AWS DynamoDB – 使用索引
索引是一种数据结构,它使我们能够对表中的不同列执行快速查询。创建索引后,数据库会为我们处理它。每当修改表中的数据时,都会自动修改索引以反映表中的更改。我们可以创建和使用二级索引来更快地查询。在创建二级索引时,我们必须指定它的键属性——分区键和排序键。二级索引创建后,我们就可以像对表一样进行Query或Scan等操作了。 DynamoDB 没有任何查询优化器,因此在查询或扫描时使用二级索引。 DynamoDB 支持两种类型的索引,下面将详细讨论:
全球二级指数:
全局二级索引 (GSI) 是一个具有分区键和排序键的索引,可以不同于基表中的键。全局二级索引被称为“全局”,因为对索引的查询可以覆盖基表中所有分区的所有数据。全局二级索引没有像基表那样的大小限制,并且有自己的预置读写吞吐量设置,这些设置与表的设置是分开的。因此,为了快速检索非关键属性的结果,我们使用二级全局索引。请参见以下示例:
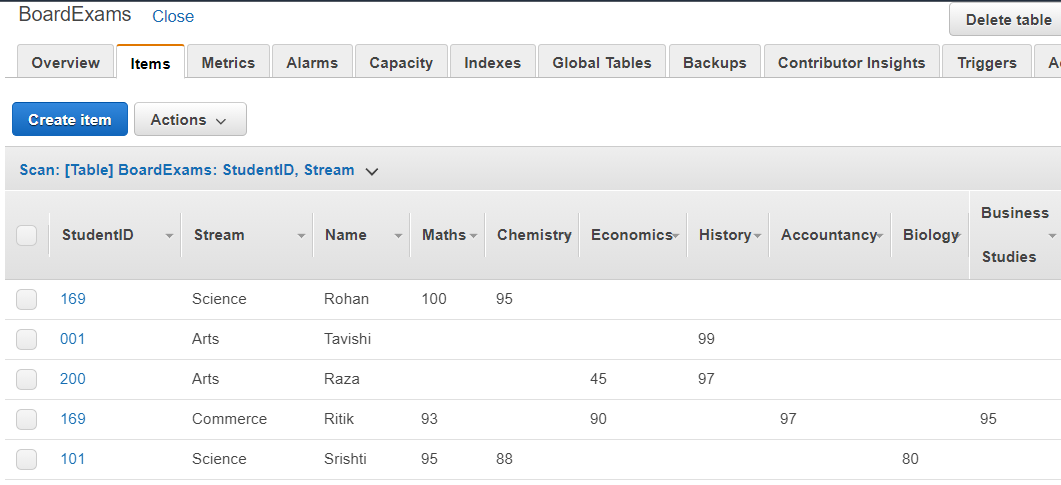
董事会考试
已创建名为BoardExams的表,分区键为StudentID ,排序键为 Stream。上表中存储的数据将如下图所示:
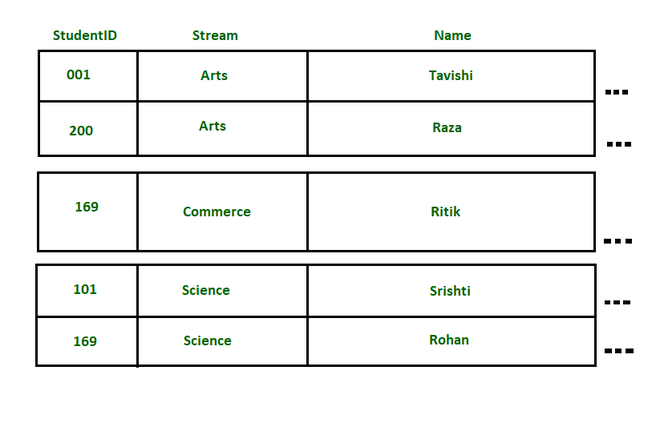
基表的表示
现在,假设我们需要知道每个流的数学分数。因此,我们创建了一个名为 St ream-index的 GSI,分区键为Stream ,排序键为Maths。见下图:
注意:基表的分区键也将被投影到索引中。
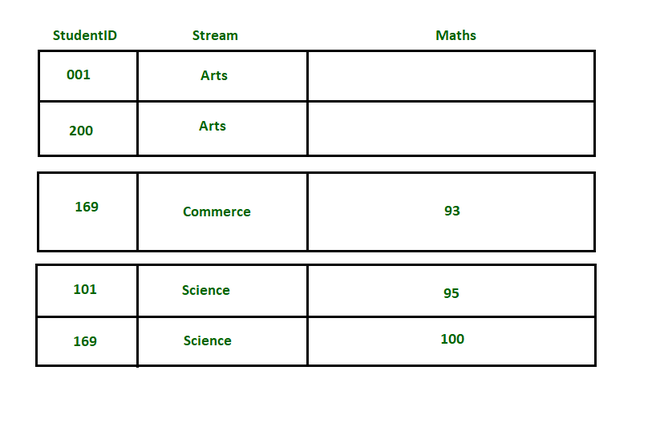
流索引
本地二级索引:
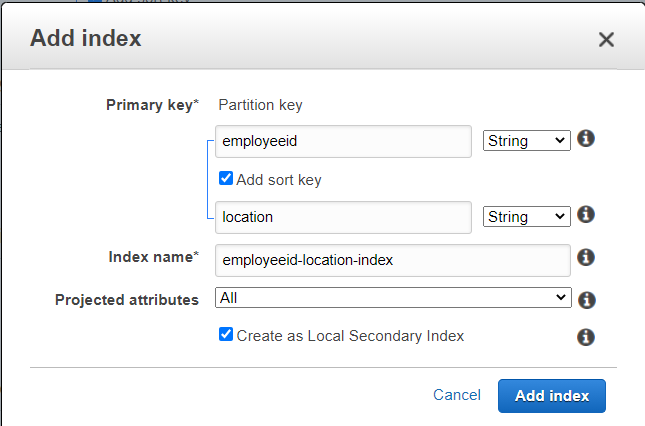
本地二级索引与基表具有相同的分区键,但排序键不同。它是“本地的”,因为本地二级索引的每个分区都被限定为具有相同分区键值的基表分区。它是在创建表时创建的。见下图: