NLP Gensim 教程 - 初学者完整指南
本教程将为您提供Gensim 库的演练。
Gensim :它是由Radim Rehurek编写的Python开源库,用于无监督主题建模和自然语言处理。它旨在从文档中提取语义主题。它可以处理大型文本集合。因此,它与其他针对内存处理的机器学习软件包不同。 Gensim 还为各种算法提供高效的多核实现,以提高处理速度。它为文本处理提供了比 Scikit-learn、R 等其他软件包更方便的工具。
本教程将涵盖以下概念:
- 从给定的数据集创建语料库
- 在 Gensim 中创建一个 TFIDF 矩阵
- 使用 Gensim 创建二元组和三元组
- 使用 Gensim 创建 Word2Vec 模型
- 使用 Gensim 创建 Doc2Vec 模型
- 使用 LDA 创建主题模型
- 使用 LSI 创建主题模型
- 计算相似矩阵
- 总结文本文档
在继续之前,让我们了解下面提到的一些术语的含义。
- 语料库:文本文档的集合。
- 向量:表示文本的形式。
- 模型:用于生成数据表示的算法。
- 主题建模:它是一种信息挖掘工具,用于从文档中提取语义主题。
- 主题:一组经常一起出现的重复词。
For example:
You have a document which consists of words like -
bat, car, racquet, score, glass, drive, cup, keys, water, game, steering, liquid
These can be grouped into different topics as-| Topic 1 | Topic 2 | Topic 3 |
|---|---|---|
| glass | bat | car |
| cup | racquet | drive |
| water | score | keys |
| liquid | game | steering |
一些主题建模技术是——
- 潜在语义索引(LSI)
- 潜在狄利克雷分配(LDA)
现在我们有了术语的基本概念,让我们从使用 Gensim 包开始。
首先使用命令安装库 -
#for linux
#for anaconda prompt步骤 1:从给定的数据集创建语料库
您需要按照以下步骤来创建您的语料库:
- 加载您的数据集
- 预处理数据集
- 创建字典
- 创建词袋语料库
1.1 加载您的数据集:
您可以使用 .txt 文件作为数据集,也可以使用Gensim Downloader API加载数据集。
代码:
python3
import os
# open the text file as an object
doc = open('sample_data.txt', encoding ='utf-8')python3
import gensim.downloader as api
# check available models and datasets
info_datasets = api.info()
print(info_datasets)
#>{'corpora':
#> {'semeval-2016-2017-task3-subtaskBC':
#> {'num_records': -1, 'record_format': 'dict', 'file_size': 6344358, ....}
# information of a particular dataset
dataset_info = api.info("text8")
# load the "text8" dataset
dataset = api.load("text8")
# load a pre-trained model
word2vec_model = api.load('word2vec-google-news-300')python3
import gensim
import os
from gensim.utils import simple_preprocess
# open the text file as an object
doc = open('sample_data.txt', encoding ='utf-8')
# preprocess the file to get a list of tokens
tokenized =[]
for sentence in doc.read().split('.'):
# the simple_preprocess function returns a list of each sentence
tokenized.append(simple_preprocess(sentence, deacc = True))
print(tokenized)python3
from gensim import corpora
# storing the extracted tokens into the dictionary
my_dictionary = corpora.Dictionary(tokenized)
print(my_dictionary)python3
# save your dictionary to disk
my_dictionary.save('my_dictionary.dict')
# load back
load_dict = corpora.Dictionary.load(my_dictionary.dict')
# save your dictionary as text file
from gensim.test.utils import get_tmpfile
tmp_fname = get_tmpfile("dictionary")
my_dictionary.save_as_text(tmp_fname)
# load your dictionary text file
load_dict = corpora.Dictionary.load_from_text(tmp_fname)python3
# converting to a bag of word corpus
BoW_corpus =[my_dictionary.doc2bow(doc, allow_update = True) for doc in tokenized]
print(BoW_corpus)python3
from gensim.corpora import MmCorpus
from gensim.test.utils import get_tmpfile
output_fname = get_tmpfile("BoW_corpus.mm")
# save corpus to disk
MmCorpus.serialize(output_fname, BoW_corpus)
# load corpus
load_corpus = MmCorpus(output_fname)python3
from gensim import models
import numpy as np
# Word weight in Bag of Words corpus
word_weight =[]
for doc in BoW_corpus:
for id, freq in doc:
word_weight.append([my_dictionary[id], freq])
print(word_weight)python3
# create TF-IDF model
tfIdf = models.TfidfModel(BoW_corpus, smartirs ='ntc')
# TF-IDF Word Weight
weight_tfidf =[]
for doc in tfIdf[BoW_corpus]:
for id, freq in doc:
weight_tfidf.append([my_dictionary[id], np.around(freq, decimals = 3)])
print(weight_tfidf)python3
import gensim.downloader as api
from gensim.models.phrases import Phrases
# load the text8 dataset
dataset = api.load("text8")
# extract a list of words from the dataset
data =[]
for word in dataset:
data.append(word)
# Bigram using Phraser Model
bigram_model = Phrases(data, min_count = 3, threshold = 10)
print(bigram_model[data[0]])python3
# Trigram using Phraser Model
trigram_model = Phrases(bigram_model[data], threshold = 10)
# trigram
print(trigram_model[bigram_model[data[0]]])python3
import gensim.downloader as api
from multiprocessing import cpu_count
from gensim.models.word2vec import Word2Vec
# load the text8 dataset
dataset = api.load("text8")
# extract a list of words from the dataset
data =[]
for word in dataset:
data.append(word)
# We will split the data into two parts
data_1 = data[:1200] # this is used to train the model
data_2 = data[1200:] # this part will be used to update the model
# Training the Word2Vec model
w2v_model = Word2Vec(data_1, min_count = 0, workers = cpu_count())
# word vector for the word "time"
print(w2v_model['time'])python3
# similar words to the word "time"
print(w2v_model.most_similar('time'))
# save your model
w2v_model.save('Word2VecModel')
# load your model
model = Word2Vec.load('Word2VecModel')python3
# build model vocabulary from a sequence of sentences
w2v_model.build_vocab(data_2, update = True)
# train word vectors
w2v_model.train(data_2, total_examples = w2v_model.corpus_count, epochs = w2v_model.iter)
print(w2v_model['time'])python3
import gensim
import gensim.downloader as api
from gensim.models import doc2vec
# get dataset
dataset = api.load("text8")
data =[]
for w in dataset:
data.append(w)
# To train the model we need a list of tagged documents
def tagged_document(list_of_ListOfWords):
for x, ListOfWords in enumerate(list_of_ListOfWords):
yield doc2vec.TaggedDocument(ListOfWords, [x])
# training data
data_train = list(tagged_document(data))
# print trained dataset
print(data_train[:1])python3
# Initialize the model
d2v_model = doc2vec.Doc2Vec(vector_size = 40, min_count = 2, epochs = 30)
# build the vocabulary
d2v_model.build_vocab(data_train)
# Train Doc2Vec model
d2v_model.train(data_train, total_examples = d2v_model.corpus_count, epochs = d2v_model.epochs)
# Analyzing the output
Analyze = d2v_model.infer_vector(['violent', 'means', 'to', 'destroy'])
print(Analyze)python3
import gensim
from gensim import corpora
from gensim.models import LdaModel, LdaMulticore
import gensim.downloader as api
from gensim.utils import simple_preprocess, lemmatize
# from pattern.en import lemma
import nltk
# nltk.download('stopwords')
from nltk.corpus import stopwords
import re
import logging
logging.basicConfig(format ='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level = logging.INFO)
# import stopwords
stop_words = stopwords.words('english')
# add stopwords
stop_words = stop_words + ['subject', 'com', 'are', 'edu', 'would', 'could']
# import the dataset
dataset = api.load("text8")
data = [w for w in dataset]
# Preparing the data
processed_data = []
for x, doc in enumerate(data[:100]):
doc_out = []
for word in doc:
if word not in stop_words: # to remove stopwords
Lemmatized_Word = lemmatize(word, allowed_tags = re.compile('(NN|JJ|RB)')) # lemmatize
if Lemmatized_Word:
doc_out.append(Lemmatized_Word[0].split(b'/')[0].decode('utf-8'))
else:
continue
processed_data.append(doc_out) # processed_data is a list of list of words
# Print sample
print(processed_data[0][:10])python3
# create dictionary and corpus
dict = corpora.Dictionary(processed_data)
Corpus = [dict.doc2bow(l) for l in processed_data]python3
# Training
LDA_model = LdaModel(corpus = LDA_corpus, num_topics = 5)
# save model
LDA_model.save('LDA_model.model')
# show topics
print(LDA_model.print_topics(-1))python3
# probability of a word belonging to a topic
LDA_model.get_term_topics('fire')
bow_list =['time', 'space', 'car']
# convert to bag of words format first
bow = LDA_model.id2word.doc2bow(bow_list)
# interpreting the data
doc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics = True)python3
# Training the model with LSI
LSI_model = LsiModel(corpus = Corpus, id2word = dct, num_topics = 7, decay = 0.5)
# Topics
print(LSI_model.print_topics(-1))python3
import gensim.downloader as api
from gensim.matutils import softcossim
from gensim import corpora
s1 = ' Afghanistan is an Asian country and capital is Kabul'.split()
s2 = 'India is an Asian country and capital is Delhi'.split()
s3 = 'Greece is an European country and capital is Athens'.split()
# load pre-trained model
word2vec_model = api.load('word2vec-google-news-300')
# Prepare the similarity matrix
similarity_matrix = word2vec_model.similarity_matrix(dictionary, tfidf = None, threshold = 0.0, exponent = 2.0, nonzero_limit = 100)
# Prepare a dictionary and a corpus.
docs = [s1, s2, s3]
dictionary = corpora.Dictionary(docs)
# Convert the sentences into bag-of-words vectors.
s1 = dictionary.doc2bow(s1)
s2 = dictionary.doc2bow(s2)
s3 = dictionary.doc2bow(s3)
# Compute soft cosine similarity
print(softcossim(s1, s2, similarity_matrix)) # similarity between s1 &s2
print(softcossim(s1, s3, similarity_matrix)) # similarity between s1 &s3
print(softcossim(s2, s3, similarity_matrix)) # similarity between s2 &s3python3
# Find Odd one out
print(word2vec_model.doesnt_match(['india', 'bhutan', 'china', 'mango']))
#> mango
# cosine distance between two words.
word2vec_model.distance('man', 'woman')
# cosine distances from given word or vector to other words.
word2vec_model.distances('king', ['queen', 'man', 'woman'])
# Compute cosine similarities
word2vec_model.cosine_similarities(word2vec_model['queen'],
vectors_all =(word2vec_model['king'],
word2vec_model['woman'],
word2vec_model['man'],
word2vec_model['king'] + word2vec_model['woman']))
# king + woman is very similar to queen.
# words closer to w1 than w2
word2vec_model.words_closer_than(w1 ='queen', w2 ='kingdom')
# top-N most similar words.
word2vec_model.most_similar(positive ='king', negative = None, topn = 5, restrict_vocab = None, indexer = None)
# top-N most similar words, using the multiplicative combination objective,
word2vec_model.most_similar_cosmul(positive ='queen', negative = None, topn = 5)python3
from gensim.summarization import summarize, keywords
import os
text = " ".join((l for l in open('sample_data.txt', encoding ='utf-8')))
# Summarize the paragraph
print(summarize(text, word_count = 25))python3
# Important keywords from the paragraph
print(keywords(text))- Gensim Downloader API:这是一个在 Gensim 库中可用的模块,它是一个用于下载、获取信息和加载数据集/模型的 API。
代码:
蟒蛇3
import gensim.downloader as api
# check available models and datasets
info_datasets = api.info()
print(info_datasets)
#>{'corpora':
#> {'semeval-2016-2017-task3-subtaskBC':
#> {'num_records': -1, 'record_format': 'dict', 'file_size': 6344358, ....}
# information of a particular dataset
dataset_info = api.info("text8")
# load the "text8" dataset
dataset = api.load("text8")
# load a pre-trained model
word2vec_model = api.load('word2vec-google-news-300')
在这里,我们将一个文本文件视为原始数据集,其中包含来自维基百科页面的数据。
1.2 预处理数据集
文本预处理:在自然语言预处理中,文本预处理是清洗和准备文本数据的做法。为此,我们将使用 simple_preprocess()函数。该函数在标记化和规范化之后返回一个标记列表。
代码:
蟒蛇3
import gensim
import os
from gensim.utils import simple_preprocess
# open the text file as an object
doc = open('sample_data.txt', encoding ='utf-8')
# preprocess the file to get a list of tokens
tokenized =[]
for sentence in doc.read().split('.'):
# the simple_preprocess function returns a list of each sentence
tokenized.append(simple_preprocess(sentence, deacc = True))
print(tokenized)
输出:
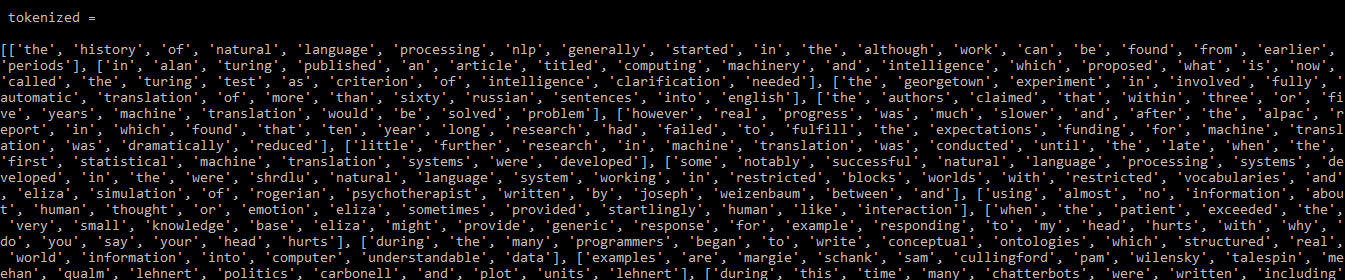
输出:标记化
1.3 创建字典
现在我们有了预处理的数据,可以使用 corpora.Dictionary()函数将其转换为字典。这本字典是唯一标记的映射。
代码:
蟒蛇3
from gensim import corpora
# storing the extracted tokens into the dictionary
my_dictionary = corpora.Dictionary(tokenized)
print(my_dictionary)
输出:

我的字典
1.3.1 将字典保存在磁盘上或作为文本文件
您可以在磁盘上保存/加载字典以及如下所述的文本文件:
代码:
蟒蛇3
# save your dictionary to disk
my_dictionary.save('my_dictionary.dict')
# load back
load_dict = corpora.Dictionary.load(my_dictionary.dict')
# save your dictionary as text file
from gensim.test.utils import get_tmpfile
tmp_fname = get_tmpfile("dictionary")
my_dictionary.save_as_text(tmp_fname)
# load your dictionary text file
load_dict = corpora.Dictionary.load_from_text(tmp_fname)
1.4 创建词袋语料库
一旦我们有了字典,我们就可以使用 doc2bow()函数创建一个词袋语料库。此函数计算每个不同单词的出现次数,将单词转换为其整数单词 id,然后将结果作为稀疏向量返回。
代码:
蟒蛇3
# converting to a bag of word corpus
BoW_corpus =[my_dictionary.doc2bow(doc, allow_update = True) for doc in tokenized]
print(BoW_corpus)
输出:
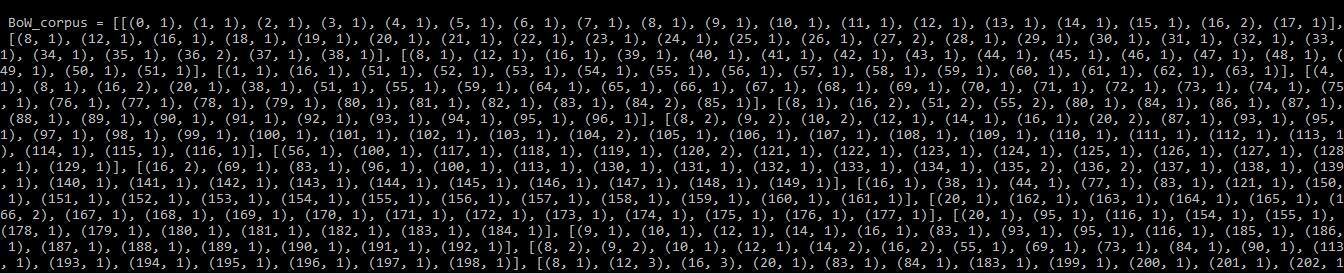
BoW_语料库
1.4.1 在磁盘上保存语料库:
代码:保存/加载您的语料库
蟒蛇3
from gensim.corpora import MmCorpus
from gensim.test.utils import get_tmpfile
output_fname = get_tmpfile("BoW_corpus.mm")
# save corpus to disk
MmCorpus.serialize(output_fname, BoW_corpus)
# load corpus
load_corpus = MmCorpus(output_fname)
第 2 步:在 Gensim 中创建一个 TFIDF 矩阵
TFIDF:代表词频- 逆文档频率。它是一种常用的自然语言处理模型,可帮助您确定语料库中每个文档中最重要的单词。这是为中等规模的语料库设计的。
有些词可能不是停用词,但可能在文档中更频繁地出现并且可能不太重要。因此,这些词的重要性需要删除或降低。 TFIDF 模型采用共享通用语言的文本,并确保整个语料库中最常用的词不会显示为关键字。您可以使用 Gensim 和您之前开发的语料库构建一个 TFIDF 模型:
代码:
蟒蛇3
from gensim import models
import numpy as np
# Word weight in Bag of Words corpus
word_weight =[]
for doc in BoW_corpus:
for id, freq in doc:
word_weight.append([my_dictionary[id], freq])
print(word_weight)
输出:

应用 TFIDF 模型前的字重
代码:应用TFIDF模型
蟒蛇3
# create TF-IDF model
tfIdf = models.TfidfModel(BoW_corpus, smartirs ='ntc')
# TF-IDF Word Weight
weight_tfidf =[]
for doc in tfIdf[BoW_corpus]:
for id, freq in doc:
weight_tfidf.append([my_dictionary[id], np.around(freq, decimals = 3)])
print(weight_tfidf)
输出:

应用TFIDF模型后的词权重
您可以看到,文档中频繁出现的单词现在分配了较低的权重。
第 3 步:使用 Genism 创建 Bigrams 和 Trigrams
许多词往往一起出现在内容中。单词一起出现时的含义与单独出现时的含义不同。
for example:
Beatboxing --> the word beat and boxing individually have meanings of their own
but these together have a different meaning. Bigrams:两个单词的组
三元组:三个词组
我们将在这里使用 text8 数据集,它可以使用Gensim 下载器 API 下载
代码:构建二元组和三元组
蟒蛇3
import gensim.downloader as api
from gensim.models.phrases import Phrases
# load the text8 dataset
dataset = api.load("text8")
# extract a list of words from the dataset
data =[]
for word in dataset:
data.append(word)
# Bigram using Phraser Model
bigram_model = Phrases(data, min_count = 3, threshold = 10)
print(bigram_model[data[0]])

二元模型
要创建Trigram,我们只需将上面获得的 bigram 模型传递给相同的函数。
代码:
蟒蛇3
# Trigram using Phraser Model
trigram_model = Phrases(bigram_model[data], threshold = 10)
# trigram
print(trigram_model[bigram_model[data[0]]])
输出:

卦
第 4 步:使用 Gensim 创建 Word2Vec 模型
