使用双向 LSTM 进行情绪检测
情绪检测是当今研究中最热门的话题之一。情感感应技术可以促进机器与人类之间的交流。它还将有助于改进决策过程。已经提出了许多机器学习模型来识别文本中的情绪。但是,在本文中,我们的重点是双向 LSTM 模型。 BiLSTM 中的双向 LSTM 是常规 LSTM 的补充,用于增强模型在序列分类问题上的性能。 BiLSTM 使用两个 LSTM 来训练顺序输入。第一个 LSTM 按原样用于输入序列。第二个 LSTM 用于输入序列的反向表示。它有助于补充额外的上下文并使我们的模型快速。
我们使用的数据集是 ISEAR(国际情绪前因和反应调查)。这是数据集的一瞥。

ISEAR 数据集
ISEAR 数据集包含 7652 个句子。它共有七种情绪,分别是:喜、惧、怒、悲、内疚、羞耻和厌恶。
让我们一步一步地制作预测情绪的模型。
步骤 1:导入所需的库
Python3
# Importing the required libraries
import keras
import numpy as np
from keras.models import Sequential,Model
from keras.layers import Dense,Bidirectional
from nltk.tokenize import word_tokenize,sent_tokenize
from keras.layers import *
from sklearn.model_selection import cross_val_score
import nltk
import pandas as pd
nltk.download('punkt')Python3
df=pd.read_csv('isear.csv',header=None)
# The isear.csv contains rows with value 'No response'
# We need to remove such rows
df.drop(df[df[1] == '[ No response.]'].index, inplace = True)Python3
# The feel_arr will store all the sentences
# i.e feel_arr is the list of all sentences
feel_arr = df[1]
# Each sentence in feel_arr is tokenized by the help of work tokenizer.
# If I have a sentence - 'I am happy'.
# After word tokenizing it will convert into- ['I','am','happy']
feel_arr = [word_tokenize(sent) for sent in feel_arr]
print(feel_arr[0])Python3
# Defined a function padd in which each sentence length is fixed to 100.
# If length is less than 100 , then the word- '' is append
def padd(arr):
for i in range(100-len(arr)):
arr.append('')
return arr[:100]
# call the padd function for each sentence in feel_arr
for i in range(len(feel_arr)):
feel_arr[i]=padd(feel_arr[i]) Python3
# Glove vector contains a 50 dimensional vector corresponding to each word in dictionary.
vocab_f = 'glove.6B.50d.txt'
# embeddings_index is a dictionary which contains the mapping of
# word with its corresponding 50d vector.
embeddings_index = {}
with open(vocab_f, encoding='utf8') as f:
for line in f:
# splitting each line of the glove.6B.50d in a list of items- in which
# the first element is the word to be embedded, and from second
# to the end of line contains the 50d vector.
values = line.rstrip().rsplit(' ')
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
# Now, each word of the dataset should be embedded in 50d vector with
# the help of the dictionary form above.
# Embedding each word of the feel_arr
embedded_feel_arr = []
for each_sentence in feel_arr:
embedded_feel_arr.append([])
for word in each_sentence:
if word.lower() in embeddings_index:
embedded_feel_arr[-1].append(embeddings_index[word.lower()])
else:
# if the word to be embedded is '' append 0 fifty times
embedded_feel_arr[-1].append([0]*50) Python3
#Converting x into numpy-array
X=np.array(embedded_feel_arr)
print(np.shape(X))
# Perform one-hot encoding on df[0] i.e emotion
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
Y = enc.fit_transform(np.array(df[0]).reshape(-1,1)).toarray()
# Split into train and test
from keras.layers import Embedding
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
#Defining the BiLSTM Model
def model(X,Y,input_size1,input_size2,output_size):
m=Sequential()
# Here 100 denotes the dimesionality of output spaces.
m.add(Bidirectional(LSTM(100,input_shape=(input_size1,input_size2))))
m.add(Dropout(0.5))
m.add(Dense(output_size,activation='softmax'))
m.compile('Adam','categorical_crossentropy',['accuracy'])
m.fit(X,Y,epochs=32, batch_size=128)
return mPython3
# Training the model
bilstmModel=model(X_train,Y_train,100,50,7)Python3
#Testing the model
bilstmModel.evaluate(X_test,Y_test)第 2 步:下一步是从我们的机器加载数据集并对其进行预处理。在数据集中,有一些行包含 -'No response'。这句话对我们来说完全没用。因此,我们将删除此类行。
读取数据集并对其进行预处理
蟒蛇3
df=pd.read_csv('isear.csv',header=None)
# The isear.csv contains rows with value 'No response'
# We need to remove such rows
df.drop(df[df[1] == '[ No response.]'].index, inplace = True)
第 3 步:应用单词标记器将每个句子转换为单词列表。示例:如果有一句话 - '我很高兴' 。在单词标记化之后,它会被转换成一个列表 ['I','am','happy']。
单词标记化
蟒蛇3
# The feel_arr will store all the sentences
# i.e feel_arr is the list of all sentences
feel_arr = df[1]
# Each sentence in feel_arr is tokenized by the help of work tokenizer.
# If I have a sentence - 'I am happy'.
# After word tokenizing it will convert into- ['I','am','happy']
feel_arr = [word_tokenize(sent) for sent in feel_arr]
print(feel_arr[0])
上面代码片段的输出是这样的:

单词标记化的输出
第四步:每个句子的长度不同。为了通过模型,每个句子的长度应该相等。通过可视化数据集,我们可以看到数据集中句子的长度不大于100个单词。所以,现在我们将每个句子转换为 100 个单词。为此,我们将借助填充。
应用填充
蟒蛇3
# Defined a function padd in which each sentence length is fixed to 100.
# If length is less than 100 , then the word- '' is append
def padd(arr):
for i in range(100-len(arr)):
arr.append('')
return arr[:100]
# call the padd function for each sentence in feel_arr
for i in range(len(feel_arr)):
feel_arr[i]=padd(feel_arr[i])
上面代码片段的输出是这样的:

填充后输出
5. 现在,每个词都需要嵌入一些数字表示中,因为模型只能理解数字。因此,为此,我们从互联网下载了一个 50 维的预定义手套向量。该向量用于词嵌入。每个词都表示为一个 50 维的向量。
手套向量几乎包含了英语词典的所有单词。
这是对手套向量的一些见解。

手套矢量
每行的第一个单词是要嵌入的字符。从一列到最后一列,有该字符的 50d 向量形式的数字表示。
使用手套进行词嵌入
蟒蛇3
# Glove vector contains a 50 dimensional vector corresponding to each word in dictionary.
vocab_f = 'glove.6B.50d.txt'
# embeddings_index is a dictionary which contains the mapping of
# word with its corresponding 50d vector.
embeddings_index = {}
with open(vocab_f, encoding='utf8') as f:
for line in f:
# splitting each line of the glove.6B.50d in a list of items- in which
# the first element is the word to be embedded, and from second
# to the end of line contains the 50d vector.
values = line.rstrip().rsplit(' ')
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
# Now, each word of the dataset should be embedded in 50d vector with
# the help of the dictionary form above.
# Embedding each word of the feel_arr
embedded_feel_arr = []
for each_sentence in feel_arr:
embedded_feel_arr.append([])
for word in each_sentence:
if word.lower() in embeddings_index:
embedded_feel_arr[-1].append(embeddings_index[word.lower()])
else:
# if the word to be embedded is '' append 0 fifty times
embedded_feel_arr[-1].append([0]*50)
在这里,在上面的例子中,形成的字典 ie embeddings_index包含单词及其对应的 50d 向量,为了可视化,让我们打印单词 -'happy' 的 50 维。

第 6 步:现在,我们已经完成了所有的预处理部分,现在我们需要执行以下操作:
- 对每种情绪进行一次热编码。
- 将数据集拆分为训练集和测试集。
- 在我们的数据集上训练模型。
- 在测试集上测试模型。
训练模型
蟒蛇3
#Converting x into numpy-array
X=np.array(embedded_feel_arr)
print(np.shape(X))
# Perform one-hot encoding on df[0] i.e emotion
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
Y = enc.fit_transform(np.array(df[0]).reshape(-1,1)).toarray()
# Split into train and test
from keras.layers import Embedding
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
#Defining the BiLSTM Model
def model(X,Y,input_size1,input_size2,output_size):
m=Sequential()
# Here 100 denotes the dimesionality of output spaces.
m.add(Bidirectional(LSTM(100,input_shape=(input_size1,input_size2))))
m.add(Dropout(0.5))
m.add(Dense(output_size,activation='softmax'))
m.compile('Adam','categorical_crossentropy',['accuracy'])
m.fit(X,Y,epochs=32, batch_size=128)
return m
训练模型
蟒蛇3
# Training the model
bilstmModel=model(X_train,Y_train,100,50,7)
这是建议模型的图表:
这里,输入的维度是 100 X 50,其中 100 是数据集的每个输入句子中的单词数,50 表示每个单词在 50d 向量中的映射。
Bidirectional(LSTM) 的输出是 200,因为上面我们已经定义了输出空间的维数为 100。因为它是 BiLSTM 模型,所以维数将为 100*2 =200,因为 BiLSTM 包含两个 LSTM 层 - 一个是前向的,一个是其他落后。
在添加此 dropout 层后,以防止过拟合。最后应用密集层将 200 个输出序列转换为 7 个,因为我们只有 7 个情绪,所以输出应该只有 7 个维度。
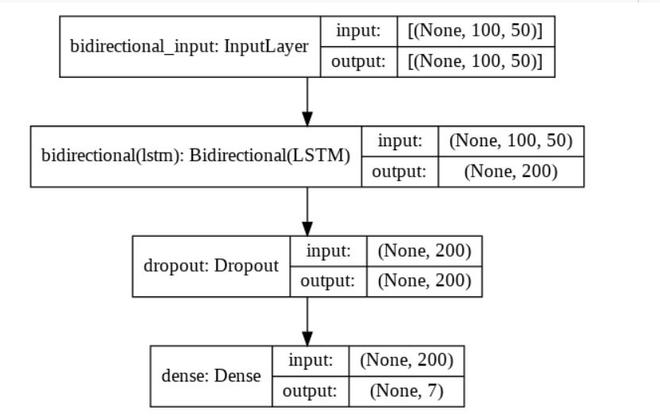
提议的 BiLSTM 模型
测试模型
蟒蛇3
#Testing the model
bilstmModel.evaluate(X_test,Y_test)
这是我们测试模型时的准确率。
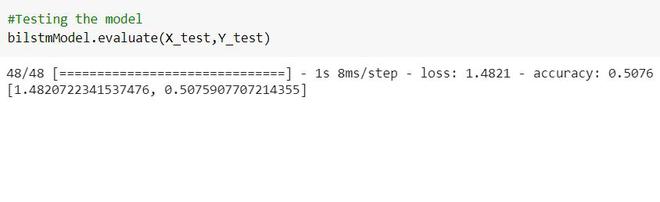
测试精度
要获取数据集和代码,请单击此处。