熊猫内存管理
在本文中,我们将了解 pandas 中的内存管理。
毫无疑问,当我们与 pandas 合作时,您将始终存储大数据以进行更好的分析。在处理更大的数据时,我们应该更关心我们使用的内存。处理小型数据集时没有问题。它不会引起任何问题。但是我们可以在不处理更大数据集中的内存问题的情况下进行编程。
现在我们将了解如何减少错误和内存消耗。它通过加快计算速度使我们的工作更轻松。
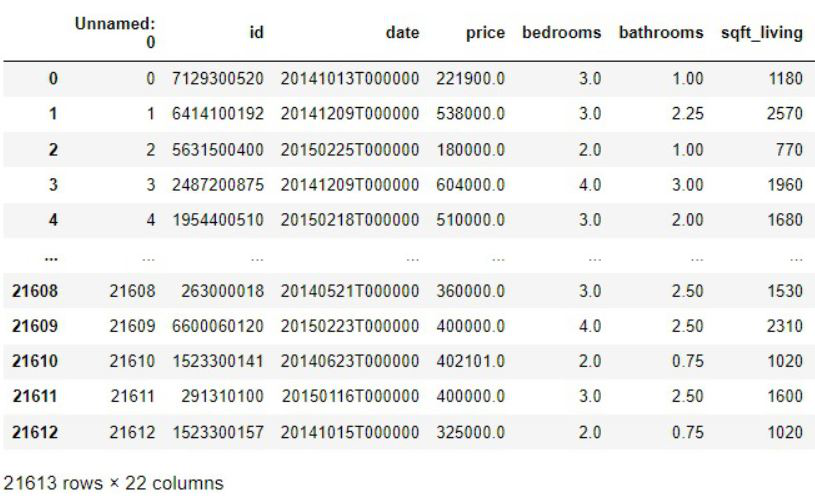
查找内存使用情况
信息():
Info() 方法返回数据框的摘要。
syntax: DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, show_counts=None, null_counts=None)
这将打印出数据框的简短摘要。当我们提到它作为参数时,它也会给出数据帧占用的内存使用情况。对于参数,我们应该将 memory_usage 称为“深度”。
Python3
import pandas as pd
df = pd.read_csv(data.csv)
df.info(memory_usage="deep")Python3
import pandas as pd
df = pd.read_csv(data.csv)
df.memory_usage()Python3
import pandas as pd
df = pd.read_csv('data.csv')
# Downcasting float64 to float16
df['price'].memory_usage()
df['price'] = df['price'].astype('float16')
df['price'].memory_usage()Python3
df.info(verbose = False, memory_usage = 'deep')
df = df[['price', 'sqft_living]]
df.info(verbose = False, memory_usage = 'deep')Python3
# importing the modules
import pandas as pd
import numpy
# Reading the csv file
df = pd.read_csv('data.csv')
# Deleting unwanted columns
del df["Unnamed: 0"]Python3
# importing the modules
import pandas
import numpy
# Reading the csv file
df = pd.read_csv('data.csv')
# Memory usage before replacing
df['bedrooms'].memory_usage()
# output--> 314640
# Replacing the categorical values
df['bedrooms'].replace('more than 2', 1, inplace=True)
df['bedrooms'].replace('less than 2', 0, inplace=True)
# Memory usage after replacing
df['bedrooms'].memory_usage()
# output--> 173032Python3
# importing the mmodule
import pandas
# Reading the data in chunks
data = pandas.read_csv('data.csv', chunksize=1000)
# Concatenating the chunks together
df = pandas.concat(data)输出:
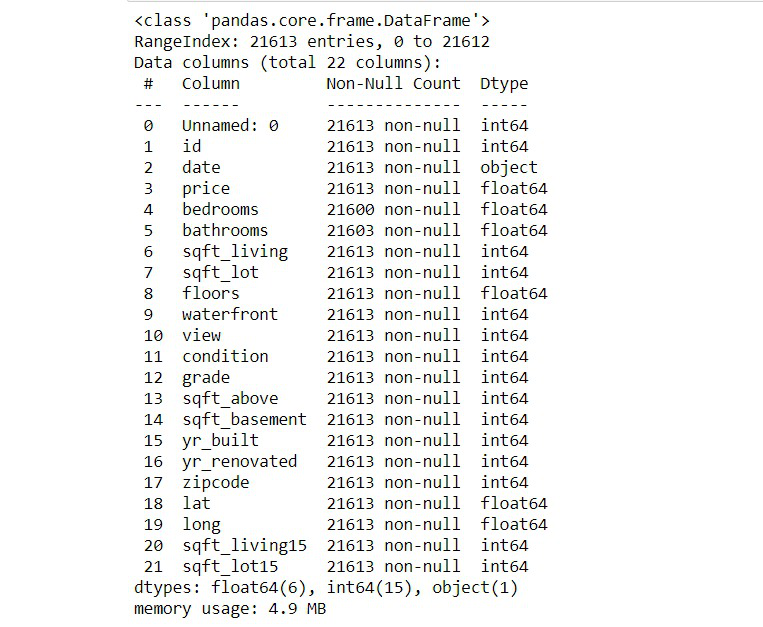
内存使用情况():
Pandas memory_usage()函数返回索引的内存使用情况。它返回索引中存在的所有单个标签使用的内存总和。
Syntax: DataFrame.memory_usage(index=True, deep=False)
但是,Info() 仅给出数据使用的整体内存。此函数以字节为单位返回每列的内存使用情况。在数据框中查找哪一列使用更多内存可能是一种更有效的方法。
Python3
import pandas as pd
df = pd.read_csv(data.csv)
df.memory_usage()
输出:
在 Pandas 中优化内存的方法
将数字列更改为更小的 dtype:
这是保存程序使用的内存的一种非常简单的方法。 Pandas 默认将整数值存储为 int64,浮点值存储为 float64。这实际上需要更多的内存。相反,我们可以向下转换数据类型。只需将 int64 值转换为 int8 并将 float64 转换为 float8。这将减少内存使用量。通过不折不扣地转换数据类型,我们可以直接将内存使用量减少到近一半。
Syntax: columnName.astype(‘float16’)
Note: You cannt store every value under int16 or float16. Some larger numbers still need to be stored as a larger datatype
