如果您想编写大型程序或软件,则最常见的菜鸟错误是直接跳入并尝试将所有必需的代码写入单个程序,然后尝试调试或稍后扩展。
这种方法注定要失败,并且通常需要从头开始重写。
因此,为了解决这种情况,我们可以尝试将问题分为多个子问题,然后尝试一个接一个地解决。
这样做,不仅使我们的工作更加轻松,而且使我们能够从高级程序员那里实现抽象,并且还提高了代码的可重用性。
如果您从GitHub或GitLab或其他类似站点检查任何开源项目,我们将看到大型程序是如何“分散”为许多子模块的,其中每个单独的模块都对特定的关键函数做出了贡献该计划以及开放源代码社区的各种成员齐心协力,共同贡献或维护此类文件或存储库。
现在,最大的问题在于如何在理论上而非编程上“分解”。
我们将在流行的语言(例如C / C++, Python和Java看到这种划分的各种类型。
-
跳转到C / C++
-
跳到Python
-
跳到Java
C / C++
出于说明目的,
让我们假设我们在一个程序中拥有所有基本的链表插入。由于有许多方法(函数),因此我们不能通过在强制性主函数上方编写所有方法定义来使程序混乱。但是即使这样做,也会出现方法排序的问题,其中一种方法必须先于另一种,依此类推。
因此,要解决此问题,我们可以在程序的开头声明所有原型,然后声明main方法,然后在main方法下方,以任何特定顺序定义它们:
程序:
FullLinkedList.c
// Full Linked List Insertions
#include
#include
//--------------------------------
// Declarations - START:
//--------------------------------
struct Node;
struct Node* create_node(int data);
void b_insert(struct Node** head, int data);
void n_insert(struct Node** head, int data, int pos);
void e_insert(struct Node** head, int data);
void display(struct Node* temp);
//--------------------------------
// Declarations - END:
//--------------------------------
int main()
{
struct Node* head = NULL;
int ch, data, pos;
printf("Linked List: \n");
while (1) {
printf("1.Insert at Beginning");
printf("\n2.Insert at Nth Position");
printf("\n3.Insert At Ending");
printf("\n4.Display");
printf("\n0.Exit");
printf("\nEnter your choice: ");
scanf("%d", &ch);
switch (ch) {
case 1:
printf("Enter the data: ");
scanf("%d", &data);
b_insert(&head, data);
break;
case 2:
printf("Enter the data: ");
scanf("%d", &data);
printf("Enter the Position: ");
scanf("%d", &pos);
n_insert(&head, data, pos);
break;
case 3:
printf("Enter the data: ");
scanf("%d", &data);
e_insert(&head, data);
break;
case 4:
display(head);
break;
case 0:
return 0;
default:
printf("Wrong Choice");
}
}
}
//--------------------------------
// Definitions - START:
//--------------------------------
struct Node {
int data;
struct Node* next;
};
struct Node* create_node(int data)
{
struct Node* temp
= (struct Node*)
malloc(sizeof(struct Node));
temp->data = data;
temp->next = NULL;
return temp;
}
void b_insert(struct Node** head, int data)
{
struct Node* new_node = create_node(data);
new_node->next = *head;
*head = new_node;
}
void n_insert(struct Node** head, int data, int pos)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* new_node = create_node(data);
struct Node* temp = *head;
for (int i = 0; i < pos - 2; ++i)
temp = temp->next;
new_node->next = temp->next;
temp->next = new_node;
}
void e_insert(struct Node** head, int data)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* temp = *head;
while (temp->next != NULL)
temp = temp->next;
struct Node* new_node = create_node(data);
temp->next = new_node;
}
void display(struct Node* temp)
{
printf("The elements are:\n");
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}
//--------------------------------
// Definitions - END
//-------------------------------- linkedlist.h
// linkedlist.h
#ifndef LINKED_LIST_H
#define LINKED_LIST_H
struct Node {
int data;
struct Node* next;
};
void display(struct Node* temp);
#endifinsert.h
// insert.h
#ifndef INSERT_H
#define INSERT_H
struct Node;
struct Node* create_node(int data);
void b_insert(struct Node** head, int data);
void n_insert(struct Node** head, int data, int pos);
void e_insert(struct Node** head, int data);
#endifinsert.c
// insert.c
#include "linkedlist.h"
// "" to tell the preprocessor to look
// into the current directory and
// standard library files later.
#include
struct Node* create_node(int data)
{
struct Node* temp = (struct Node*)malloc(sizeof(struct Node));
temp->data = data;
temp->next = NULL;
return temp;
}
void b_insert(struct Node** head, int data)
{
struct Node* new_node = create_node(data);
new_node->next = *head;
*head = new_node;
}
void n_insert(struct Node** head, int data, int pos)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* new_node = create_node(data);
struct Node* temp = *head;
for (int i = 0; i < pos - 2; ++i)
temp = temp->next;
new_node->next = temp->next;
temp->next = new_node;
}
void e_insert(struct Node** head, int data)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* temp = *head;
while (temp->next != NULL)
temp = temp->next;
struct Node* new_node = create_node(data);
temp->next = new_node;
} linkedlist.c
// linkedlist.c
// Driver Program
#include "insert.h"
#include "linkedlist.h"
#include
void display(struct Node* temp)
{
printf("The elements are:\n");
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}
int main()
{
struct Node* head = NULL;
int ch, data, pos;
printf("Linked List: \n");
while (1) {
printf("1.Insert at Beginning");
printf("\n2.Insert at Nth Position");
printf("\n3.Insert At Ending");
printf("\n4.Display");
printf("\n0.Exit");
printf("\nEnter your choice: ");
scanf("%d", &ch);
switch (ch) {
case 1:
printf("Enter the data: ");
scanf("%d", &data);
b_insert(&head, data);
break;
case 2:
printf("Enter the data: ");
scanf("%d", &data);
printf("Enter the Position: ");
scanf("%d", &pos);
n_insert(&head, data, pos);
break;
case 3:
printf("Enter the data: ");
scanf("%d", &data);
e_insert(&head, data);
break;
case 4:
display(head);
break;
case 0:
return 0;
default:
printf("Wrong Choice");
}
}
} Point.py
# point.py
class Point:
def __init__(self):
self.x = int(input ("Enter the x-coordinate: "))
self.y = int(input ("Enter the y-coordinate: "))
def distance (self, other):
return ((self.x - other.x)**2 + (self.y - other.y)**2) ** 0.5
if __name__ == "__main__":
print("Point 1")
p1 = Point ()
print("\nPoint 2")
p2 = Point ()
print( "Distance between the 2 points is {:.4f}".format (p1.distance(p2)))Helper.py
# Helper.py
class Point:
def __init__(self):
self.x = int(input ("Enter the x-coordinate: "))
self.y = int(input ("Enter the y-coordinate: "))
def distance (self, other):
return ((self.x - other.x)**2 + (self.y - other.y)**2) ** 0.5Main.py
# Main.py
from Helper import Point
def main ():
print("Point 1")
p1 = Point ()
print("\nPoint 2")
p2 = Point ()
print( "Distance between the 2 points is {:.4f}".format (p1.distance(p2)))
main ()Check.java
// Check.java
import java.util.*;
class Math {
static int check(int a, int b)
{
return a > b ? 'a' : 'b';
}
}
class Main {
public static void main(String args[])
{
Scanner s = new Scanner(System.in);
System.out.print("Enter value of a: ");
int a = s.nextInt();
System.out.print("Enter value of b: ");
int b = s.nextInt();
if (a == b)
System.out.println("Both Values are Equal");
else
System.out.printf("%c's value is Greater\n",
Math.check(a, b));
}
}Math.java
// Math.java
package foo;
public class Math {
public static int check(int a, int b)
{
return a > b ? 'A' : 'B';
}
}Main.java
// Main.java
// Driver Program
package foo;
import java.util.*;
class Main {
public static void main(String args[])
{
Scanner s = new Scanner(System.in);
System.out.print("Enter value of a: ");
int a = s.nextInt();
System.out.print("Enter value of b: ");
int b = s.nextInt();
if (a == b)
System.out.println("Both Values are Equal");
else
System.out.printf("%c's value is Greater\n",
Math.check(a, b));
}
}编译代码:我们可以通过以下方式编译以上程序:
gcc linkedlist.c -o linkedlist而且有效!
上面代码中的潜在问题:
我们已经看到了程序的潜在问题,无论是单独还是成组地使用代码都不是一件容易的事。
如果某人想使用上述程序,那么该人面临的许多问题中的一些是:
- 需要遍历完整源文件以改善或增强某些功能。
- 无法轻松地将该程序用作其他项目的框架。
- 代码非常混乱,一点也不吸引人,这使得浏览代码非常困难。
如果是小组项目或大型计划,则可以保证上述方法可以增加总支出,精力和故障率。
正确的方法:
我们在以“ #include”开头的每个C / C++程序中看到这些行。
这意味着包括所有在“ library”标头下声明的功能(.h文件),并可能在library.c / cpp文件中定义。
这些行在编译期间由预处理器处理。
我们可以出于自身目的手动尝试创建这样的库。
要记住的重要事项:
- “ .h”文件仅包含原型声明(例如,Functions,Structures)和全局变量。
- “ .c / .cpp”文件包含实际的实现(头文件中声明的定义)
- 将所有源文件编译在一起时,请确保同一项目的同一函数,变量等没有多个定义。 (很重要)
- 使用静态函数来限制声明它们的文件。
- 使用extern关键字可以使用引用外部文件的变量。
- 如果使用C++,请注意命名空间始终使用namespace_name :: 函数()以避免冲突。
将程序分成较小的代码:
查看上面的程序,我们可以看到如何将该大型程序划分为合适的小部分,然后轻松进行工作。
上面的程序本质上具有2个主要功能:
1)创建,插入数据并将其存储到节点中。
2)显示节点
因此,我可以对程序进行相应的划分,以便:
1)主文件->驱动程序,插入模块的Nice Wrapper,以及我们在其中使用其他文件的位置。
2)插入->实际实现位于此处。
牢记上述要点,该程序分为:
linkedlist.c -> Contains Driver Program
insert.c -> Contains Code for insertion
linkedlist.h -> Contains the necessary Node declarations
insert.h -> Contains the necessary Node Insertion Declarations
在每个头文件中,我们从以下内容开始:
#ifndef FILENAME_H
#define FILENAME_H
Declarations...
#endif
我们在#ifndef,#define和#endif之间编写声明的原因是,当在属于同一项目的新文件中调用同一头文件时,可以防止标识符的多个声明,例如数据类型,变量等。
对于此示例程序:
insert.h- >包含Node插入的声明以及Node本身的声明。
要记住的一件非常重要的事情是,编译器可以在头文件中看到声明,但是如果您尝试编写代码INVOLVING在其他地方声明的声明的定义,则会导致错误,因为编译器在进入链接阶段之前会分别编译每个.c文件。 。
linkedlist.h- >一个包含Node的帮助程序文件,它是使用它们的文件所包含的Display声明。
insert.c- >通过#include“ linkedlist.h”包含Node声明,该声明包含该声明以及在insert.h下声明的方法的所有其他定义。
linkedlist.c- > Simple Wrapper,包含无限循环,提示用户在所需位置插入Integer数据,并且还包含显示列表的方法。
要记住的最后一件事是,盲目地将文件彼此包括在内可能会导致多次重新定义并导致错误。
如果您仔细划分为合适的子程序,请记住以上几点。
链表
// linkedlist.h
#ifndef LINKED_LIST_H
#define LINKED_LIST_H
struct Node {
int data;
struct Node* next;
};
void display(struct Node* temp);
#endif
insert.h
// insert.h
#ifndef INSERT_H
#define INSERT_H
struct Node;
struct Node* create_node(int data);
void b_insert(struct Node** head, int data);
void n_insert(struct Node** head, int data, int pos);
void e_insert(struct Node** head, int data);
#endif
insert.c
// insert.c
#include "linkedlist.h"
// "" to tell the preprocessor to look
// into the current directory and
// standard library files later.
#include
struct Node* create_node(int data)
{
struct Node* temp = (struct Node*)malloc(sizeof(struct Node));
temp->data = data;
temp->next = NULL;
return temp;
}
void b_insert(struct Node** head, int data)
{
struct Node* new_node = create_node(data);
new_node->next = *head;
*head = new_node;
}
void n_insert(struct Node** head, int data, int pos)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* new_node = create_node(data);
struct Node* temp = *head;
for (int i = 0; i < pos - 2; ++i)
temp = temp->next;
new_node->next = temp->next;
temp->next = new_node;
}
void e_insert(struct Node** head, int data)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* temp = *head;
while (temp->next != NULL)
temp = temp->next;
struct Node* new_node = create_node(data);
temp->next = new_node;
}
链表
// linkedlist.c
// Driver Program
#include "insert.h"
#include "linkedlist.h"
#include
void display(struct Node* temp)
{
printf("The elements are:\n");
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}
int main()
{
struct Node* head = NULL;
int ch, data, pos;
printf("Linked List: \n");
while (1) {
printf("1.Insert at Beginning");
printf("\n2.Insert at Nth Position");
printf("\n3.Insert At Ending");
printf("\n4.Display");
printf("\n0.Exit");
printf("\nEnter your choice: ");
scanf("%d", &ch);
switch (ch) {
case 1:
printf("Enter the data: ");
scanf("%d", &data);
b_insert(&head, data);
break;
case 2:
printf("Enter the data: ");
scanf("%d", &data);
printf("Enter the Position: ");
scanf("%d", &pos);
n_insert(&head, data, pos);
break;
case 3:
printf("Enter the data: ");
scanf("%d", &data);
e_insert(&head, data);
break;
case 4:
display(head);
break;
case 0:
return 0;
default:
printf("Wrong Choice");
}
}
}
最后,我们将它们全部保存并按如下所示进行编译。
gcc insert.c linkedlist.c -o linkedlistVoila,它编译成功,让我们做一个快速的健全性检查,以防万一:
输出:

对于C++,除了保留通常的语言功能/实现更改外,其余大部分相同。
Python
在这里不是那么困难。通常,首先要做的是创建一个虚拟环境。这是必须的,以防止由于各种版本依赖性等而破坏一堆脚本。例如,您可能要为一个项目使用某个模块的1.0版,但是此最新版本不推荐使用0.9版中提供的功能,因此您希望对该新项目使用旧版本,或者只是想升级库而不会中断旧的和现有的项目。该解决方案是针对每个单独的项目/脚本的隔离环境。
如何设置虚拟环境:
