结构:
结构用于以相同的变量名称存储属于不同数据类型的数据。结构示例如下所示:
struct STUDENT
{
char[10] name;
int id;
};
用于上述结构的内存空间将如下分配:
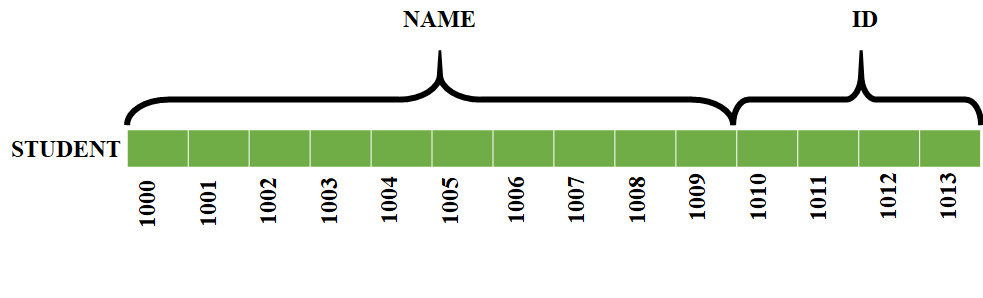
在这里,我们看到结构的成员之间没有空白。但是在某些情况下,结构中的成员之间会出现空白,这些空白称为松弛字节。
需要松弛字节吗?
在计算机和技术中,速度是非常重要的因素。我们总是试图以这样的方式进行设计和算法:对内存的访问要快得多,或者解决方案的获取要快得多。微处理器访问偶数地址中存在的数据的速度比奇数地址中存在的数据的访问速度快。因此,我们尝试以特定变量的起始地址在偶数地址中的方式分配数据的内存。
微处理器访问存储在偶数地址中的数据比存储在奇数地址中的数据更快。因此,编译器有责任为成员分配内存,以使它们甚至具有地址,以便可以非常快速地访问数据。这导致了松弛字节的概念。
备用字节:
经过优化的编译器将始终为结构的成员分配偶数地址,以便可以非常快速地访问数据。偶数地址可以是2、4、8或16的倍数。这会在某些成员的边界之间引入一些未使用的字节或空洞。这些未使用的字节或结构成员边界之间的漏洞称为松弛字节。
松弛字节不包含任何有用的信息,它们实际上是浪费的存储空间。但是,在使用松弛字节概念的情况下,数据的访问会更快。当使用松弛字节时,结构的大小将大于或等于该结构的各个成员的大小之和。一些经过优化的编译器会分配地址,以便每个成员的地址将是该结构最大数据类型大小的倍数。
示例:考虑以下结构声明:
struct EMPLOYEE
{
char name[8];
int id;
double salary;
};
在这里,我们看到double数据类型占用了最大的内存空间(假设double = 8个字节)。因此,每个成员将被分配一个内存地址,该地址是8的倍数,如下所示:
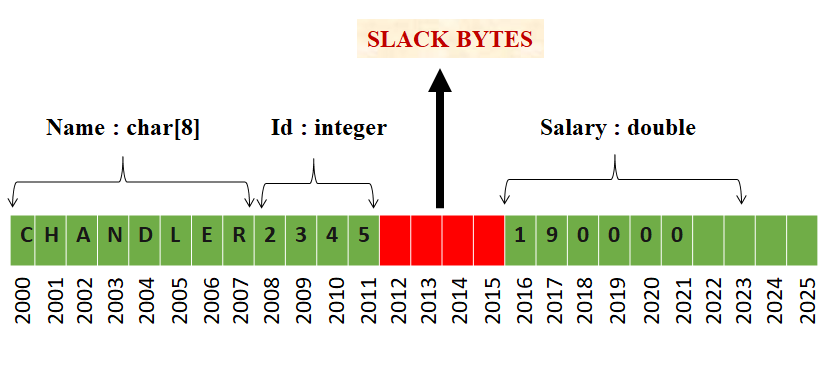
在这里观察到结构的所有成员都以一个8的地址开始,并且我们可以观察到之间的空白(红色阴影区域),这被称为松弛字节。
想要从精选的最佳视频中学习和练习问题,请查看《基础知识到高级C的C基础课程》。