the search results
# You can change the range as per your need.
try:
# XPath of each image
img = driver.find_element_by_xpath(
'//*[@id="islrg"]/div[1]/div[' +
str(i) + ']/a[1]/div[1]/img')
# Enter the location of folder in which
# the images will be saved
img.screenshot('Download-Location' +
query + ' (' + str(i) + ').png')
# Each new screenshot will automatically
# have its name updated
# Just to avoid unwanted errors
time.sleep(0.2)
except:
# if we can't find the XPath of an image,
# we skip to the next image
continue
# Finally, we close the driver
driver.close()结果:
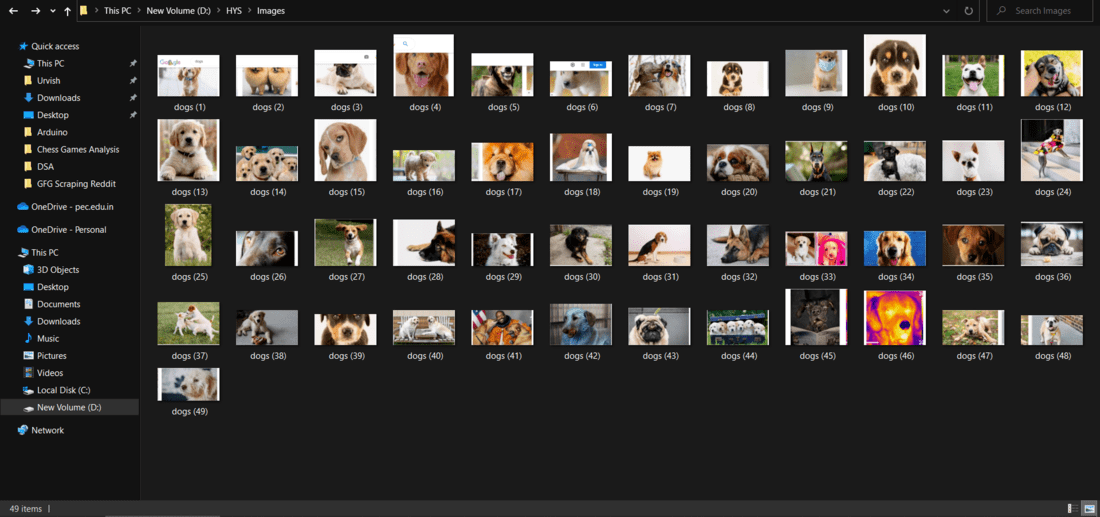
捕获的图像
嗯,这是创建自动化脚本的最简单方法。这个小程序可以成为你有趣的小项目。这可能是您使用Selenium旅程的起点。您可以使用Selenium执行不同的操作,例如从 Google 新闻中抓取新闻。因此,请保持对新想法的开放态度,您最终可能会使用Selenium和Python创建一个伟大的项目。