如果尚未安装,请使用pip或pip3来安装virtualenv :
pip install virtualenv为每个项目/脚本设置隔离环境:
下一步导航到某个目录来存储您的项目,然后:
virtualenv app_Name # (Or)
virtualenv -p /path/to/py3(or)2.7 app_name # For specific interpreter dependency
source app_name/bin/activate # Start Working
deactivate # To Quit
现在,您可以使用pip安装所有所需的模块,它们可以独立于此隔离的项目,并且您无需担心系统范围内的脚本被破坏。例如:在激活虚拟环境和源的情况下,
pip install pip install pandas==0.22.0要做的重要一件事是创建一个名为的显式空文件:
__init__.py这样做是为了将目录视为包含软件包并访问目录内的子模块。如果不创建这样的文件, Python将不会在项目目录中显式查找子模块,并且任何尝试访问它们的操作都会出错。
将先前保存的模块导入新文件:
现在,您可以使用以下两种方法之一将先前保存的模块导入到新文件中:
import module
from module import submodule # (or) from module.submodule import subsubmodule1, subsubmodule2
from module import * # (or) from module.submodule import *
第一行允许您通过module.feature()或module.variable访问引用。
第二行允许您直接访问引用的特定模块。例如:feature()
第三行允许您直接访问所有引用。例如:feature1(),feature2()等。
单个混乱文件的示例:
点
# point.py
class Point:
def __init__(self):
self.x = int(input ("Enter the x-coordinate: "))
self.y = int(input ("Enter the y-coordinate: "))
def distance (self, other):
return ((self.x - other.x)**2 + (self.y - other.y)**2) ** 0.5
if __name__ == "__main__":
print("Point 1")
p1 = Point ()
print("\nPoint 2")
p2 = Point ()
print( "Distance between the 2 points is {:.4f}".format (p1.distance(p2)))
看起来很奇怪的’ if __name__ ==“ __main__”: ‘用于防止在其他模块中导入其下的代码时执行。
我们可以简单地将Point Implementation提取到一个单独的文件中,并使用Main File来满足我们的确切要求。
将代码分成较小的部分:
本程序可以分为以下几类:
1)主文件->驱动程序,创建,操作和使用对象。
2)点文件->我们可以使用笛卡尔平面中的点定义的所有方法。
该示例程序包含:
Helper.py- >由Point类组成,该类包含距离等方法,并且还包含init方法,该方法有助于自动初始化所需的x和y变量。
Main.py- > Main Program创建2个对象并找到它们之间的距离。
帮手
# Helper.py
class Point:
def __init__(self):
self.x = int(input ("Enter the x-coordinate: "))
self.y = int(input ("Enter the y-coordinate: "))
def distance (self, other):
return ((self.x - other.x)**2 + (self.y - other.y)**2) ** 0.5
主程序
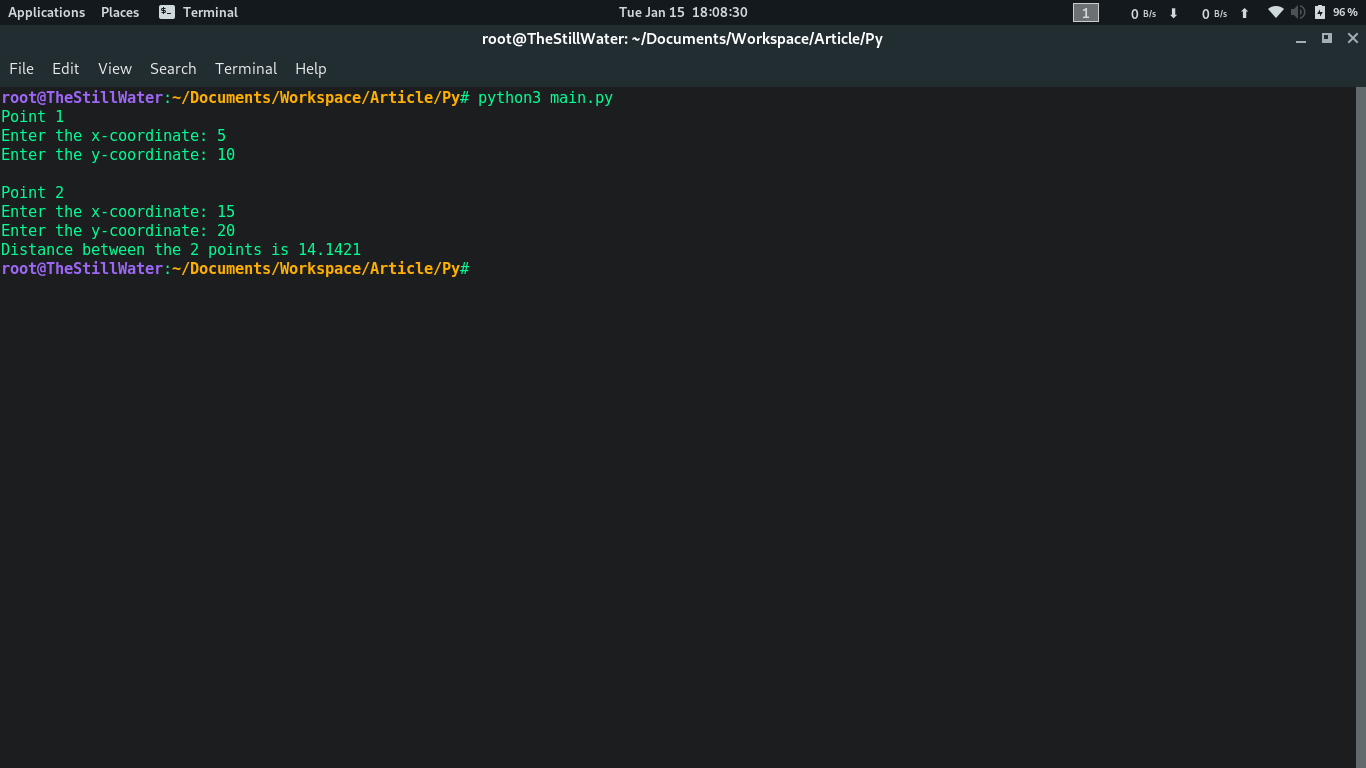
# Main.py
from Helper import Point
def main ():
print("Point 1")
p1 = Point ()
print("\nPoint 2")
p2 = Point ()
print( "Distance between the 2 points is {:.4f}".format (p1.distance(p2)))
main ()
输出:
Java
它类似于Python。导航到新目录以保存项目文件,并在所有子程序中编写:
package app_name;在起点上,像往常一样创建一个类。
再次编写以下代码,将模块导入新的Java程序:package app_name并简单地引用该特定模块。 函数(),因为它们属于同一包(存储在同一目录中),并且Java隐式添加了以下几行,但是如果您需要从不同的包中导入新模块,则可以通过以下方式进行:
import package.*;
import package.classname;
import static package.*;
Fully Qualified Name
// eg: package.classname ob = new classname ();
第一种和第二种外观与python的import…import语法相似,但您必须明确声明该类。为了实现从…导入语法样式的这种不推荐但pythonic的方式,您必须使用第三种方法,即,导入静态方法以实现类似的结果,但是您必须诉诸使用完全限定的名称来防止冲突和清理人员反正还是误会。
单个混乱文件的示例:
查看。Java
// Check.java
import java.util.*;
class Math {
static int check(int a, int b)
{
return a > b ? 'a' : 'b';
}
}
class Main {
public static void main(String args[])
{
Scanner s = new Scanner(System.in);
System.out.print("Enter value of a: ");
int a = s.nextInt();
System.out.print("Enter value of b: ");
int b = s.nextInt();
if (a == b)
System.out.println("Both Values are Equal");
else
System.out.printf("%c's value is Greater\n",
Math.check(a, b));
}
}
再次有划分和抽象的范围。我们可以创建多个独立的文件来处理数字,在此示例中,我们可以划分
将代码分成较小的部分:
本程序可以分为以下几类:
1)主文件->驱动程序,在此处编写操作代码。
2)Math File->所有与数学有关的方法(此处为部分实现的Check 函数)。
示例程序包含:
数学。 Java >属于foo软件包,并且是一个Math类,该类由只能比较2个nos的方法check组成。排除不平等。
主要的。 Java > Main Program将2个数字作为输入并输出2中的较大者。
数学。Java
// Math.java
package foo;
public class Math {
public static int check(int a, int b)
{
return a > b ? 'A' : 'B';
}
}
主要的。Java
// Main.java
// Driver Program
package foo;
import java.util.*;
class Main {
public static void main(String args[])
{
Scanner s = new Scanner(System.in);
System.out.print("Enter value of a: ");
int a = s.nextInt();
System.out.print("Enter value of b: ");
int b = s.nextInt();
if (a == b)
System.out.println("Both Values are Equal");
else
System.out.printf("%c's value is Greater\n",
Math.check(a, b));
}
}
汇编:
javac -d /path file1.java file2.java 有时,您可能希望将类路径设置为指向某处,请使用:
set classpath= path/to/location
// (or) pass the switch for both java and javac as
javac -cp /path/to/location file.java
// (or)
java -classpath /path/to/location file
默认情况下,它指向当前目录,即“” 。 ”
执行代码:
java packagename.Main // Here in the example it is: “java foo.Main”
输出: 