深度 Q 学习
先决条件: Q-Learning
Q-Learning 的过程为工作代理创建了一个精确的矩阵,从长远来看,它可以“参考”以最大化其奖励。虽然这种方法本身并没有错,但这只适用于非常小的环境,并且当环境中的状态和动作的数量增加时,它很快就会失去可行性。
上述问题的解决方案来自于认识到矩阵中的值仅具有相对重要性,即这些值仅相对于其他值具有重要性。因此,这种想法将我们引向了Deep Q-Learning ,它使用深度神经网络来近似值。只要保持相对重要性,这种近似值就不会受到伤害。
深度 Q 学习的基本工作步骤是将初始状态输入神经网络,并将所有可能动作的 Q 值作为输出返回。
Q-Learning 和 Deep Q-Learning 的区别如下:-

伪代码:
初始化 对于所有对 (s,a) s = 初始状态 k = 0 而(未实现收敛){ 模拟动作 a 并达到状态 s' 如果(s' 是终端状态) { 目标 = R(s,a,s ') } else { 目标 = R(s,a,s') +
对于所有对 (s,a) s = 初始状态 k = 0 而(未实现收敛){ 模拟动作 a 并达到状态 s' 如果(s' 是终端状态) { 目标 = R(s,a,s ') } else { 目标 = R(s,a,s') +  }
} ![\theta _{k+1} = \theta _{k}-\alpha \Delta _{\theta }E_{s'~P(s'|s,a)}[(Q_{\theta }(s,a)-target(s'))^{2}]|_{\theta = \theta _{k}}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Deep_Q-Learning_4.png "由 QuickLaTeX.com 渲染") s = s' }
s = s' }
观察方程中的目标 = R(s,a,s') +  , 术语
, 术语 是一个变量项。因此,在这个过程中,神经网络的目标是可变的,不像其他典型的深度学习过程中目标是固定的。
是一个变量项。因此,在这个过程中,神经网络的目标是可变的,不像其他典型的深度学习过程中目标是固定的。
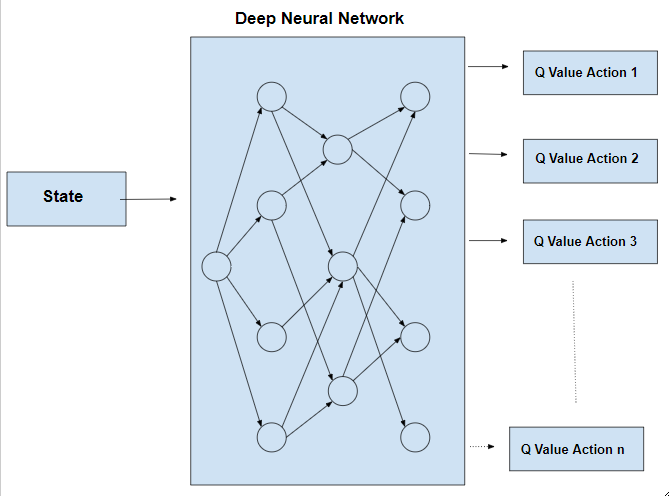
通过使用两个神经网络而不是一个来克服这个问题。一个神经网络用于调整网络的参数,另一个用于计算目标,与第一个网络具有相同的架构,但具有冻结参数。在主网络中迭代 x 次后,将参数复制到目标网络。