ML/DL 算法不能直接访问文本,这就是为什么我们需要一些数字表示以便这些算法可以处理数据。在简单的机器学习应用程序中,使用 CountVectorizer 和 TFIDF,它们不保留单词之间的关系。
Word2Vec:表示文本以生成 Word Embeddings 的方法,该方法将语言中存在的所有单词映射到给定维度的向量空间。我们可以对这些向量执行数学运算,这有助于保持单词之间的关系。
可以使用Gensim 下载器 API下载预构建的词嵌入模型,如 word2vec、GloVe、fasttext 等。有时,您可能无法在文档中找到某些词的词嵌入。所以你可以训练你的模型。
4.1) 训练模型
代码:
蟒蛇3
import gensim.downloader as api
from multiprocessing import cpu_count
from gensim.models.word2vec import Word2Vec
# load the text8 dataset
dataset = api.load("text8")
# extract a list of words from the dataset
data =[]
for word in dataset:
data.append(word)
# We will split the data into two parts
data_1 = data[:1200] # this is used to train the model
data_2 = data[1200:] # this part will be used to update the model
# Training the Word2Vec model
w2v_model = Word2Vec(data_1, min_count = 0, workers = cpu_count())
# word vector for the word "time"
print(w2v_model['time'])
输出:
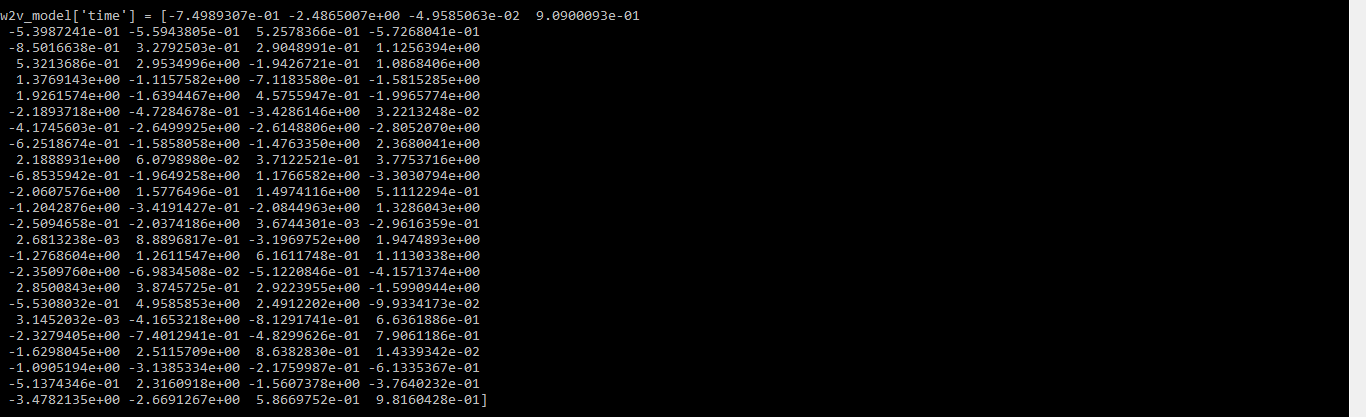
词时间的词向量
您还可以使用 most_similar()函数来查找与给定单词相似的单词。
代码:
蟒蛇3
# similar words to the word "time"
print(w2v_model.most_similar('time'))
# save your model
w2v_model.save('Word2VecModel')
# load your model
model = Word2Vec.load('Word2VecModel')
输出:

与“时间”最相似的词
4.2) 更新模型
代码:
蟒蛇3
# build model vocabulary from a sequence of sentences
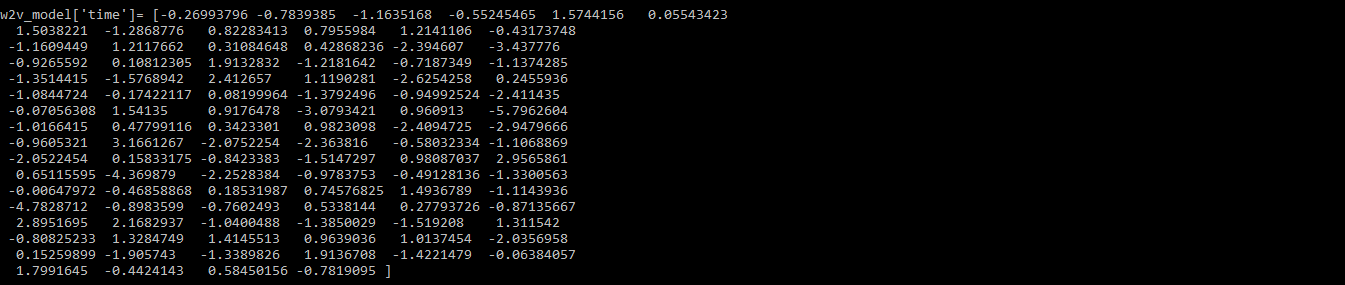
w2v_model.build_vocab(data_2, update = True)
# train word vectors
w2v_model.train(data_2, total_examples = w2v_model.corpus_count, epochs = w2v_model.iter)
print(w2v_model['time'])
输出:
第 5 步:使用 Gensim 创建 Doc2Vec 模型
与 Word2Vec 模型相比,Doc2Vec 模型给出了整个文档或一组词的向量表示。借助这个模型,我们可以找到不同文档之间的关系,例如-
If we train the model for literature such as "Through the Looking Glass".We can say that- 
5.1) 训练模型
代码:
蟒蛇3
import gensim
import gensim.downloader as api
from gensim.models import doc2vec
# get dataset
dataset = api.load("text8")
data =[]
for w in dataset:
data.append(w)
# To train the model we need a list of tagged documents
def tagged_document(list_of_ListOfWords):
for x, ListOfWords in enumerate(list_of_ListOfWords):
yield doc2vec.TaggedDocument(ListOfWords, [x])
# training data
data_train = list(tagged_document(data))
# print trained dataset
print(data_train[:1])
输出:

OUTPUT – 训练数据集
5.2) 更新模型代码:
蟒蛇3
# Initialize the model
d2v_model = doc2vec.Doc2Vec(vector_size = 40, min_count = 2, epochs = 30)
# build the vocabulary
d2v_model.build_vocab(data_train)
# Train Doc2Vec model
d2v_model.train(data_train, total_examples = d2v_model.corpus_count, epochs = d2v_model.epochs)
# Analyzing the output
Analyze = d2v_model.infer_vector(['violent', 'means', 'to', 'destroy'])
print(Analyze)
输出:

更新模型的输出
第 6 步:使用 LDA 创建主题模型
LDA 是一种流行的主题建模方法,它将每个文档视为一定比例的主题集合。我们需要剔除高质量的主题,例如它们的隔离性和意义。高质量的主题取决于-
- 文本处理的质量
- 找到最佳主题数
- 算法的调优参数
NOTE: If you run this code on python3.7 version you might get a StopIteration Error.
It is advisable to use python3.6 version for this.按照以下步骤创建模型:
6.1 准备数据
这是通过删除停用词然后将其词形还原来完成的。为了使用 Gensim 进行词形还原,我们需要首先下载模式包和停用词。
#download pattern package
pip install pattern
#run in python console
>> import nltk
>> nltk.download('stopwords')代码:
蟒蛇3
import gensim
from gensim import corpora
from gensim.models import LdaModel, LdaMulticore
import gensim.downloader as api
from gensim.utils import simple_preprocess, lemmatize
# from pattern.en import lemma
import nltk
# nltk.download('stopwords')
from nltk.corpus import stopwords
import re
import logging
logging.basicConfig(format ='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level = logging.INFO)
# import stopwords
stop_words = stopwords.words('english')
# add stopwords
stop_words = stop_words + ['subject', 'com', 'are', 'edu', 'would', 'could']
# import the dataset
dataset = api.load("text8")
data = [w for w in dataset]
# Preparing the data
processed_data = []
for x, doc in enumerate(data[:100]):
doc_out = []
for word in doc:
if word not in stop_words: # to remove stopwords
Lemmatized_Word = lemmatize(word, allowed_tags = re.compile('(NN|JJ|RB)')) # lemmatize
if Lemmatized_Word:
doc_out.append(Lemmatized_Word[0].split(b'/')[0].decode('utf-8'))
else:
continue
processed_data.append(doc_out) # processed_data is a list of list of words
# Print sample
print(processed_data[0][:10])
输出:

输出 - 处理数据
6.2 创建字典和语料库
处理后的数据现在将用于创建字典和语料库。
代码:
蟒蛇3
# create dictionary and corpus
dict = corpora.Dictionary(processed_data)
Corpus = [dict.doc2bow(l) for l in processed_data]
6.3 训练LDA模型
我们将使用之前创建的字典和语料库训练具有 5 个主题的 LDA 模型。这里使用了 LdaModel( )函数,但您也可以使用 LdaMulticore( )函数,因为它允许并行处理。
代码:
蟒蛇3
# Training
LDA_model = LdaModel(corpus = LDA_corpus, num_topics = 5)
# save model
LDA_model.save('LDA_model.model')
# show topics
print(LDA_model.print_topics(-1))
输出:

输出 - 主题
可以在多个主题中看到且相关性较低的词可以添加到停用词列表中。
6.4 解释输出
LDA 模型主要为我们提供有关 3 件事的信息:
- 文档中的主题
- 每个词属于什么主题
- φ值
Phi 值:它是一个单词出现在特定主题中的概率。对于给定的单词,phi 值的总和给出了该单词在文档中出现的次数。
代码:
蟒蛇3
# probability of a word belonging to a topic
LDA_model.get_term_topics('fire')
bow_list =['time', 'space', 'car']
# convert to bag of words format first
bow = LDA_model.id2word.doc2bow(bow_list)
# interpreting the data
doc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics = True)
步骤 7:使用 LSI 创建主题模型
要使用 LSI 创建模型,只需按照与 LDA 相同的步骤操作即可。唯一的区别在于训练模型时。
使用 LsiModel( )函数而不是 LdaMulticore( ) 或 LdaModel( )。
代码:
蟒蛇3
# Training the model with LSI
LSI_model = LsiModel(corpus = Corpus, id2word = dct, num_topics = 7, decay = 0.5)
# Topics
print(LSI_model.print_topics(-1))
第 8 步:计算相似度矩阵
余弦相似度:它是内积空间的两个非零向量之间相似度的度量。它被定义为等于它们之间夹角的余弦。
软余弦相似度:与余弦相似度相似,不同之处在于余弦相似度将向量空间模型(VSM)的特征视为独立的,而软余弦则提出在VSM中考虑特征的相似度。
我们需要采用词嵌入模型来计算软余弦。
这里我们使用的是预先训练好的 word2vec 模型。
Note: If you run this code on python3.7 version you might get a StopIteration Error.