代码:
Python3
import pandas as pd
df = pd.read_csv('data.csv')
# Downcasting float64 to float16
df['price'].memory_usage()
df['price'] = df['price'].astype('float16')
df['price'].memory_usage()
输出:
173032
43354停止加载整个列
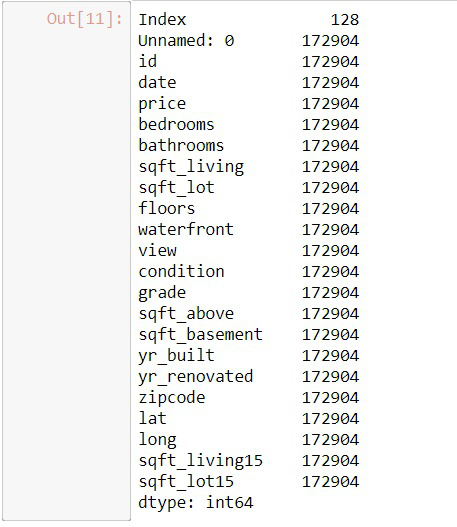
我们通常使用较大的数据集,但不需要加载整个数据集。相反,我们可以加载您要处理的特定列。通过这样做,我们可以将消耗的内存量限制在一个非常低的值。
为此,只需形成一个临时数据集,其中仅包含您要处理的值。
Python3
df.info(verbose = False, memory_usage = 'deep')
df = df[['price', 'sqft_living]]
df.info(verbose = False, memory_usage = 'deep')
输出:
RangeIndex: 21613 entries, 0 to 21612
Columns: 22 entries, Unnamed: 0 to sqft_lot15
dtypes: float16(1), float64(5), int64(15), object(1)
memory usage: 4.8 MB
RangeIndex: 21613 entries, 0 to 21612
Columns: 2 entries, price to sqft_living
dtypes: float16(1), int64(1)
memory usage: 211.2 KB 在上面的示例中,我们可以清楚地看到将特定列加载到数据框中会减少内存使用量。
删除
删除是节省空间的方法之一。对于任何内存问题,这可能是最好的解决方案。我们可能在不知不觉中保存了许多用于训练和测试的数据帧,这些数据帧在此过程中进一步没有使用。我们还可以删除未使用的列。通过删除这些可以节省更多空间。我们还可以删除数据框中存在的空列,这也可以节省更多空间。我们可以使用 del 关键字,后跟要删除的项目。这应该删除该项目。
Python3
# importing the modules
import pandas as pd
import numpy
# Reading the csv file
df = pd.read_csv('data.csv')
# Deleting unwanted columns
del df["Unnamed: 0"]

更改分类列
在处理一些数据集时,我们可能有一些分类列,其中整列只包含一组固定的重复值。这种类型的数据称为分类值,它们基本上是分类或组,其中一大组行具有相似的分类值。在处理这些类型的数据时,我们可以简单地将每个分类值分配给某个字母或整数[基本上是编码]。这种方法可以成倍地减少程序使用的内存量。
syntax: df[‘column_name’].replace(‘largerValue’, ‘alphabet’, inplace=True)
Python3
# importing the modules
import pandas
import numpy
# Reading the csv file
df = pd.read_csv('data.csv')
# Memory usage before replacing
df['bedrooms'].memory_usage()
# output--> 314640
# Replacing the categorical values
df['bedrooms'].replace('more than 2', 1, inplace=True)
df['bedrooms'].replace('less than 2', 0, inplace=True)
# Memory usage after replacing
df['bedrooms'].memory_usage()
# output--> 173032
输出:
314640
173032将列卧室的分类值替换为 1 和 0 后,您可以看到内存使用量减少了一半。
分块导入数据
在处理数据时,很明显在某些情况下我们需要处理通常以千兆字节为单位的大数据。您的机器可能负载了计算能力,即内存可以一次将所有这些数据加载到内存中,这几乎是不可能的。在这种情况下,pandas 有一个非常方便的方法来分块加载数据,这基本上可以帮助我们遍历数据集并分块加载,而不是一次加载所有数据并将您的机器推向极限。
为此,我们需要在读取数据时传递名为块大小的参数。这将为我们提供需要连接成完整数据集的大量数据。这样,我们可以一下子减少机器的内存使用量。并花一些时间来恢复其计算能力以处理流程。
syntax: pandas.read_csv(‘fileName.csv’, chunksize=1000)
此方法将返回数据集的可迭代对象。
Python3
# importing the mmodule
import pandas
# Reading the data in chunks
data = pandas.read_csv('data.csv', chunksize=1000)
# Concatenating the chunks together
df = pandas.concat(data)
输出: