AWS DynamoDB – 使用扫描
Amazon DynamoDB 是 NoSQL 托管数据库,用于存储半结构化数据,例如键值对和文档数据。在 DynamoDB 中创建表时,不需要架构结构,只需要分区键(主键)。 DynamoDB 表以项目的形式存储数据,每个项目都由键值对的属性组成。为了区分项目,定义了分区键。
Example:
{
"MovieID": 101,
"Name": "The Shawshank Redemption",
"Rating": 9.2,
"Year": 1994
}在本文中,我们将讨论如何扫描表中的项目。 Amazon DynamoDB 中的扫描操作会读取表中的每个项目。默认情况下,扫描操作会返回表中存在的所有项目。扫描总是返回一个结果集。如果没有找到匹配的记录,则结果集为空。在一次扫描操作中最多可以检索 1 MB。对于扫描数据项,我们有许多 Amazon DynamoDB 提供的功能。扫描数据项的方法如下:
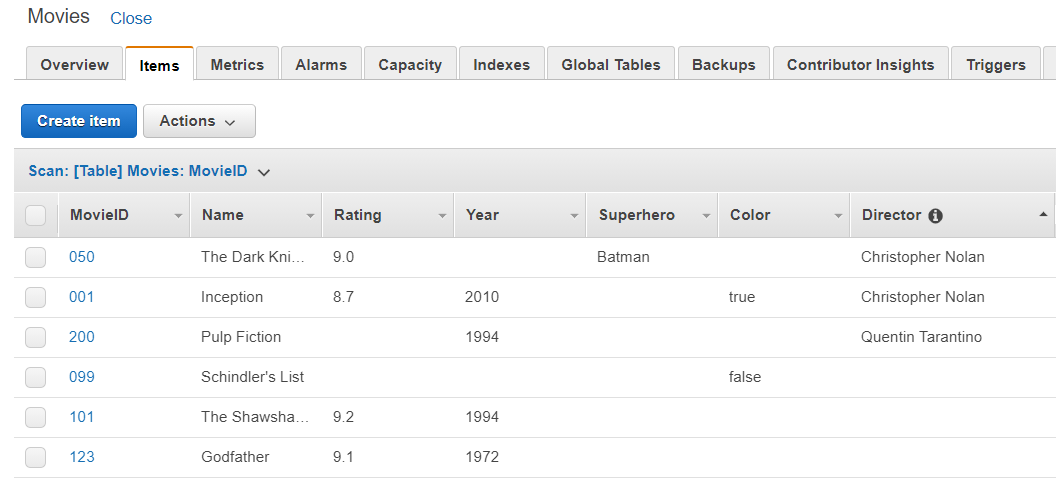
- 创建表并添加项目:要执行扫描,请在 Dynamodb 中创建一个表,例如,分区键为MoviesID的 Movies,然后在表中添加项目。见下图:
- 对数据执行扫描:为了扫描表中的数据,Dynamodb 提供了以下功能:
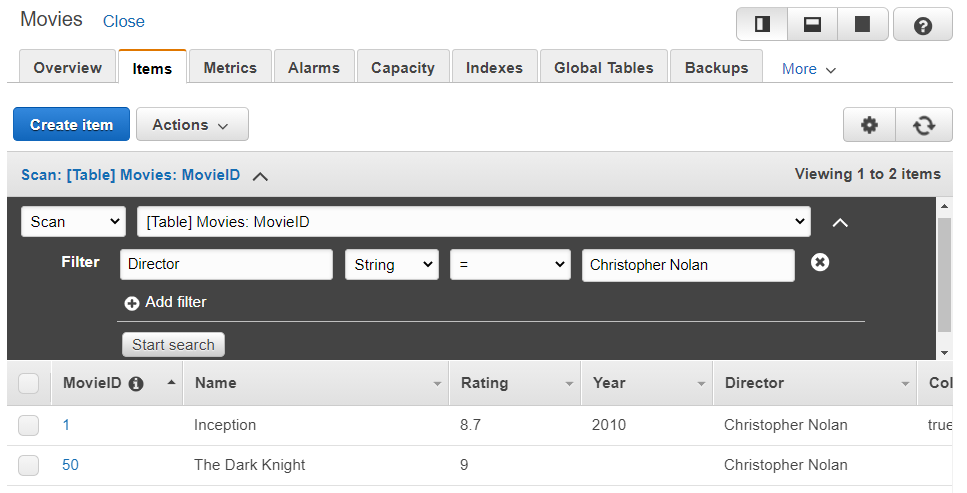
- 过滤器:为了优化我们的搜索,我们需要过滤器。如果没有提供过滤器,则打印所有数据。在过滤器中,我们指定一个属性,并通过它的值来获得结果。在下面的示例中,我们选择了属性“Director”并将其值选择为“Christopher Nolan”。见下图:
- 限制:扫描的另一个特点是限制。它限制了在结果中获得的项目数。该限制只能在 Amazon CLI(命令行界面)中使用。因此,在筛选表达式评估之前,将 limit 参数设置为要从扫描操作中检索的项目数。
- 分页:此功能只能在使用 Amazon CLI(命令行界面)时使用。当检索到的数据在结果集中超过 1 MB 时,则将结果分成页面,每个页面最多包含 1 MB。例如,如果检索到 2 MB 数据,则至少有 2 页。
- 消耗的容量单位:对于大小不超过 4 KB 的项目,读取容量单位表示每秒一次高度一致的读取,或每秒两次最终一致的读取。扫描操作不会返回有关所消耗的读取容量单位的任何数据。但是,您可以在 Scan 请求中指定ReturnConsumedCapacity参数以获取此信息或在表的容量选项卡中更改读取容量单位。见下图:

- 读取一致性:默认情况下,扫描操作执行最终一致性读取。这意味着,由于最近完成的PutItem或UpdateItem请求,扫描结果可能不包括更改。如果需要强一致性读取,则在 Scan 开始时,在 Scan 请求中将ConsistentRead参数设置为 true。通过这样做,它可以确保在 Scan 开始之前完成的所有写入操作都包含在 Scan 结果集中。
- 并行扫描:扫描操作在逻辑上将表或二级索引划分为多个段,每个段由多个应用程序并行扫描。每个工作者都可以是一个操作系统进程或一个线程(在支持多线程的编程语言中)。