使用Python从 Geeksforgeeks 文章中提取作者信息
在本文中,我们将编写一个Python脚本来从 GeeksforGeeks 文章中提取作者信息。
需要的模块
- bs4: Beautiful Soup(bs4) 是一个Python库,用于从 HTML 和 XML 文件中提取数据。这个模块没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install bs4- requests : Requests 允许您非常轻松地发送 HTTP/1.1 请求。这个模块也没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install requests方法:
- 导入模块
- 制作请求实例并传入 URL
- 初始化文章标题
- 将 URL 传递到 getdata()
- 在请求和 Beautiful Soup 的帮助下抓取数据
- 找到所需的详细信息并过滤它们。
逐步执行脚本:
第一步:导入所有依赖
Python
# import module
import requests
from bs4 import BeautifulSoupPython3
# link for extract html data
# Making a GET request
def getdata(url):
r=requests.get(url)
return r.textPython3
# input article by geek
article = "optparse-module-in-python"
# url
url = "https://www.geeksforgeeks.org/"+article
# pass the url
# into getdata function
htmldata=getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# display html code
print(soup)Python
# traverse author name
for i in soup.find('div', class_="author_handle"):
Author = i.get_text()
print(Author)Python3
# now get author information
# with author name
profile ='https://auth.geeksforgeeks.org/user/'+Author+'/profile'
# pass the url
# into getdata function
htmldata=getdata(profile)
soup = BeautifulSoup(htmldata, 'html.parser')Python3
# traverse information of author
name = soup.find(
'div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold medText').get_text()
author_info = []
for item in soup.find_all('div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold'):
author_info.append(item.get_text())
print("Author name :")
print(name)
print("Author information :")
print(author_info)Python3
# import module
import requests
from bs4 import BeautifulSoup
# link for extract html data
# Making a GET request
def getdata(url):
r = requests.get(url)
return r.text
# input article by geek
article = "optparse-module-in-python"
# url
url = "https://www.geeksforgeeks.org/"+article
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# traverse author name
for i in soup.find('div', class_="author_handle"):
Author = i.get_text()
# now get author information
# with author name
profile = 'https://auth.geeksforgeeks.org/user/'+Author+'/profile'
# pass the url
# into getdata function
htmldata = getdata(profile)
soup = BeautifulSoup(htmldata, 'html.parser')
# traverse information of author
name = soup.find(
'div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold medText').get_text()
author_info = []
for item in soup.find_all('div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold'):
author_info.append(item.get_text())
print("Author name :", name)
print("Author information :")
print(author_info)
第 2 步:创建 URL 获取函数
蟒蛇3
# link for extract html data
# Making a GET request
def getdata(url):
r=requests.get(url)
return r.text
第 3 步:现在将文章名称合并到 URL 并将 URL 传递到 getdata()函数并将该数据转换为 HTML 代码
蟒蛇3
# input article by geek
article = "optparse-module-in-python"
# url
url = "https://www.geeksforgeeks.org/"+article
# pass the url
# into getdata function
htmldata=getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# display html code
print(soup)
输出:
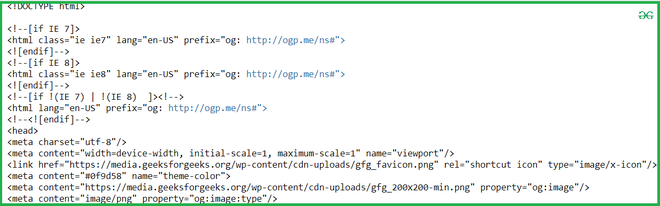
第 4 步:从 HTML 文档中遍历作者姓名。
Python
# traverse author name
for i in soup.find('div', class_="author_handle"):
Author = i.get_text()
print(Author)
输出:
kumar_satyam第 5 步:现在创建一个带有作者姓名的 URL 并获取 HTML 代码。
蟒蛇3
# now get author information
# with author name
profile ='https://auth.geeksforgeeks.org/user/'+Author+'/profile'
# pass the url
# into getdata function
htmldata=getdata(profile)
soup = BeautifulSoup(htmldata, 'html.parser')
第六步:遍历作者信息。
蟒蛇3
# traverse information of author
name = soup.find(
'div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold medText').get_text()
author_info = []
for item in soup.find_all('div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold'):
author_info.append(item.get_text())
print("Author name :")
print(name)
print("Author information :")
print(author_info)
输出:
Author name : Satyam Kumar
Author information :
[‘LNMI patna’, ‘\nhttps://www.linkedin.com/in/satyam-kumar-174273101/’]
完整代码:
蟒蛇3
# import module
import requests
from bs4 import BeautifulSoup
# link for extract html data
# Making a GET request
def getdata(url):
r = requests.get(url)
return r.text
# input article by geek
article = "optparse-module-in-python"
# url
url = "https://www.geeksforgeeks.org/"+article
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# traverse author name
for i in soup.find('div', class_="author_handle"):
Author = i.get_text()
# now get author information
# with author name
profile = 'https://auth.geeksforgeeks.org/user/'+Author+'/profile'
# pass the url
# into getdata function
htmldata = getdata(profile)
soup = BeautifulSoup(htmldata, 'html.parser')
# traverse information of author
name = soup.find(
'div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold medText').get_text()
author_info = []
for item in soup.find_all('div', class_='mdl-cell mdl-cell--9-col mdl-cell--12-col-phone textBold'):
author_info.append(item.get_text())
print("Author name :", name)
print("Author information :")
print(author_info)
输出:
Author name : Satyam Kumar
Author information :
[‘LNMI patna’, ‘\nhttps://www.linkedin.com/in/satyam-kumar-174273101/’]