使用 Pandas 处理 excel 文件
Excel工作表是IT行业中最普遍的文件形式之一。每次使用计算机的每个人都遇到过并使用过 Excel 电子表格。 excel的这种流行是由于它在以表格和系统形式存储和操作数据领域的广泛应用。此外,Excel 工作表非常直观且用户友好,这使得它非常适合操作大型数据集,即使对于技术含量较低的人员也是如此。如果您正在寻找学习使用Python操作和自动化 excel 文件中的内容的地方,请不要再找了。你是在正确的地方。
在本文中,您将学习如何使用 Pandas 处理 Excel 电子表格。在文章的最后,您将掌握以下知识:
- 为此所需的必要模块以及如何在系统中设置它们。
- 使用Python将数据从 excel 文件读取到 pandas 中。
- 在 Pandas 中探索 excel 文件中的数据。
- 使用函数来操作和重塑 Pandas 中的数据。
安装
要在 Anaconda 中安装 pandas,我们可以在 Anaconda 终端中使用以下命令:
conda install pandas
要在常规Python (非 Anaconda)中安装 pandas,我们可以在命令提示符下使用以下命令:
pip install pandas
入门
首先,我们需要导入 pandas 模块,这可以通过运行命令来完成:
import pandas as pds
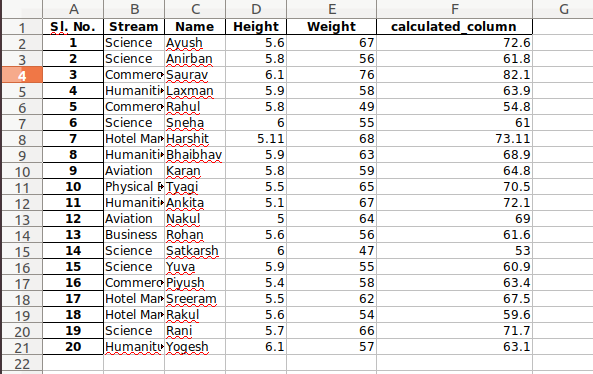
输入文件:假设excel文件看起来像这样
表 1: 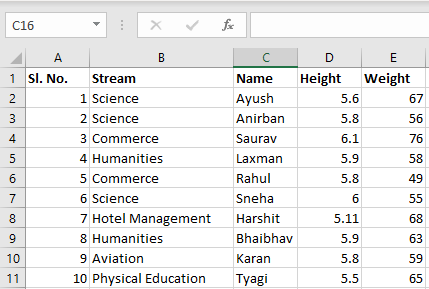
表 2:
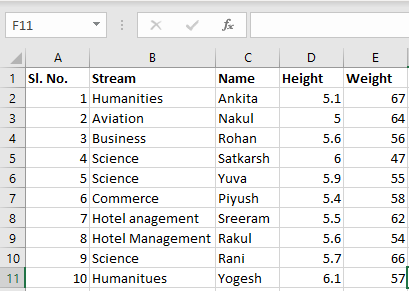
现在我们可以使用pandas中的read_excel函数导入excel文件了,如下图:
file =('path_of_excel_file')
newData = pds.read_excel(file)
newData
输出: 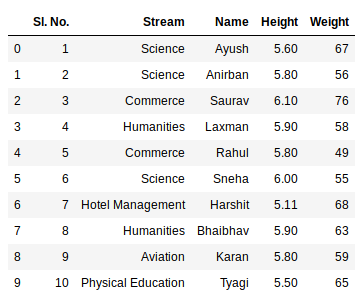
第二条语句从 excel 中读取数据并将其存储到由变量newData表示的 pandas 数据帧中。如果 excel 工作簿中有多个工作表,该命令将导入第一个工作表的数据。要使用工作簿中的所有工作表制作数据框,最简单的方法是分别创建不同的数据框,然后将它们连接起来。 read_excel 方法接受参数sheet_name和index_col ,我们可以在其中指定数据框应由哪个表组成, index_col指定标题列。
例子:
sheet1 = pds.read_excel(file,
sheet_name = 0,
index_col = 0)
sheet2 = pds.read_excel(file,
sheet_name = 1,
index_col = 0)
newData = pds.concat([sheet1, sheet2])
第三个语句连接两个工作表。现在要检查整个数据框,我们可以简单地运行以下命令:
newData
输出: 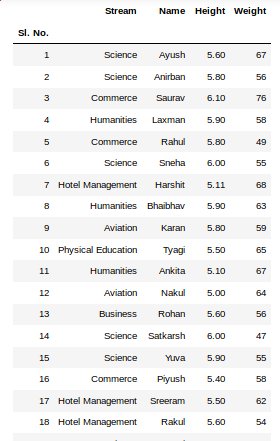
要从数据框的顶部和底部查看 5 列,我们可以运行以下命令:
newData.head()
newData.tail()
输出:
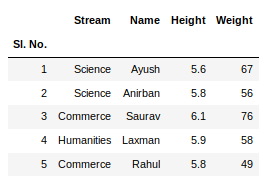
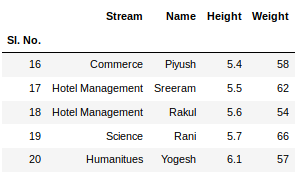
此head()和tail()方法还将参数作为要显示的列数的数字。
shape()方法可用于查看数据框中的行数和列数,如下所示:
newData.shape
输出:
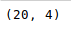
如果任何列包含数字数据,我们可以使用 pandas 中的sort_values()方法对该列进行排序,如下所示:
sorted_column = newData.sort_values(['Height'], ascending = False)
现在,假设我们想要排好序列的前 5 个值,我们可以在这里使用head()方法:
sorted_column['Height'].head(5)
输出: 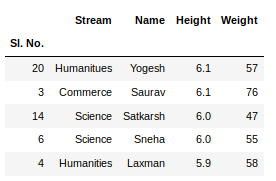
我们可以使用数据框的任何数字列来做到这一点,如下所示:
newData['Weight'].head()
输出: 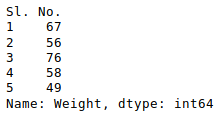
现在,假设我们的数据大部分是数字的。我们可以使用describe()方法获取数据帧的均值、最大值、最小值等统计信息,如下所示:
newData.describe()
输出: 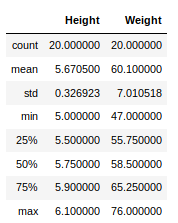
这也可以使用以下命令对所有数字列单独完成:
newData['Weight'].mean()
输出:
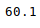
也可以使用相应的方法计算其他统计信息。
像在 excel 中一样,也可以应用公式并创建计算列,如下所示:
newData['calculated_column']= newData[“Height”] + newData[“Weight”]
newData['calculated_column'].head()
输出: 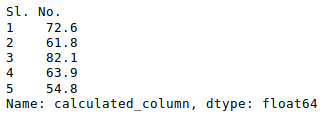
对数据框中的数据进行操作后,我们可以使用to_excel方法将数据导出回 excel 文件。为此,我们需要指定一个输出 excel 文件,将转换后的数据写入其中,如下所示:
newData.to_excel('Output File.xlsx')
输出: