用于查找表中重复名称的 SQL 查询
数据库中的重复记录有时会产生问题,因为它们会造成混乱,或者也可能会产生错误的输出。因此,最好从数据库中删除所有重复记录,因为这样可以节省我们的时间和空间。但是,最佳实践是在表上放置唯一约束(主键约束)以防止这种情况发生。
此错误可能是由于各种原因,例如 -
- 应用缺陷,
- 用户错误
- 糟糕的数据库设计
- 或者因为一些未知的外部来源。
因此,在本文中,我们将在表中查找重复的名称。要进行该查询,我们需要了解 GROUP BY 语句和聚合函数(特别是COUNT() )。
我们建议您首先阅读本文以便更好地理解。
要在表中查找重复的名称,我们必须按照以下步骤操作:
- 定义条件:首先,您需要定义查找重复名称的条件。您可能希望在单个列或更多列中进行搜索。
- 编写查询:然后只需编写查询以查找重复的名称。
让我们开始吧-
假设您正在使用电子商务网站的数据库。现在,一些用户名被保存了不止一次,他们的电子邮件 ID 也是如此。这将导致电子商务网站出现错误的分析结果,因为没有必要多次保存这些数据。
现在让我们首先创建我们的演示数据库,
第一步:创建数据库
创建一个名为 User_details 的新数据库,然后使用它。
询问:
CREATE DATABASE User_details; USE User_details; 输出:

第 2 步:定义表
创建一个名为 Users1 的表并添加这四列 ID、Names、EmailId 和 Age。
询问:
CREATE Table Users1 (ID VARCHAR(20) Primary Key,
Names VARCHAR(30), EmailId VARCHAR(30), Age INT); 输出:

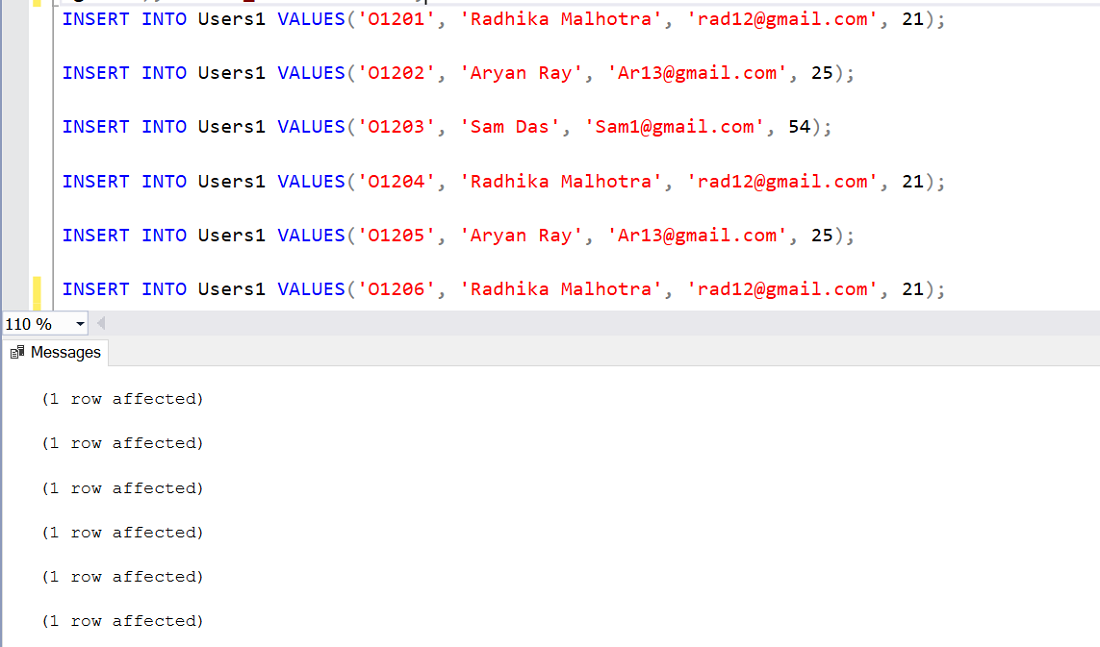
第 3 步:在表中插入行并将这六行插入到表中。
询问:
INSERT INTO Users1 VALUES('O1201', 'Radhika Malhotra', 'rad12@gmail.com', 21);
INSERT INTO Users1 VALUES('O1202', 'Aryan Ray', 'Ar13@gmail.com', 25);
INSERT INTO Users1 VALUES('O1203', 'Sam Das', 'Sam1@gmail.com', 54);
INSERT INTO Users1 VALUES('O1204', 'Radhika Malhotra', 'rad12@gmail.com', 21);
INSERT INTO Users1 VALUES('O1205', 'Aryan Ray', 'Ar13@gmail.com', 25);
INSERT INTO Users1 VALUES('O1206', 'Radhika Malhotra', 'rad12@gmail.com', 21); 输出:
第 4 步:查看插入的数据
运行此命令以查看我们的表。
询问:
SELECT * FROM Users1; 输出:
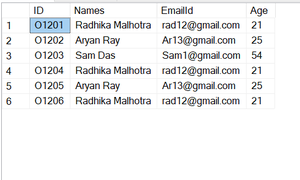
用户1表
第 5 步:现在,让我们查询此表中的重复名称。
- 定义标准:这里我们定义标准,仅从 Users1 表中选择 Names 列。
询问:
SELECT Names,COUNT(*) AS Occurrence FROM
Users1 GROUP BY Names HAVING COUNT(*)>1; 这个查询很简单。在这里,我们使用 GROUP BY 子句对 Names 列中的相同行进行分组。然后我们使用 COUNT()函数查找该列中的重复数,并在名为 Occurrence 的新列中显示该数据。有一个子句只保留出现不止一次的组。
输出:

我们在表中找到了重复的名称及其出现次数。这些信息可以帮助我们将来从表中删除重复的行。