It is advisable to use python3.6 version for this.代码:
蟒蛇3
import gensim.downloader as api
from gensim.matutils import softcossim
from gensim import corpora
s1 = ' Afghanistan is an Asian country and capital is Kabul'.split()
s2 = 'India is an Asian country and capital is Delhi'.split()
s3 = 'Greece is an European country and capital is Athens'.split()
# load pre-trained model
word2vec_model = api.load('word2vec-google-news-300')
# Prepare the similarity matrix
similarity_matrix = word2vec_model.similarity_matrix(dictionary, tfidf = None, threshold = 0.0, exponent = 2.0, nonzero_limit = 100)
# Prepare a dictionary and a corpus.
docs = [s1, s2, s3]
dictionary = corpora.Dictionary(docs)
# Convert the sentences into bag-of-words vectors.
s1 = dictionary.doc2bow(s1)
s2 = dictionary.doc2bow(s2)
s3 = dictionary.doc2bow(s3)
# Compute soft cosine similarity
print(softcossim(s1, s2, similarity_matrix)) # similarity between s1 &s2
print(softcossim(s1, s3, similarity_matrix)) # similarity between s1 &s3
print(softcossim(s2, s3, similarity_matrix)) # similarity between s2 &s3
下面提到了可以为这个词嵌入模型计算的一些相似性和距离度量:
代码:
蟒蛇3
# Find Odd one out
print(word2vec_model.doesnt_match(['india', 'bhutan', 'china', 'mango']))
#> mango
# cosine distance between two words.
word2vec_model.distance('man', 'woman')
# cosine distances from given word or vector to other words.
word2vec_model.distances('king', ['queen', 'man', 'woman'])
# Compute cosine similarities
word2vec_model.cosine_similarities(word2vec_model['queen'],
vectors_all =(word2vec_model['king'],
word2vec_model['woman'],
word2vec_model['man'],
word2vec_model['king'] + word2vec_model['woman']))
# king + woman is very similar to queen.
# words closer to w1 than w2
word2vec_model.words_closer_than(w1 ='queen', w2 ='kingdom')
# top-N most similar words.
word2vec_model.most_similar(positive ='king', negative = None, topn = 5, restrict_vocab = None, indexer = None)
# top-N most similar words, using the multiplicative combination objective,
word2vec_model.most_similar_cosmul(positive ='queen', negative = None, topn = 5)
步骤 9:总结文本文档
summarise()函数实现了文本排名汇总。
您不必通过拆分句子来生成标记化列表,因为 gensim.summarization.textcleaner 模块已经处理了这一点。
代码:
蟒蛇3
from gensim.summarization import summarize, keywords
import os
text = " ".join((l for l in open('sample_data.txt', encoding ='utf-8')))
# Summarize the paragraph
print(summarize(text, word_count = 25))
输出:

输出 - 总结
您可以通过以下方式获取关键字:
代码:
蟒蛇3
# Important keywords from the paragraph
print(keywords(text))

输出 - 关键字
结论:
这些是 Gensim 库的一些功能。当您进行语言处理时,这会非常方便。您可以根据需要使用这些功能。
如有任何疑问,请随时在下方发表评论。