- 词性(PoS)标记
- 词性(PoS)标记(1)
- 自然语言处理 |词性 - 默认标记
- z pos css (1)
- z pos css 代码示例
- PHP | pos()函数
- PHP | pos()函数(1)
- OpenNLP-查找词性(1)
- OpenNLP-查找词性
- C++基础(1)
- C++基础
- 强标记 (1)
- unity 在 x 秒内移动到 pos - C# (1)
- 基础 CSS 下拉基础
- 基础 CSS 下拉基础(1)
- Python中的 turtle.pos() 方法
- Python中的 turtle.pos() 方法(1)
- html中的标记标记(1)
- unity 在 x 秒内移动到 pos - C# 代码示例
- html代码示例中的标记标记
- Python基础(1)
- Python基础
- Sum(POS)的乘积(1)
- Sum(POS)的乘积
- Python|使用 spaCy 的 PoS 标记和词形还原(1)
- Python|使用 spaCy 的 PoS 标记和词形还原
- Python标记化(1)
- Python标记化
- 基础 CSS 按钮基础
📅 最后修改于: 2020-10-14 09:20:58 🧑 作者: Mango
什么是POS标记?
标记是一种分类,是标记描述的自动分配。我们称描述符s为“标记”,它代表语音的一部分(名词,动词,副词,形容词,代词,连词及其子类别),语义信息等。
另一方面,如果我们谈论词性(POS)标记,则可以将其定义为将单词列表形式的句子转换为元组列表的过程。在这里,元组的形式为(单词,标签)。我们还可以称呼POS标记为将词性之一分配给给定单词的过程。
下表代表Penn Treebank语料库中使用最频繁的POS通知-
| Sr.No | Tag | Description |
|---|---|---|
| 1 | NNP | Proper noun, singular |
| 2 | NNPS | Proper noun, plural |
| 3 | PDT | Pre determiner |
| 4 | POS | Possessive ending |
| 5 | PRP | Personal pronoun |
| 6 | PRP$ | Possessive pronoun |
| 7 | RB | Adverb |
| 8 | RBR | Adverb, comparative |
| 9 | RBS | Adverb, superlative |
| 10 | RP | Particle |
| 11 | SYM | Symbol (mathematical or scientific) |
| 12 | TO | to |
| 13 | UH | Interjection |
| 14 | VB | Verb, base form |
| 15 | VBD | Verb, past tense |
| 16 | VBG | Verb, gerund/present participle |
| 17 | VBN | Verb, past |
| 18 | WP | Wh-pronoun |
| 19 | WP$ | Possessive wh-pronoun |
| 20 | WRB | Wh-adverb |
| 21 | # | Pound sign |
| 22 | $ | Dollar sign |
| 23 | . | Sentence-final punctuation |
| 24 | , | Comma |
| 25 | : | Colon, semi-colon |
| 26 | ( | Left bracket character |
| 27 | ) | Right bracket character |
| 28 | “ | Straight double quote |
| 29 | ‘ | Left open single quote |
| 30 | “ | Left open double quote |
| 31 | ‘ | Right close single quote |
| 32 | “ | Right open double quote |
例
让我们通过Python实验来了解它-
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))
输出
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]
为什么要使用POS标记?
POS标记是NLP的重要组成部分,因为它是进行进一步NLP分析的前提,如下所示-
- 块状
- 语法解析
- 信息提取
- 机器翻译
- 情绪分析
- 语法分析和词义歧义消除
TaggerI-基类
所有标记器都驻留在NLTK的nltk.tag包中。这些标记器的基类是TaggerI ,意味着所有标记器都从此类继承。
方法-TaggerI类具有以下两个必须由其所有子类实现的方法-
-
tag()方法-顾名思义,此方法将单词列表作为输入,并返回已标记单词的列表作为输出。
-
validate()方法-借助此方法,我们可以评估标记器的准确性。
POS标记的基准
POS标记的基线或基本步骤是Default Tagging ,可以使用NLTK的DefaultTagger类执行此操作。默认标记只是将相同的POS标记分配给每个令牌。默认标记还提供了基准来衡量准确性的提高。
DefaultTagger类
默认标记是通过使用DefaultTagging类执行的,该类采用单个参数,即我们要应用的标记。
它是如何工作的?
如前所述,所有标记器都继承自TaggerI类。 DefaultTagger继承自SequentialBackoffTagger ,后者是TaggerI类的子类。让我们通过下图了解它-
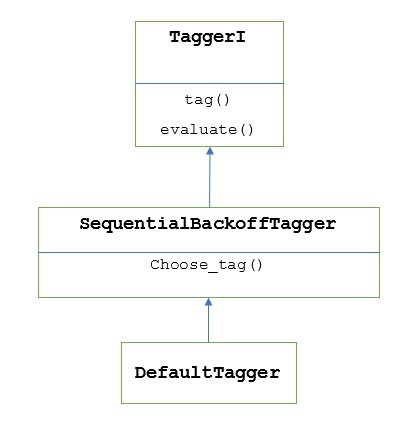
作为SeuentialBackoffTagger的一部分, DefaultTagger必须实现采用以下三个参数的choose_tag()方法。
- 代币列表
- 当前令牌的索引
- 先前令牌的列表,即历史记录
例
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])
输出
[('Tutorials', 'NN'), ('Point', 'NN')]
在此示例中,我们选择一个名词标签,因为它是最常见的单词类型。此外,当我们选择最常见的POS标签时, DefaultTagger也是最有用的。
准确性评估
DefaultTagger还是评估标记器准确性的基准。这就是我们可以将其与评估方法一起使用的原因。 validate()方法将标记标记的列表作为评估标记的黄金标准。
以下是一个示例,在该示例中,我们使用了上面创建的默认标记器exptagger来评估树库语料库标记的句子子集的准确性-
例
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)
输出
0.13198749536374715
上面显示的输出,通过选择NN为每个变量,我们可以实现对树库语料的1000个项目约13%的准确度测试。
标记句子列表
NLTK的TaggerI类不仅给单个句子加了标签,还为我们提供了一个tag_sents()方法,借助它我们可以标记一个句子列表。以下是我们标记两个简单句子的示例
例
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])
输出
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]
在上面的示例中,我们使用了先前创建的默认标记器exptagger 。
取消标记句子
我们还可以取消标记句子。 NLTK为此提供了nltk.tag.untag()方法。它将带标记的句子作为输入,并提供不带标记的单词列表。让我们看一个例子-
例
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])
输出
['Tutorials', 'Point']